
環境構築はいつも面倒だ#06: Teradata用のJupyter Lab拡張機能ウォークスルー

Teradata SQL KernelというJupyter Labの拡張機能を動かしてみます。インストールがまだの方は、このマガジンの先行記事をご覧ください。おそらくちょっとした探索的分析の道のりは、PythonやRと同様にTeradata SQL Kernelのノートブックで残していけるはずです
拡張機能1: Connection
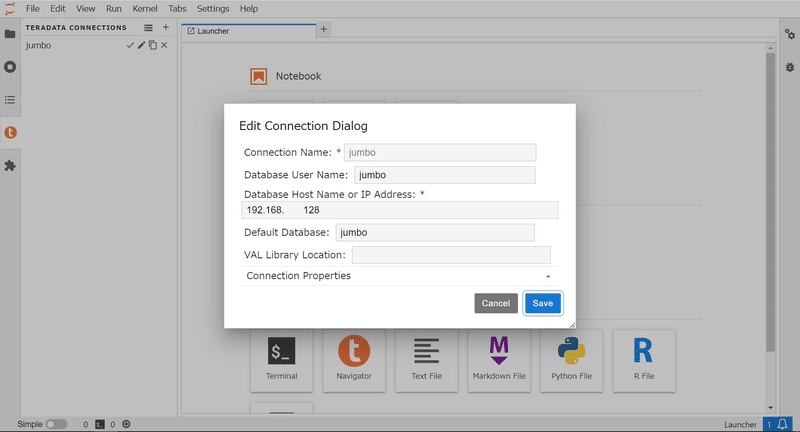
最初にご紹介するのはTeradataへの接続情報の設定に関する拡張機能です。Jupyter Labを起動すると、左端にフォルダーアイコンなどと合わせてオレンジ色の丸に白字のtアイコンがあるかと思います。これをクリックすると、通常フォルダとノードブックなどのファイル一覧が表示されるスペースに[TERADATA CONNECTIONS]と題したスペースが表示され、その横に+アイコンが表示されます。別途Teradataがどこかで起動している状態で、これをクリックすると、以下画像のようなポップアップが表示されます(Edit Connection Dialog)。ここに以下の情報をセットします:
Connection Name: お好きなものを
Databaser User Name: Teradataへの接続ユーザー名を
Database Host Name or IP Address: サーバー名もしくはIPアドレスを
Default Database: 接続先のデフォルトデータベースを
そのほかのフィールドは何も指定しなくて大丈夫です。[Save]をクリックすると保存され、[TERADATA CONNECTIONS]と題したスペースに追加されます。この接続情報を、あとあと呼び出して接続に利用することができるようになります。もちろん複数追加可能です
拡張機能2: Navigator
ランチャーの画面にはTeradata SQL Kernelのノートブックを呼び出す画面上側のtアイコンと、画面下側にある[Navigator]と記載されたtアイコンがあります。[Navigator]アイコンのほうをクリックして、上述の接続情報(今回の例ではjumbo)を選択すると、以下画像のように表示されます。接続したTeradataデータベース内のテーブルやその中の列、ビューといったオブジェクトを閲覧できるようになっています。テーブルアイコンを右クリックにより、画像のように右クリックで下側にサンプルデータを表示させて、テーブルの中身を確認することも可能です

SQLを実行してみる
Teradata SQLのノートブックアイコンをクリックすると、空のノートブックが開きます。以下に作成済みのノートブックを貼りましたので、まずはそちらをご覧いただきます
操作は簡単で、%connectというマジックコマンドで、先ほどの接続情報(jumbo)を呼び出し、パスワードを入力して接続します。その後はセルにSQLを書き込んでEnter+ShiftするとSQLが実行され、Select文であれば結果が表示されます。権限さえあればSelect文だけでなく、Insert、Update、Delete、Drop、Createも同様に実行できます。またその結果はCSVでJupyter Labの管理する環境下にもダウンロードされており、好きに取り出すことが可能です。通常のWindowsにおけるPython / Jupyter Lab環境だと以下のディレクトリにタイムスタンプ付きのフォルダがあり、これがそれぞれの結果セットを意味します。ディレクトリ内のCSVファイルが結果データそのものです
C:\Users\yourusername\Teradata\Resultsets\2023.09.04_22.43.14.986_JST
データロード関連の機能
これも難しい話はなく、上述のノートブックに記載の通りです。%dataloadを宣言し、あらかじめ作成したテーブルとそれが存在しているデータベース、ローカルのロード対象CSVファイルを指定し、CSVファイルの一番上の行が列名であればスキップの指定をしてあげます。そしてEnter+Shiftでロードしてくれます。ファイルはUTF-8です。対象ファイルのパスは、上述の結果セットのディレクトリと同じく、ホームディレクトリが、C:\Users\yourusernameで、CSVがC:\Users\yourusername\datにあるなら、ノートブックのようにdat/csvname.csvで指定してあげます
可視化関連の機能
%historyで今までのSelect文による結果をリスト表示できます。ここで表示されるHistory IDを利用し、またVega / Vega-Liteという内蔵されている可視化ライブラリを利用して、簡単なグラフ表示を行うことが可能です。%chartでグラフ表示の宣言を行い、History IDにて指定した番号のCSVファイルをデータとして利用して可視化します。書き方はパラメーターのKey=値,という記述を重ねて指定していく書き方のようです。細かい指定方法は%help chartにてご確認ください。なお、可視化だけでなく、データロードやそれ以外の操作も含めたヘルプを%helpで参照できます。一応ノートブックにも含めましたが都度参照する際には%helpで参照ください。
それから、可視化の表示設定情報自体はJSONファイルにまとめて、それを表示させることも可能です。以下の記事でその方法を使っているのでご参考にしていただければ幸いでございます
こちらからは以上です
#teradata #teradatasqlkernel #jupyterlab #vega #vegalite
///
この記事が気に入ったらサポートをしてみませんか?