非線形薬物の血中濃度解析② numpyを使用した回帰

今回から非線形薬物の血中濃度解析に使用できるプログラムのコードを実際に書いていきましょう!
設計図:解析の流れ
前回の投稿で非線形薬物について復習しました。不安な方は前回の投稿を見返しながら読み進めてください。
解析を行うためには、KmとVmaxの定数を知る必要がありそうです。この2つの定数は、投与量が異なる2点の採血データをLineweaver-Burkプロットを用いて直線回帰することで算出できました。従って、採血データを入力し、データの直線回帰からy切片と傾きを求めKmとVmaxを算出するところから始まります。
定数さえ分かれば、Michaelis–Menten式を血中濃度についてまとめた式([S] = (Km・V)/(Vmax-V))に任意の投与量を代入し血中濃度を計算します。最後に、投与量と血中濃度をプロットし、投与量と血中濃度の関係を示した曲線をグラフ化します。
ということで、以下の流れでパーツを作成していきます。
データ入力
Lineweaver-Burkプロット(直線回帰)
任意の投与量から血中濃度を計算
可視化(グラフ化)
1. データ入力
投与量と血中濃度は次のステップで直線回帰を行うので、それぞれリストに格納しておくと便利です。採血ポイントがいくつあるかによって、入力する回数が変化するので、採血ポイントがいくつあるかを最初に入力しておくとよいかもしれません。
num = int(input('採血ポイント数:'))numという変数に採血ポイント数が代入されるので、あとはnum回分の投与量と血中濃度の入力を繰り返し、入力値をリストに格納していけば良さそうです。
# 空のリストを準備
dose_list = []
conc_list = []
# データ入力
for i in range(num):
dose = float(input('投与量:'))
conc = float(input('血中濃度:'))
dose_list.append(dose)
conc_list.append(conc)input()を用いて投与量はdose、血中濃度はconcという変数に浮動小数点型のデータとして代入し、それぞれを最初に準備したリストに追加(apend())していきます。
サンプルデータとして、
①投与量:400(mg/d) 血中濃度:5.6(μg/mL)
②投与量:200(mg/d) 血中濃度:0.9(μg/mL)
③投与量:250(mg/d) 血中濃度:1.4(μg/mL) を使用します。
実際にコードを実行し上記データを入力してみてください。確認のためリストの中身を表示してみましょう。
print(dose_list)
print(conc_list)dose_listとして[400.0, 200.0, 250.0]、conc_listとして [5.6, 0.9, 1.4]が出力されます。
Lineweaver-Burkプロットでは、投与量と血中濃度の逆数を直線回帰するので、回帰用に逆数を格納するリストも作成しておきます。
num = int(input('採血ポイント数:'))
# 空のリストを準備
dose_list = []
conc_list = []
x = [] #doseの逆数を格納するリスト
y = [] #concの逆数を格納するリスト
# データ入力
for i in range(num):
dose = float(input('投与量:'))
conc = float(input('血中濃度:'))
dose_list.append(dose)
conc_list.append(conc)
x.append(1/conc)
y.append(1/dose)先程と同じサンプルデータを入力して、逆数を格納したリストも確認してみましょう。
print(x)
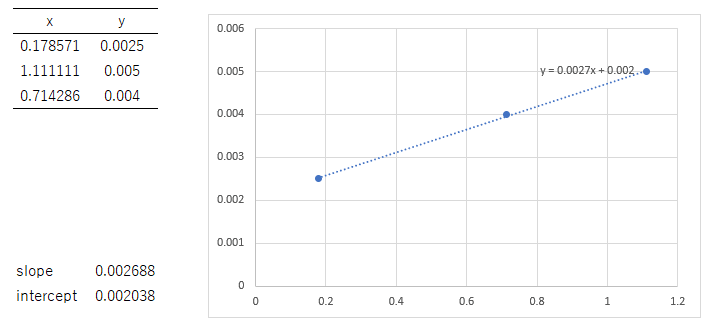
print(y)xには[0.17857142857142858, 1.1111111111111112, 0.7142857142857143]、yには[0.0025, 0.005, 0.004]が格納されています。
2. Lineweaver-Burkプロット(直線回帰)
Km・Vmaxの計算
直線回帰を行う場合、Excelでは散布図を作成し、近似曲線を追加しグラフに数式を表示して傾きと切片を求めている人が多い印象です。少し慣れた方は、散布図は作らずslope関数(=slope(y, x))とintercept関数(=intercept(y, x))を使用し、直接傾きと切片を計算していると思います。
Pythonでも後者のように計算から傾きや切片を求める方法があり、効率的にこのような数値計算を行うライブラリとしてnumpyがあります。初めて使用する場合は、numpyをインストールする必要があります。
!pip install numpyインストール終了後、importすればnumpyを使用できます。ここでは、npと省略した形で使用できるように宣言しています。
import numpy as npnumpyのpolyfit()メソッドを使用することで簡単に傾きと切片を求めることが出来ます。第一引数にx値、第二引数にy値、第三引数に回帰式の次数(直線回帰=1次式なので”1”)を入れることで、回帰式の係数がリストとして返ります。次数に1を入れると、回帰式は「y=ax+b」という式になるため、戻り値は係数a(傾き)と係数b(切片)を含むリストになります。
変数xと変数yにそれぞれ投与量の逆数、血中濃度の逆数がリストとして代入されているので、以下のように記述するだけで傾きと切片の計算が出来てしまいます!
np.polyfit(x, y, 1)>array([0.0026876 , 0.00203805])
Excelで計算した値と同じ値を得ることが出来ました。このままでも良いですが、分かりやすくするために各値を別の変数に入れておきます。戻り値は係数aと係数bの2つなので、変数を2つ用意すればそれぞれを格納することが出来ます。
slope, intercept = np.polyfit(x, y, 1)
print(slope)
print(intercept)>0.0026875973636908334
0.0020380467345715992
傾きと切片をslopeとinterceptという変数に入れることが出来ました。
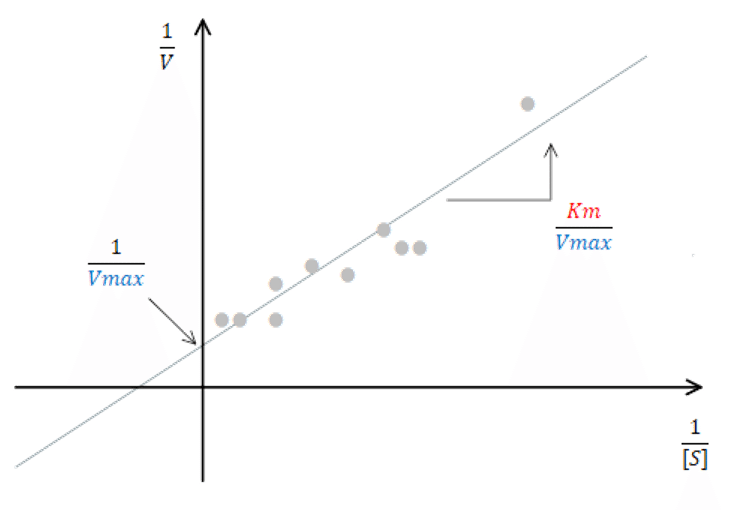
Lineweaver-Burkプロットでは、切片が1/Vmax、傾きがKm/Vmaxですので、ここから簡単にVmaxとKmを計算することが出来ます。
Vmax = 1/intercept
Km = slope * Vmax
print(Vmax)
print(Km)>490.66588269880947
1.318712332794356
これでVmaxとKmを求めることが出来ました。
ここまでのコードをまとめると以下のようになります。
import numpy as np
num = int(input('採血ポイント数:'))
y = []
x = []
dose_list = []
conc_list = []
for i in range(num):
dose = float(input('投与量:'))
conc = float(input('血中濃度:'))
dose_list.append(dose)
conc_list.append(conc)
y.append(1/dose)
x.append(1/conc)
slope, intercept = np.polyfit(x, y, 1)
Vmax = 1/intercept
Km = slope * Vmax注意点
この解析には2点以上の採血が必要ですが、複数の採血点をとる中でクリアランス自体が変化してしまうことがあります。例えば、非線形薬物のボリコナゾールは主にCYP2C19で代謝されますが、炎症反応高値の際にダウンレギュレーションが起こり代謝能が低下するようです。このような場合、炎症高値とそうでない状態の2点があるとLineweaver-Burkプロットの傾きが負の値をとることもあります。そうなると解析不能となってしまうので、解析する上でKmやVmaxが正の値である必要があります。
そこで、Km > 0 かつ Vmax > 0 のとき先に進めるような条件分岐を付けた方が良いのかもしれませんが、今回の解説の中では簡略化のため省略しています。
バンコマイシンなどのTDMソフトもそうですが、計算値やシミュレーション値はあくまでプログラムされた計算の結果を返しているだけです。これらはツールとして正しく使用し、その結果をどう解釈し治療に活かすかが薬剤師の腕の見せ所だと思います。
というわけで、このコードを臨床で使用する際は、自己責任でお願いします。
今回はここまでです。次回もお楽しみに!
この記事が気に入ったらサポートをしてみませんか?