
便利ライブラリ seaborn① Heatmap作成

これまでデータの可視化用のライブラリとしてaltairやmatplotlibを紹介してきました。matplotlibは細かい設定ができる反面、たくさんあり過ぎて分かりにくいという印象もあります(ただ慣れてないだけかもしれませんが…)。今回紹介するseabornは、より少ないコードで、より洗練された可視化ができるライブラリです。
特に、Excelでは作成しにくいHeatmapも簡単に作れるので、データの全体像をイメージしたいときなどによく使っています。
基本情報
seabornの公式ドキュメントは以下を参照してください。
ページ内検索で「heatmap」で検索し、heatmapのページを探します。そこを参照すると、
seaborn.heatmap(data, *, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)
とあります。そうなんです、seaborn.heatmap()だけでheatmapが描けてしまいます!よく使う引数は以下の通りです。
data:二次元データセット(例えばピボットテーブルのようにクロス集計したデータなど)
vmin/vmax:カラーバーの最小値/最大値
cmap:色の設定(matplotlib colormap)
annot:Trueを渡すと各セルにデータの値を書き込むことができる
fmt:annotを追加する際に使用する文字列フォーマットコード
コードを書く前に、他のライブラリと同様にpipインストールします。
pip install seabornデータの準備・整形
引数dataは、クロス集計したデータということで今回は以下のようなサンプルデータを使用します。同じような適当なデータをご用意ください。
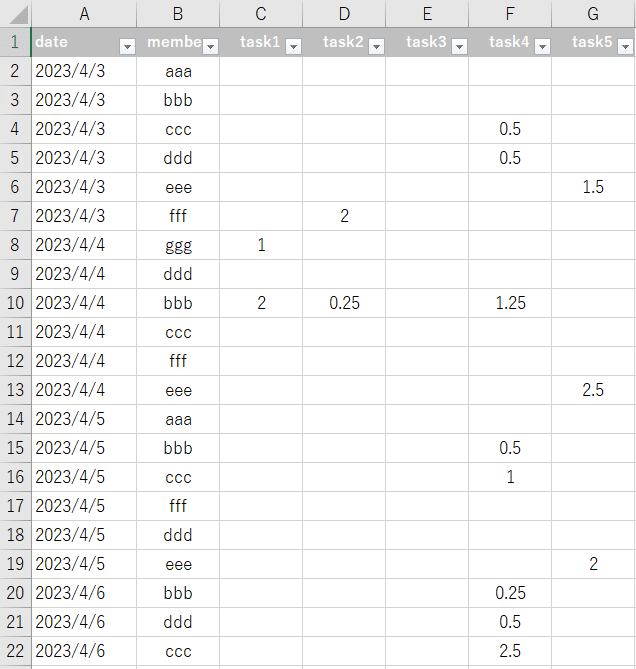
中身は業務日報ですね。日付と担当者のデータがあり、各taskにどれだけの時間を要したか入力されています。Excelのファイル名は、sampleData.xlsxとなっています。
必要なライブラリのをimportします。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsデータを読み込み、DataFrameを作成します。
df = pd.read_excel('sampleData.xlsx')月ごとの各taskの合計時間をpivot_tableを使用して集計します。dateが入った列から、年月のデータを再構築します。
yyyymm = []
for i in range(len(df)):
ym = df.iloc[i, 0].strftime('%Y.%m')
yyyymm.append(ym)
df['month'] = yyyymm0列目のデータ(date)をfor文とiloc[]を用いて1つずつ取り出し、strftime()を使って文字列フォーマットの時間データに変換し、append()でリストに格納しています。このとき、yyyy.mmとなるように加工しています。dfに新たにmonthという列を作成し、作成したリストのデータを代入しています。

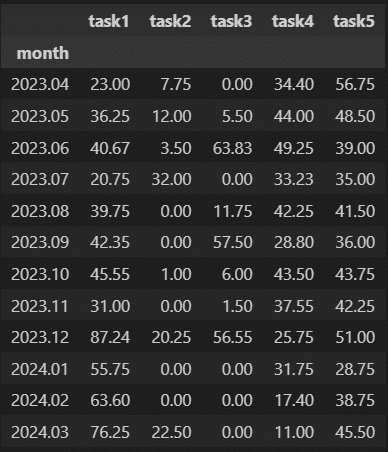
month列を用いてクロス集計すれば月ごとのデータを得ることができます。pivot_table()の引数でaggfunc='sum'とするとデータの合計が計算されます。
df_pivot = pd.pivot_table(data=df,
index='month',
values=['task1', 'task2', 'task3', 'task4', 'task5'],
aggfunc='sum'
)
heatmapの作成
df_pivotを用いてheartmapを作成します。
今回は、cmap='Blues'として青色の濃淡で表現します。heatmap自体をaxという変数に格納し、ax.xaxis.tick_top()とすることでx軸ラベルを上方に配置することができます。
plt.figure(figsize=(8, 6))
ax = sns.heatmap(df_pivot, annot=True, fmt='g', cmap='Blues', vmax=90, vmin=0)
ax.xaxis.tick_top()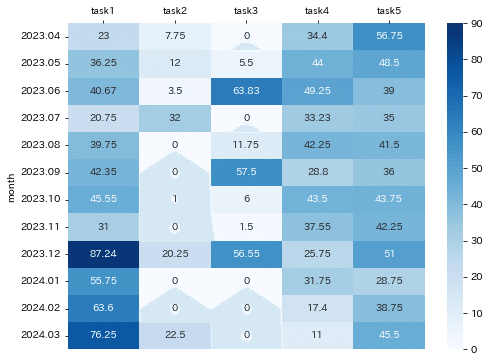
heatmapを作成することができました。クロス集計は日常業務でも多用しますが、数字の羅列だけでは読み取りにくい大小関係がイメージしやすくなります。
task5のように大きな変動がない業務もあれば、task2や3のように周期性がある業務、task4のように徐々に減っている業務、task1のように徐々に要する時間が増えている業務が一目瞭然です。
データの整形する過程はありますが、heatmap自体は実質1行で描けるのでよく使用しています。
おまけ(考察とさらなる分析)
どのような傾向があるか把握し、問題があればその対策を考えるのがデータの可視化の目的の一つです。
例えば、task1が12月あたりから増えて高い水準で推移しています。このようになっている原因を探る必要がありそうです。
薬剤師の仕事(の一部)は、処方箋の枚数に依存することがあります。その処方を出す医師は外来の曜日が決まっていることが多く、曜日という要素は割と大きいのかもしれません。dfに曜日の情報も付加して分析してみます(この”df”は先程の続きで、既にmonth列が付加されています)。
weekdays = []
for i in range(len(df)):
wd = df.iloc[i, 0].weekday()
if wd == 0:
weekdays.append('Mon')
elif wd == 1:
weekdays.append('Tue')
elif wd == 2:
weekdays.append('Wed')
elif wd == 3:
weekdays.append('Thu')
elif wd == 4:
weekdays.append('Fri')
df['weekday'] = weekdaysmonth列を作成したコードとほぼ同じです。日付データに対してweekday()を用いることで曜日を取得することができます。月曜日は0、火曜日は1というように曜日に対応した数字が返ってくるため、if文で数字に応じた文字列に置き換えてリストにしています。
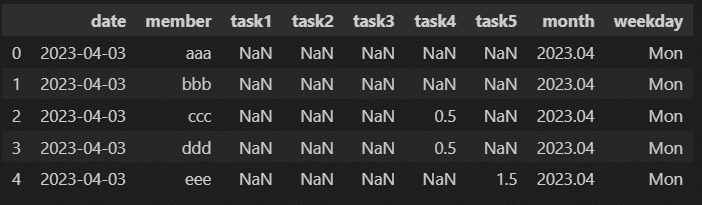
あとは先程と同様にクロス集計し、heatmapを作成します。
df_pivot2 = pd.pivot_table(
data=df,
index='month',
columns='weekday',
values='task1',
aggfunc='sum'
)
df_pivot2 = df_pivot2['Mon', 'Tue', 'Wed', 'Thu', 'Fri'] #曜日順になるよう並び替えplt.figure(figsize=(8, 6))
ax = sns.heatmap(df_pivot2, annot=True, fmt='g', cmap='Blues', vmax=25, vmin=0)
ax.xaxis.tick_top()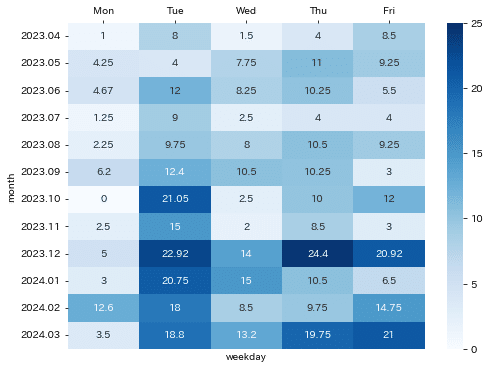
どうやら火曜日はコンスタントに多くなり、木・金曜日は周期性があります。火曜日の増加は10月から始まっていたようです。
10月に何か変化があったかなぁ…と考えていくと原因に近付けるかもしれません。原因が特定されなかったとしても、せめて火曜日だけでもtask1を処理するための人員を充てる必要が出てきそうですね。
一見難しそうですが、割と簡単にheatmapが作成できました。一度コードを作成してしまえば、「生データを加工→クロス集計→heatmap作成」の過程(コード)は変わらないので一瞬でheatmapまで完成します。継続的に経過を追う必要がでてきても楽勝です!
この記事が気に入ったらサポートをしてみませんか?