【python】 気温の予測 線形回帰分析

はじめに
貴重なお時間ありがとうございます。
Aidemy Premiumにて「データ分析コース」を6ヶ月受講いたしました。
Aidemy Premiumを受講したのは、データ分析、機械学習、Pythonをしっかりと学びそれを活かして仕事をしていきたいと思ったことが理由です。
勉強に取り組む中でAI、機械学習等のPythonに関するワードを耳にする機会が増えてきました。
ただ、実際に調べてみると意味のわからない横文字(例. ディープラーニング)、聞いたことのない日本語(例. 深層学習)等あり覚えるのや理解するのが難しかったです。
こちらの記事で現時点での知識や経験をシェアしたいと思います。
暖かい目で目を通していただければ幸いです。
・実行環境
Google colaboratory
今回は、回帰の問題を解いていきます。
身近にある気象データから自分の住んでいるエリアの気温予測を行ってみました。
今回は、過去の平均気温を元に明日の平均気温を予測するコードを書いていきます。
早速いきましょう!
1.必要データのダウンロード
今回は、気象庁のHPから今回使用するデータだけをダウンロードします。
データは2013年1月1日から2022年11月9日までを取り出してみました。
サイトはこちらです。
2.必要ライブラリのインポート
使用するライブラリをインポートします。
後からでもインポートできるので使用する際にインポートするのでも
全然問題ないと思います。
#ライブラリの追加
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
from sklearn.linear_model import LinearRegression
import glob 3.データの読み込み
#データの読み込み
file_path = glob.glob("/content/drive/MyDrive/成果物/*.csv")
for path in file_path :
df = pd.read_csv(path,sep=",", encoding ="SHIFT-JIS",skiprows=4)
df = df.drop(df.columns[2:], axis=1)
print(df.head())print(df.head())の出力結果はこちらになります。
今回はデータを3分割(2013/01/01 - 2015/12/31, 2016/01/01 - 2018/12/31, 2019/01/01 - 2022/11/09まで)している為、以下の出力結果となります。
Unnamed: 0 が日付、Unnamed: 1 が平均気温となります。

4.データの連結
#データの連結
all_df = pd.DataFrame()
for path in file_path :
temp_df = pd.read_csv(path,sep=",", encoding ="SHIFT-JIS",skiprows=4)
temp_df = temp_df.drop(temp_df.columns[2:], axis=1)
all_df = pd.concat([all_df,temp_df])
len(all_df) 上述したとおり今回はデータを3分割(2013/01/01 - 2015/12/31, 2016/01/01 - 2018/12/31, 2019/01/01 - 2022/11/09まで)して読み込んでいる為、データの連結を行う必要があります。データを3分割した理由としましては、データ量が多く、一度に全てダウンロードすることが出来なかった為です。
今回は約9年と300日程のデータを使用していますので、以下の出力結果を見ると正常にデータの連結が行うことが出来ているのが分かります。
len(all_df)の出力結果はこちらになります。

5.データを使用しやすいように整理する
データを日付順に並び替えます。
この際にデータが日付の値であることを定義します。
all_df[all_df.columns[0]] = pd.to_datetime(
all_df[all_df.columns[0]],format = "%Y/%m/%d"
)
all_df = all_df.sort_values(all_df.columns[0]) dfにall_dfのコピーを代入します。
これをすることでdfはall_dfとは関連を持たない別のオブジェクトとして作成されます。
df = all_df.copy()列名称を変更します。
Unnamed: 0 を年月日、Unnamed: 1 が平均気温(℃)に変更します。
#列(columns)名称の変更
df = df.rename(columns={'Unnamed: 0': '年月日', 'Unnamed: 1': '平均気温(℃)'})年月日を年、月、日毎のデータに分けます。
#年月日を分ける
df["年月日"] = pd.to_datetime(df["年月日"])
df["年"] = df["年月日"].dt.year
df["月"] = df["年月日"].dt.month
df["日"] = df["年月日"].dt.day
print(df)こちらが整理後の出力になります。最初の方と比べると見やすくなり扱いやすくなりました。

では、実際に回帰分析の方を行っていきます。
6.データの前処理
現在から365日分遡って気温データを入れたら翌日のデータが出てくるといった予測を行うモデルを作成したいと思います。
for文の変数iの部分がちょうど365日分のデータをリスト化するところです。
そのリストを次々と配列としてxのデータに登録しています。
その処理結果を学習用データ及びテストデータに適用します。
#データの前処理
def data_set(data):
x = []
y = []
temps = list(data["平均気温(℃)"])
for i in range(len(temps)):
if i < interval : continue
y.append(temps[i])
xa =[]
for j in range(interval):
k = i + j - interval
xa.append(temps[k])
x.append(xa)
return(x, y)#データセット
train_year = (df["年"] <= 2020)
test_year = (df["年"] > 2020)
interval = 365
x_train,y_train = data_set(df[train_year])
x_test,y_test = data_set(df[test_year])
np.array(x_train).shape
(x_train).shape()で形状を確認した出力結果が上の画像の内容になります。
しっかりと各行に対して365日分のデータを持たせることが出来ました。
7.モデルの作成・評価
モデルの作成を行い、学習、評価を行います。
#モデルの作成・学習(線形重回帰分析)
model = LinearRegression(normalize = True)
model.fit(x_train, y_train)
#モデルの評価
y_pred = model.predict(x_test)
y_test =np.array(y_test)
plt.figure(figsize = (10, 6), dpi=100)
plt.plot(y_test, c = "y")
plt.plot(y_pred, c = "b")
plt.show8.誤差の評価
誤差の評価
y_diff = abs(y_pred - y_test)
#誤差の絶対値平均を取る
print("average = ", sum(y_diff)/len(y_diff))
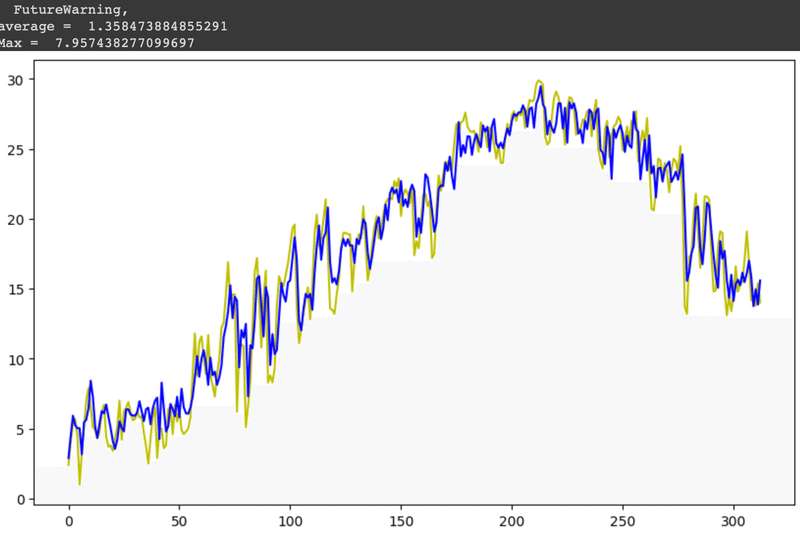
print("Max = ", max(y_diff))モデルの作成・評価の出力結果、誤差の評価の出力結果については以下に
なります。出力結果の考察につきましては10.考察で述べてあります。
9.【比較】もう一つのモデルの結果(Ridge回帰)
比較対象としてRidge回帰でもモデルの作成・評価を行いました。
コード・結果は以下の通りです。
少しでも参考になれば幸いです。
#モデルの作成・学習(Ridge回帰)
from sklearn.linear_model import Ridge
model_Ridge = Ridge(alpha=1)
model_Ridge.fit(x_train, y_train)
# モデルの検証
print('train score : ', model_Ridge.score(x_train, y_train))
print('test score : ', model_Ridge.score(x_test, y_test))
#モデルの評価
y_pred_Ridge = model_Ridge.predict(x_test)
y_test =np.array(y_test)
plt.figure(figsize = (10, 6), dpi=100)
plt.plot(y_test, c = "y")
plt.plot(y_pred_Ridge, c = "b")
plt.show
#誤差の評価
y_diff_Ridge = abs(y_pred_Ridge - y_test)
#誤差の絶対値平均を取る
print("average = ", sum(y_diff_Ridge)/len(y_diff_Ridge))
print("Max = ", max(y_diff_Ridge))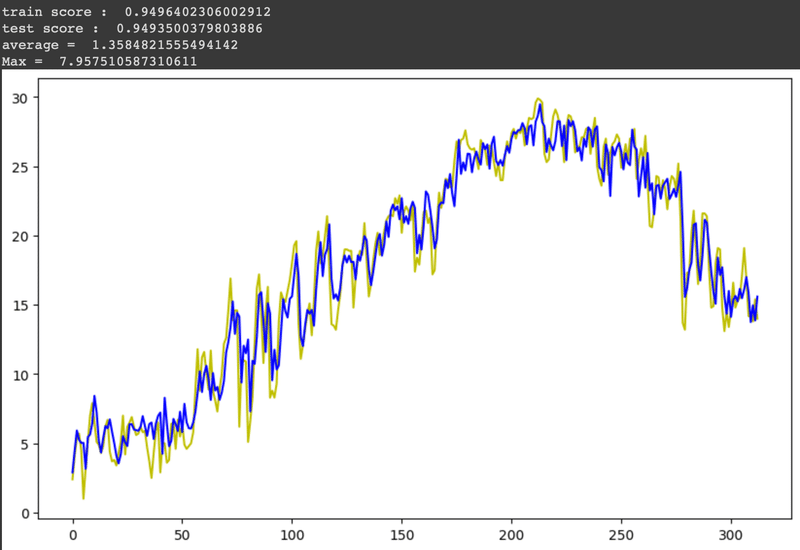
10.考察
今回のデータ分析の結果として誤差の絶対値平均はどちらのモデルにおいても1.36℃ということでしたのでかなり良い精度で翌日の予測ができていると思います。
ですが、誤差の最大は約8℃あります。これは翌日の天気が急激に変わった影響でしょうか。
さらにモデルを良くするためには検証データ量を増やす事や、インターバル(遡る気温データ量)を増やすことが考えられます。
また、そのほかのデータ(気温以外の説明変数)を増やすなども精度を上げる上で考えられる要素になります。
11.今後実施していきたいこと
こうして実際にデータを使って分析することは本当に良い経験になります。
インプットしたことをアウトプットすることによりもっともっとPythonへの理解を深めていきたいと思います。
どのようにしてコードを書けば読みやすいのか、また他人が見ても理解できるようにコードを書くということを意識するなどデータ分析以外の大切な部分も自分自身で試行錯誤してより良いものを作れるようにしていきたいと思います。
まだまだ、初心者レベルですが日々レベルアップして仕事に活用できるレベルまでジブニシンのレベルを引き上げたいです。
最後までお読み頂きありがとうございました。
この記事が気に入ったらサポートをしてみませんか?