
頭が痛いPDFの変換(Google Pixelを使う:その4)

書籍の執筆を行なっていると、PDFを扱う場合が多い。これをテキストに変換したいという場合がしばしばある。
例えば、私はnoteで新刊書籍の「立ち読みサービス」を行なっているが、そのためには、書籍のテキストが必要だ。
元々の原稿はもちろんテキストで持っている。しかし、校正の過程で直しが入る。このため、最終稿は出版社のPDFでしか存在しない。
ところが、これをテキストに直すのが、簡単な作業ではないのである。
Google Pixel3は、これに対する解決策を提供してくれるだろうか?
書籍の作成過程で出版社がゲラをPDFにしたものは、アドビ・アクロバットの書き出し機能では読めないことが多い。
印刷所が、印刷のためのさまざまな指定をいれていて、読むためにはそれが邪魔になるのだ。
ただし、出版社により、また印刷所により事情が違うので、一般的なことは言いにくい。そのために対処が複雑になるということもある。
テキスト化できれば、何でもできる(Google Pixelを使う:その3)で示したように、紙の書籍を自分でスキャナにかけて作ったPDFは、アドビアクロバットの書き出し機能で読める。それとこれとは、事情が違うのだ。
多くの人にとってはあまり関係のないことかもしれない。しかし、出版社の人にとってはもちろん、執筆者にとっても頭が痛い問題なのだ。
外国語の本も簡単に読める(Google Pixelを使う:その2)で「連日格闘している」と言ったことの一つは、これである。
PDFをテキストに変換できない
具体的な例で示そう。
これが元のpdfだ。
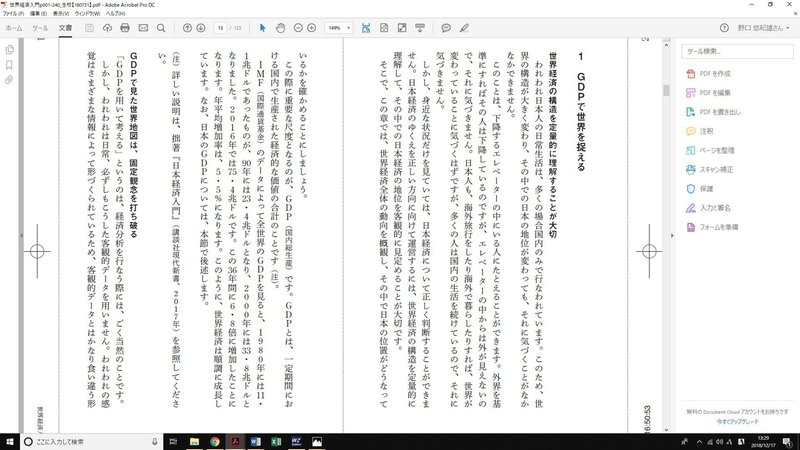
これをアドビ・アクロバットででワードに書き出すと、つぎのようになる。

改行がおかしくなっているのは、なんとか我慢できる。しかし、数字とアルファベットが別の位置になってしまっている。
右ページには日本語が、左ページ人は対応する位置に数字とアルファベットがある。
自分で紙の書籍をスキャナにかけて作ったpdfの場合にも、ワードの書き出し自体は読みにくい形なのだが、それをテキストに直せば、何とか使える。
しかし、いまの場合には、テキストに直しても、日本語と数字、アルファベットがバラバラのままなので、使えない。
Pixel3なら読める
この場合も、Pixel3なら読める。
いまの例についての結果を示そう(PCのスクリーンにPDFを出し、それをPixel3で撮影した)。
↓↓↓↓↓↓↓↓
(やしかを確かめることにしましょう。 この際に重要な尺度となるのがGDp (国内総生産)。GDPとは、一定期間にお ける国内で生産された経済的な価値の合計のことです(注)。 IMF(国際通貨基金)のデータによって全世界のGDPを見ると、1980年には1・ な り ました。2016年では8・4兆ドルです。この8年間に6.8倍に増加したことに 1兆ドルであったものが、 0年には00.4兆ドルとなり2000年には20.8兆ドルと なります。年平均増加率は、5.5%になります。このように、世界経済は順調に成長し 本のGDPについては、本節で後述します。 W () 詳しい説明は、拙著『日本経済入門』(講談社現代新書、2017年)を参照してくださ 注 240 金校(180731).pdf - Adobe Acrobat Pro D 表示M) ウィンドウ(W) ヘルプ(H) GDPで見た世界地図は、固定観念を打ち破る 「GDPを用いて考える」というのは、経済分析を行なう際には、ごく当然のことです。 しかし、われわれは、必ずしもこうした客観的データを用いません。われわれの感 覚はさまざまな情報によって形づくられているため、客観的データとはかなり食い違う形 世界経済) ここ
↑↑↑↑↑↑↑↑
この場合にも、改行がないとか、若干の読み取りミスがあるなどの問題がある。しかし、あまり大きな問題ではない。
最大の問題は、一枚づつ写真をとって変換していかなければならないことだ。
数ページであれば何とかなるが、本一冊となると、なかなか苦しい。
こういうわけで、どちらも完全な解にはなっていない。
ただし、本一冊をテキストに変換するというような必要は、普通はないだろう。
そうであれば、pixel3で十分だ。
この記事が気に入ったらサポートをしてみませんか?