
MeCabで遊んでみる。すぐ使えるコードあり。

某IT企業の新米SEのYUHです。データサイエンティストを目指してます。
データ分析の勉強をしようと思い、Pythonの環境構築をしてみた。
前回はJupyterの最低限の操作方法を確認したので、今回はJupyterでMeCabを使って遊んでみることにしてみました。
概要
MeCabとは
ワカメの付着器の上にある、葉状部の中で厚く折り重なってひだ状になった部分である...
...ではなく、
オープンソースの形態素解析エンジン。自然言語のテキストデータから、言語で意味を持つ最小単位のワードに分割ができる。
手順の5Step
1. MeCabのダウンロード
2. MeCabのインストール
3. 環境変数への登録
4. mecab-pythonの導入
3. プログラム実行
手順
1. MeCabのダウンロード
公式の32bit版ではなく、有志がビルドした64bit版をダウンロードする。

2. MeCabのインストール
ダウンロード先のフォルダのexeファイルを起動する。
インストーラが起動したら、「次へ」を押す。
「インストール」を押す。

「完了」を押す。
3. 環境変数への登録
インストールが終わったら、メニューバーから
「コントロールパネル」→「システム」→「システムの詳細設定」→上部の「詳細設定」タブ→「環境変数」→○○のユーザ環境変数→「Path」を選択し、「編集」を押す。
インストールしたbinフォルダを入力し、「OK」

4. mecab-pythonの導入
Windowsマークを押し、メニューバーまたは検索からAnaconda Promptを起動する。
起動したら、以下のコードを入力し、実行する。
> pip install ipykernel
> pip install mecab-python-windows導入が完了したら、確認してみる。Anaconda Promptに以下を入力する。
> python> import MeCab
> m = MeCab.Tagger()
> print(m.parse("すもももももももものうち"))このような結果になったらOK
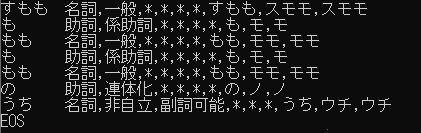
最後は、以下のコードを入力し終了。
> exit()5. プログラムの実行
MeCabで形態素解析する
青空文庫で公開されている夏目漱石の長編小説『吾輩は猫である』をテキストファイルに整形したものをダウンロードして使用する。
#MeCab使うためのおまじない
import MeCab
m = MeCab.Tagger()
infile_name = 'neko.txt'
outfile_name = 'neko.txt.mecab'
#元ファイルを読み込み
with open(infile_name, encoding = 'utf-8') as infile:
file = infile.read()
#分かち書きファイルを書き込み
with open(outfile_name, mode = 'w', encoding = 'utf-8') as outfile:
#分かち書き
outfile.write(m.parse(file))
形態素解析出力結果は、以下のようになっている。
表層形\t品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音この出力結果をリストとして格納し、簡単に使用できるようにする。
#分かち書き結果をリストとして格納
with open('outfile_name', encoding = 'utf-8') as infile:
nekos = []
for i, line in enumerate(infile):
elems = line.split('\t') #...1
if len(elems) > 1:
elem = elems[1].split(',') #...2
nekos.append({
'surface' : elems[0],
'pos' : elem[0],
'pos1' : elem[1],
'pos2' : elem[2],
'pos3' : elem[3],
'util1' : elem[4],
'util2' : elem[5],
'base' : elem[6],
'read' : elem[7],
'pronu' : elem[8]
})#...1と#...2はこういうイメージで区切る

おまけ
こんなことができる
#動詞の原形をすべて抽出
verb_org = []
for i, line in enumerate(nekos):
if nekos[i]['pos'] == '動詞':
verb_org.append(nekos[i]['base'])
for i in range(5):
print(verb_org[i])#単語の出現頻度を求め、出現頻度の高い順に並べる
from collections import Counter
word = [ nekos[i]['surface'] for i in range(len(nekos)) ]
cnt = Counter(word)
cnt.most_common()#出現頻度が高い10語とその出現頻度をグラフで表示する
import matplotlib.pyplot as plt
x = [ line[0] for line in cnt.most_common()[0:10]]
y = [ line[1] for line in cnt.most_common()[0:10]]
plt.bar(x,y)
plt.show()最後に
データサイエンティストを目指してます。これからデータ分析の勉強をしていく中で、自身なりのアウトプットを投稿します。興味のある方や勉強中という方は他の投稿も見てあげてください。
次はPandasに挑戦してみようかな...
この記事が気に入ったらサポートをしてみませんか?