
第1章 AIは驚異的に進歩したが、万能ではない

1.なぜAIについて知る必要があるか?
Q AIとは何ですか?
AIとは、「Artificial Intelligence」の略で、日本語では「人工知能」と訳されます。人間の知的な活動をコンピュータに行なわせるための技術です。
これまでも、何度かブームが起きています。第1回目は1956年〜1960年頃、第2回目は1980年代でした。しかし、いずれも限界に突き当たって、ブームは去りました。
2010年以降に第3次ブームが起こり、現在まで続いています。その背景には、ビッグデータを用いた機械学習の進歩があります(その内容については、後述します)。
AIについて、厳密な定義はありません。したがって、コンピュータの利用のどの範囲のものをAIと呼ぶかは、論者によって差があります。
単にコンピュータを用いることを「AIを使う」といっている場合も見受けられます。
ただ、これは、あまりに広い定義でしょう。後述するように、「ビッグデータによる機械学習を行なうコンピュータ利用」をAIと呼ぶのが適当だと考えられます。

Q 私の生活にはAIは関係がなさそうに思えるのですが、
なぜAIについて知る必要があるのですか?
AIは、様々な面で生活や経済活動に大きな影響を与えるからです。その影響は、すべての産業に波及します。
これまで、コンピュータやロボットが代替するのは、単純労働が中心と思われていました。しかし、AIは、知的労働の分野にも進出しています。
例えば、AIは、囲碁で人間を打ち負かしました。翻訳もできます。データを与えられて記事を書くこともできます。作曲もできますし、自然法則の発見もできるようになっています。
ビジネスでも、様々な場面で使われています。また、個人個人の特殊事情に合わせて、適切なアドバイスができるようにもなっています。
これまで人間がやってきたことを、コンピュータがより効率的に遂行できるようになったのです。したがって、これまで人間が行なっていた仕事の多くが、AIにとって代わられる可能性があります。
しかし、その半面で、新たに発展する部門もあります。それをうまく捉えることができれば、成長することができます。したがって、どんな仕事がAIによってとって代わられ、どんな仕事がAIによって価値を高めていくかを、正しく捉えることが重要なのです。
Q AIは、これまでのコンピュータと何が違うのですか?
コンピュータが自動的に学習する能力を備えたことです。これは「機械学習」といわれるものです。
これまでのコンピュータでは、データ処理の方法を、一段階ずつ細かく、人間がプログラムして与えていました。
ところが、最近では、そうした手続きの少なくとも一部分を、コンピュータがデータから学習することによって、自動的に行なうことができるようになりました。
自動学習するAIの成果が最も著しく現われたのは、「パターン認識」です。これは、図形や自然言語を認識することであり、これまでは、コンピュータが最も不得意な分野でした。
このため、例えばネットショップで商品の写真を選定する作業は、人間が行なうしかなかったのです。大量の写真を人海戦術によって処理していました。
ところが、機械学習によって図形認識が可能になったので、この仕事をコンピュータに任せることが可能になりました。
Q 「機械学習」や「ニューラル・ネットワーク」とは何ですか?
「機械学習」とは、コンピュータが自動的に学習することです。
ただし、データを与えさえすれば機械がまったく自動的に学習してくれるわけではありません。どのような方法を使ってどのように学習するかは、人間が考えて、その仕組みを作ります。
「学習」とは、主として、その手法(モデル)におけるパラメーター(係数など、モデルの挙動を決める数)を、適切な値に設定することです。
「ニューラル・ネットワーク」は機械学習を用いる仕組みの1つです。人間の神経組織を真似た仕組みを、コンピュータの中に作ります。
ニューラル・ネットワークは、最初の層から最後の層に至る多数の層によって形成されます(図表1‐1参照)。それらの層の間で、情報が伝達されていきます。中間の層を「隠された層」といいます。次に解説する「ディープラーニング」は、この中間層が多数あることから、「ディープ」と呼ばれているのです。
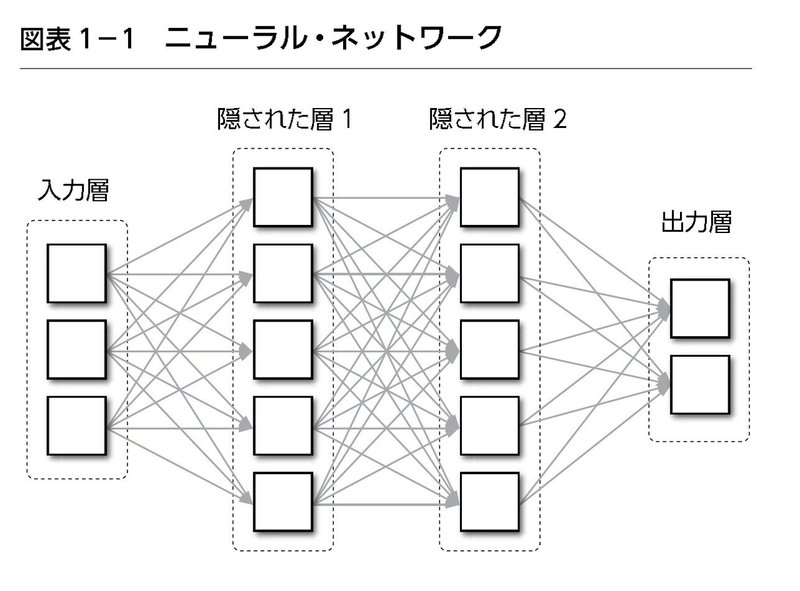
Q 「ディープラーニング」とはどのような手法ですか?
ニューラル・ネットワークによって画像認識を行なう場合、まず画像を多数の小さな部分(ピクセル)に分け、その部分の明るさを0から1までの数値として表わし、ニューラル・ネットワークの最初の層に入力します。
最初の層の個々のニューロンは、その値を加工して2つ目の層にデータとして送ります。ここで「加工」というのは、次の層のニューロンごとに異なる「重み」をつけるという意味です。
このようにして、最後の層にデータが渡され、最終的な出力が生成されます。
しかし、最終的な出力は、正解とは異なるかもしれません。
そこで、最終結果と正解の誤差が小さくなるように、「重み」を修正します。
ほぼ毎回正しい答えを出せるようになるまで、何十万枚、あるいは何百万枚、何千万枚もの画像で学習させます。
こうした方法によって、いまでは、特定の分野での画像認識は、人間の能力を超えるまでになりました。
Q 機械学習の方法は、ニューラル・ネットワークだけですか?
機械学習の方法は、ニューラル・ネットワークだけではありません。これと並んで重要な方法として、「ベイジアン・ネットワーク」があります。
多くの問題において、複数の原因と結果があり、因果関係は単純な1対1ではありません。ベイジアン・ネットワークは、こうした問題を扱うための手法です。
この手法によれば、原因から結果への因果関係が分かっているとき、観測された結果から原因を推測することができます。因果関係を図で見られるので、直観的に理解しやすいという利点を持っています。この点で、人間の思考法に近いものです。
ベイジアン・ネットワークは、まず、病気の自動診療への応用が試みられています。医師が経験と診療データに基づいて診断するのと同じことを、ベイジアン・ネットワークで自動的に行なうのです。症状、検査データ、患者の申告などのデータを与えて、病気を判定します。
また、ベイジアン・ネットワークを用いた機械修理のための自動診断プログラムも作られています。データを常時更新していれば、異常を事前に予知することができます。こうして、「データ駆動的な」(後述)運営が可能になります。
そうなれば、事故が起こってから対応するのではなく、事前に対処することができます。日本では、社会資本の維持補修がこれから重要な課題になるので、事前対応型の採用は重要な課題です。
企業経営に応用すれば、状況変化に敏速に対応する「データ駆動型経営」(後述)が実現できます。
ベイジアン・ネットワークの応用対象は、他にもあります。データから人格を推定する「プロファイリング」(後述)のための手法としても有効です。音声認識、文字認識、データマイニング(大量のデータを解析し、何らかの有用な知見を得ること)にも使われます。
Q 機械学習の方法は、ニューラル・ネットワークやベイジアン・ネットワーク以外にもありますか?
機械学習の手法には、次のようなものもあります(これらの手法の詳細については、本書では説明しませんが、「こうした名の方法がある」ということを知っておいてください)。
⑴昔から用いられてきたものとして、「回帰分析」があります。説明変数と被説明変数の関係を線形式(一次式)で表わし、その係数や切片を、データから最小二乗法や最尤推定によって決定します。
線形式による回帰だけでなく、「ロジスティック回帰」(ロジスティック曲線を当てはめる)や、「サポートベクターマシーン」(SVM:データを分類するための境界線を決定する手法)などもあります。
⑵「決定木」(けっていぎ)は、木構造のモデルによって分類する手法です。1つの説明変数とその閾値によってデータを2つに分け、さらに枝先で同様に別基準でデータを分けることによって、分類します。
これを発展させたものとして、「ランダムフォレスト」(決定木を複数作り、多数決によって最終的なクラスを判定する)、「勾配ブースティング木」などの手法があります。
⑶右記以外の機械学習の手法として、「時系列分析」(AR、MA、ARIMAモデルなど)、「クラスタリング」、「協調フィルタリング」などがあります。
Q 機械学習によれば、何でも自動的に学習できるのですか?
機械学習には限界があります。
「コンピュータが自動的に学習する」といっても、人間が与えたデータを学習するだけです。SF映画にあるように、「コンピュータが自動的にウエブを探って、様々な知識を学ぶ」といったことは、(少なくとも現在では)できません。
個別の問題に対してどのような手法が適切かは、人間が決める必要があります。機械学習とは、あくまでも手法で用いられるパラメーターを決定するだけなのです。
また、「オーバーフィッティング」(過学習)と呼ばれる問題があります。
これは、「学習用のデータに対しては正しい答えを出せるが、新しいデータを見せられると間違ってしまう」という問題です。学習用データの中で本来学習させたい特徴とは無関係な特徴に適合してしまい、学習用データについての性能は向上するものの、それ以外のデータでは逆に結果が悪くなるのです。
例えば、「猫と犬の区別はできるが、人間の写真を見せれば判別不能」といったことが生じます。
機械学習の技術でできるのは、あくまでも局所的な最適化なのです。
ですから、新しい状況が生じた場合には、それが過去のデータと非常に近い場合には何とか適応できますが、人間のような柔軟な対応はできません。その意味で、AIの認識能力は、人間のレベルには遠く及びません。
このため、AIによる顔認識(AIのパターン認識機能を利用して、人間の顔の写真から、それが誰であるかを識別する機能)も欺くことができるといわれます。カーネギーメロン大学の研究によると、特殊な模様にペイントされた眼鏡をかけると、顔認識の網を逃れることができるそうです。
以上で述べたようなAIの限界を認識しつつ、これを現実の仕事にうまく活用していくことが必要です。
Q AIは万能なのですか?
重要なのは、汎用AIと特化型AIの区別です。
「汎用AI」(General AI)とは、人間が持っているあらゆる感覚とあらゆる判断力を持ち、人間と同じように(場合によってはそれ以上に)考え、仕事を遂行するコンピュータです。
これに対して、「特化型AI」(Narrow AI)とは、特定の仕事について、人間と同等に(あるいはそれ以上に)処理することができるコンピュータです。
多くの人がAIについて持っているイメージは、汎用AIです。これはSFや映画に登場するAIのイメージに大きく左右されています。例えば、映画「スター・ウォーズ」の「C‐3PO」です。
しかし、人類は、そのようなAIを、少なくとも現時点においては実現できていません。将来において実現できる可能性は否定できませんが、確実にできるとはいえません。
これまでに人類が作り上げたものは、「特化型AI」でしかありません。つまり、AIができることは、極めて限定的なのです。そして、いかなる仕事をどのように遂行するかは、人間が指定します。「問題を解決してくれ」と頼めば自分でやり方を工夫して対処してくれるC‐3POのようなわけにはいきません。
Q では、「AIはあまり重要でない」と考えてもよいのですか?
現在のAIが「特化型AI」でしかないからといって、「AIの影響を軽視してよい」ということにはなりません。
限定化されたタスクについては、人間よりはるかに高速に、正確に仕事を遂行してくれるからです。AIが人間以上の能力を発揮し、人間以上の効率で働いてくれる分野がいくつもあります。そして、そうした分野が急速に拡大しつつあります。
こうした分野の仕事について、人間がAIと競っても意味はありません。それは、人間より速く走ることができる機械(自動車や電車)と競走しても意味がないのと同じです。
競争するのでなく、それらの機械をうまく利用することを考えるべきです。AIについても、同じことがいえます。AIが得意な分野について、いかにそれを活用できるかを考えるべきです。
AIが発達して、人々の職を奪ってしまうのではないかといわれます。あるいは反対に、AIはこれまで人間がやっていた仕事を代わってやってくれるから、今後の日本のように労働力不足が深刻な問題になる国では、積極的に導入すべきだとの考えもあります。
こうした考えのどれが正しいのかを判断するには、AIに何ができるかを、正確に理解する必要があります。そのためには、AIがどのように機能しているかを知る必要があります。
Q 「人間にやさしいAI」が必要と思いますが、どうでしょうか?
「人間にやさしいAIが必要」との意見がしばしば聞かれます。しかし、これがAIの利用を判断する有効な基準になりうるでしょうか?
そうとは考えられないケースがあります。例えば、第3章で、AIによる信用スコアリングについて述べます。これは、個人や企業の信用度をAIで推測しようとするものです。しかし、これによって信用度が低いと判定されてしまった個人や企業は、これまで利用していたサービスを利用できなくなるかもしれません。
これは、「人間にやさしいAI」とはいえないでしょう。では、こうした技術は開発しないほうがよいのでしょうか? そうともいえないでしょう。
あるいは、第6章の2で、AIによる不正検知のシステムについて述べます。しかし、これは、犯罪者の立場から見れば、間違いなく脅威です。犯罪者も人間ですから、これは、人間にやさしくないAIです。だから、「人間にやさしいAIがよい」という基準からすれば、不正検知AIは、排除されるべきだということになるでしょう。
しかし、多くの人は、「不正や犯罪を検知してくれるなら、積極的に導入すべきだ」と考えるでしょう。
ここで問題は、「不正や犯罪とは、何か?」ということなのです。これこそが、もっと重要な問題です。
要は、技術をどのように利用するかということです。その判断にあたって、「人間にやさしいか否か」は、有効な判断基準とはなりません。
人にやさしいAIを作るか、やさしくないAIを作るかではなく、様々な使い方ができるAIをどのように使うか、そしてそのための法整備や社会的な規範、社会的な同意をどのように形成していくか、ということが問題なのです。
AIは、能力が優れているため、これまでの社会で曖昧にしていたことが、はっきりした形で現われてしまいます。あるいは、これまで問題となっていなかったことが問題となります。そのような能力を持ったAIを、どのような目的のために、どのような基準にしたがって用いるかが問われているのです。
2.金融で用いられるAIの手法
Q 「プロファイリング」とは何ですか? また、金融ではどのように利用されるのですか?
「プロファイリング」とは、もともとは、犯罪捜査で、犯罪の特徴などから犯人像を割り出す方法のことでした。
最近では、インターネットなどから得られる個人データを分析し、個人像を描き出すための手法を指します。
データから、ある人の性格や嗜好、意見などを推測します。プロファイリングが進めば、個人の行動を予測できるようになります。最近では、AIとビッグデータの活用によって、精度が向上しています。
プロファイリング技術は、すでにいくつかの分野で、実際に利用されています。
金融では、これを利用して、融資の判断に個人の信用度を算出する試みが始まっています(第3章)。
プロファイリングは、保険でも利用が始まっています。自動車にセンサーを搭載し、運転の状況によって保険料を変える自動車保険がすでに提供されています(第5章)。
また、血液検査などのデータから保険金の支払いを自動的に変える保険も登場しています(第5章)。
Q 「フィルタリング」とは何ですか? また、金融ではどのように利用されるのですか?
ある特定の条件を満たすデータを選び出すための方法です。
従来から、スパムメール(迷惑メール)の自動検出のために、フィルタリングが行なわれてきました。メールに含まれている文言などから、AIがスパムか否かを自動的に判断します。侵入の探知などにも用いられます。
Facebookでは、毎日ユーザーから投稿される10億枚の写真について、ポルノや暴力的なものをAIが判別し、不適切なものをフィルタリングして除いています。
金融では、不正行為の検知と防止のために使われています(第6章)。
Q プロファイリングやフィルタリングは、金融以外ではどんなところに使われていますか?
プロファイリングの技術は、これまで、Googleの検索履歴やFacebookの「いいね!」のデータから、その人がどのような人であるかを推測するのに用いられてきました。
そしてその人に合った広告を送るのです。GoogleやFacebookは、このような広告モデルによって急成長してきました。Netflixも、同様の手法でレコメンデーション(顧客の好みに合っていると思われる広告を出すこと)を行なっています。
2018年3月には、Facebookの個人データが不正な方法で取得されて分析され、アメリカ大統領選挙で用いられた(個人ごとに異なるメッセージを送るために使われた)のではないかということが、大きな社会問題となりました。これは、データサイエンス(後述)の進歩によって、データから個人を正確にプロファイリングすることが可能になっていることを示しています。
プロファイリングやフィルタリングの技術は、医療分野でも利用が広がっています。X線やCT、MRIなどの画像から、ガンやその他の疾患を検知できます。こうして、自動診療への応用が進められています。医師に代わって病気を診断することも試みられています。
また、AIの図形認識能力が発達したため、自動車の自動運転が可能になろうとしています。これが実用化されれば、タクシー業界や運送業界に大きな影響が及ぶでしょう。
AIは、軍事目的にも利用されています。
Q どんな分野でも人間は要らなくなってしまうのですか?
人間でなければできない仕事は必ず残るでしょう。実現できるAIが特化型AIでしかないということは、人間でなければできない仕事が残ることを意味します。
機械の力ですべてが実行できるわけではありません。AIの学習過程を含め、人間による仕組みづくりや、結果の検証が不可欠です。また、コンピュータによる自動的な意思決定プロセスを理解し、監視し、改善するのも人間の仕事です。定型化されていない問題に対して大局的な洞察や意思決定を行なうことも、人間でなければできません。
さらに重要なのは、「AIの活用が広がるにつれて、人間でなければできない仕事の中で、価値が高まるものがある」ということです。AIが遂行できる分野で効率が上がれば、人間でしかできない仕事の中で、これまでよりも価値が高まるものが必ずあるはずなのです。そうした仕事を見出し、それに特化する個人や企業が、これからの社会において成長することになるでしょう。
ですから、「AIが職を奪うから大変だ」と騒ぐだけではなく、「AIに何ができるのか」「AIに何ができないのか」「AIの広がりによって価値が高まる仕事は何か」を知ることが、極めて重要です。
そして、人間がAIの力を借りて仕事の効率を向上できるように革新を進める必要があります。
3.フィンテック、ブロックチェーン
Q フィンテックとは何ですか?
フィンテックとは「ファイナンス・テクノロジー」の略です。金融とIT(情報技術)との融合による新しい技術革新を指します。
フィンテックでは、決済、融資、資産運用、保険などの分野で、様々な新しいサービスが登場しています。モバイルペイメントやP2P融資(Peer to Peer Lending、第8章参照)といった金融機関に代わるサービスを提供する企業も登場しています。また、スマートフォンを用いる決済や、AIを用いる投資コンサルティング(第4章参照)なども登場しています。これらを、図表1‐2では、中ほどにある四角形で表わしています。

なかでも、AIとブロックチェーン(次項参照)が重要です。図表1‐2では、AIを上にある円で、ブロックチェーンを下にある円で、それぞれ示しています。
フィンテックには、AIとブロックチェーン以外のITによるものもあります。例えば電子マネーがその例です。図表1‐2では、これらを、四角形のうち2つの円のどちらにも属さない領域として表わしています。本書では、AIとブロックチェーン以外のフィンテックも扱っています。
AIとブロックチェーン技術以外のフィンテックが世の中を便利にすることは事実です。しかし、真に革新的な変化は、AIとブロックチェーン技術によってもたらされることに注意が必要です。
また、AIとブロックチェーンは、金融以外にも応用できます。これらは、図表1‐2では、2つの円のうち、四角形に属さない領域として表わされています。
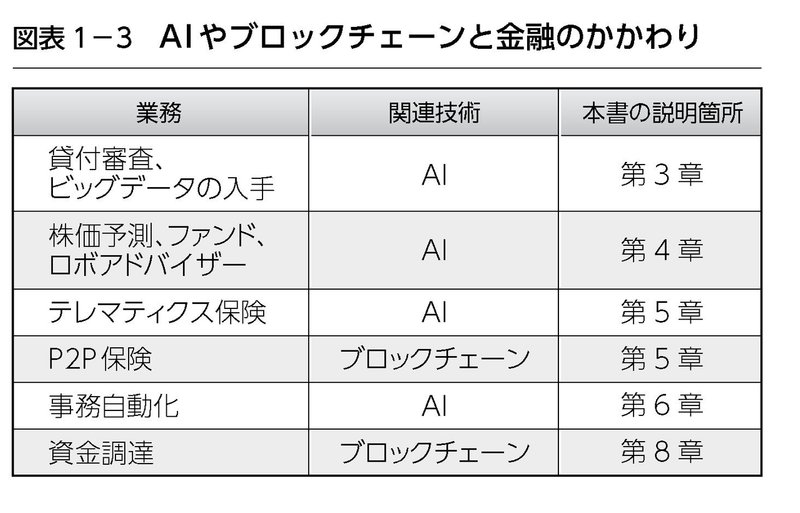
なお、AIやブロックチェーンと金融のかかわりと、それらを本書のどこで説明しているかを、図表1‐3にまとめて示します。
Q ブロックチェーンとは何ですか?
「ブロックチェーン」とは、電子的な情報を記録する仕組みであり、仮想通貨の基礎になっている技術です。
次の2つの重要な特性を持っています。
第1は、管理者が存在せず、自主的に集まったコンピュータが運営しているにもかかわらず、行なっている事業が信頼できること。第2は、そこに記録された記録が改ざんできないことです。
ブロックチェーンは、次に述べるように、広範な応用可能性を持っています。
Qブロックチェーンと金融とのかかわりはどのようなものですか?
仮想通貨がブロックチェーンの最初の応用対象ですが、それだけではありません。ブロックチェーンは、広範な応用可能性を持っています。
保険、証券、資金調達で応用が試みられています。これらは、図表1‐2では、下の円と四角形との共通領域として表わされています。
金融関係に限っても、まず、証券取引の決済・清算にブロックチェーンを用いようとする実験が、アメリカの証券取引所NASDAQや、日本取引所グループで行なわれています。
さらに、保険やデリバティブの取引等にも、ブロックチェーンの応用が試みられています。保険の分野では、すでにブロックチェーンを用いた新しいタイプの保険が登場しています。
本書では、保険について第5章で、資金調達について第8章で説明します。
ブロックチェーンは、金融の分野にとどまらず、あらゆるビジネス、組織のあり方、さらには、私たちの働き方にまで本質的な変革をもたらします。
応用範囲は金融にとどまりません。登記、商品の履歴記録、IoT、シェアリング・エコノミーなどへの応用が試みられており、経済社会を大きく変える可能性を持っています。これらは、図表1‐2では、下の円のうち四角形に属さない領域として表わされています。
ブロックチェーンについての詳細は、拙著『入門 ビットコインとブロックチェーン』(PHPビジネス新書、2017年)を参照してください。

4.データサイエンス、データ駆動型科学
Q 「データサイエンス」とは何ですか?
一般には、「コンピュータサイエンス、数学、統計学、情報科学などの知見や手法を用いてデータを分析する科学。ビッグデータ、AI、ディープラーニングなどと関連する」と説明されています。
ただし、単に「データを扱う」というだけなら、これまでも広く行なわれてきました。
重要なのは、方法論の大転換です。理論とデータの位置づけに関して、これまでとは正反対のアプローチを取っているのです。
従来の考えでは、まず理論モデルがあり、それから観測可能な結果を導き出します。それを実際のデータと突き合わせて、理論モデルの正しさを検証します。これは、「理論駆動型」または「仮説駆動型」と呼ばれるものです。
ところが、データサイエンスでは、これと逆の方法論を取っています。つまり、理論モデルがなくても、データを用いてコンピュータに判断させ、モデルを導くのです。
モデルが明確には分からない場合もあります。ディープラーニングの場合、なぜ、導き出されたパラメーターの組み合わせが最適なのかが、解釈できない場合もあります。そうであっても、答えが正しければよいとされます。
このため、データサイエンスは、「データ駆動型科学」(data driven science)とも呼ばれます。
ビッグデータなどの新しいデータを活用する経営は、一般に「データドリブン経営」(データ駆動型経営)と呼ばれます。
日本のコンビニエンスストアは、POSデータ(Point of Sales data:商品が売れた時点のデータ)を活用した購買行動分析によって、利益率を向上させました。最近では、電子マネーのデータを活用しています。
Q ビッグデータとは何ですか?
スマートフォン利用の広がりなどによって、これまでは利用できなかったデータが大量に利用できるようになってきました。これらは、「ビッグデータ」と呼ばれます。
例えば、スマートフォンを利用してメールを送ったとします。その情報は、相手に届くだけではなく、メールサービスを運営している主体(GmailであればGoogle)によって利用されます。検索の際に入力した情報や、カレンダーに記入した情報も同様です。マップの利用履歴やネットショップでの購入記録なども、ビッグデータとして利用されます。
こうした利用は、必ずしも情報の発信者が意識しているものではありませんが、結果的に、そうしたデータが利用されます。
なおビッグデータは、スマートフォンやPCの利用で集められるものだけではありません。
例えばコンビニエンスストアのポイントカードによっても、情報が得られます。コンビニエンスストアがポイントカード利用を勧めるのは、かつては顧客の囲い込みのためでしたが、現在ではデータの取得が主たる目的になっています。
1つ1つの情報は、例えば「コンビニエンスストアで何を買った」というような、どうでもよい情報で、秘密でも何でもありません。しかし、それらを集積し、分析することによって経済的価値が生じるのです。
Q ビッグデータのサイズは、これまでのデータに比べてどのくらい大きいのですか?
しばらく前までは、データサイズの単位として「メガバイト」を使っていました。しかし、最近では、ビッグデータを扱う場合には「ペタバイト」が単位として使われています。これは、メガの10億倍です。
1メートルを10億倍すれば100万㎞になりますが、これは月までの距離の約2・6倍です。ですから、これまでは人間の身体のサイズで仕事をしていたのが、宇宙的サイズで仕事をするようになったようなものです。
今後、IoT(Internet of Things:モノのインターネット:工場の機械などをインターネットで接続したシステム)によって極めて多数のデバイスにセンサーが取り付けられると、得られるデータの量が飛躍的に増加します。
Q 「データ駆動型」に問題はありますか?
データドリブン経営の多くは、企業が利益率向上のために導入するものです。それは、他方において、プライバシー侵害などの問題もはらみます。
また、新しい格差を生む可能性もあります。平均値で扱われるなら差別化はなされませんが、個別の状況が考慮されると、差が問題になるからです。例えば、信用度スコア(第3章参照)が低いと判断された人が様々なサービスを受けられなくなるなどの問題が発生するかもしれません。
また、格差が、企業間でも生じる可能性があります。ビッグデータを扱える企業は、ごく限定的だからです。それは、新しい形の独占をもたらすでしょう。
Q 「非構造化データ」とは何ですか?
これまでデータ分析で使われてきたデータは、「構造化データ」と呼ばれます。これは、CSVファイルやExcelファイルのように、「列」と「行」の概念があるデータです。
構造化データは簡単に分析できます。なぜなら、「どこに何があるか」が列で決められており、しかもデータは数字で表わされているため、演算、比較などが容易にできるからです。
ところが、ビッグデータの中には、これとは性質の違うものが含まれています。
まず、新聞・雑誌等の活字データや、図、写真データ、ラジオやテレビ放送等の音声データや映像データがあります。これらは以前から存在していましたが、データ分析にはあまり用いられていませんでした。
これらに加え、最近では、電子メールやソーシャル・ネットワーキング・サービス(SNS)などの文字データ、検索履歴、GPS(全地球測位システム。人工衛星からの電波によって現在位置を知ることができる)から送信されるデータなどが、利用可能になってきました。
これらが、「非構造化データ」と呼ばれるものです。
非構造化データにはまず、データは数字で表わされているけれども、統一的な列と行で整理できていないものがあります。
さらに、データが数字で表わされていないものもあります。数字で表わされない非構造化データには、実に様々なものがあります。

この記事が気に入ったらサポートをしてみませんか?