
C++で学ぶソートアルゴリズム(データ構造とアルゴリズム入門)

※この記事はCACTUS Advent Calendar 2023 10日目の記事です。
こんにちは!CACTUS Advent Calendar 2023、お楽しみいただけているでしょうか?10日目は私2回目の担当となります!!今回はC言語でソートアルゴリズムを学んでいきましょう!!!
1.動機
我々CACTUSのメンバーが所属している宇都宮大学では工学部の情報コースで2年次に「データ構造とアルゴリズム」という授業があり、そこで様々なソートアルゴリズムを学びます。

ソートアルゴリズムは現代の情報社会で様々なところで使われています。皆さんも実は結構知らないうちに利用してるんです。例えばtwitter XのTL欄。

あれはフォロワーやいいねしたツイートポストとかを参考に関心ある記事を常に上位に出すようになってるんです。これも立派なソート。
今回は、情報系なら知っておくべきことだと思ったという点、また、情報系の学生がどういう感じのことを学習しているかをイメージしてもらうためにこの記事を書きました。
2.ソートアルゴリズムとは
ソートアルゴリズムとは読んで字のごとく、並び替えを行う種々の方法を指します。ソートアルゴリズムには様々な種類がありますが今回は代表的な4つをご紹介します。
2.1バブルソート
バブルソートとは配列の先頭から隣り合ったデータを比較して順序が違ったら入れ替えるソート方法です。

この場合、1回のバブルソートで整列が完了しますが次の場合はどうでしょうか?

この場合、1回バブルソートしたとしても整列は完了しません。そこで、1回目のバブルソートが終了したら末尾の要素を固定してもう一回バブルソートを行う。これを繰り返します。
そしてこれをCで書くとこうなります。
//バブルソート(data:データ,numlen:データの要素数)
void bubble_sort(int *data, int numlen)
{
int i, j;
for (i = 0; i < numlen - 1; i++) {
for (j = numlen - 1; j > i; j--) {
//手順1 隣り合う要素を比較する
if (data[j - 1] > data[j]) {
//手順2 昇順になっていないなら要素を入れ替える
swap(data[j - 1], data[j]);
}
}
}
}2.2 選択ソート
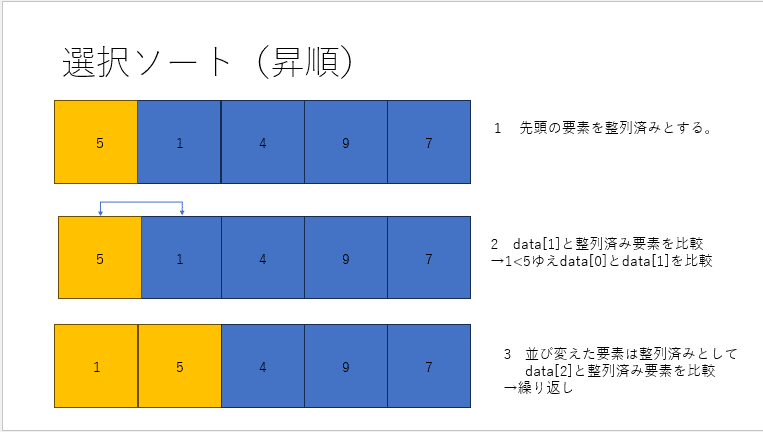
選択ソートとは要素の中から最小値を選び、それをリストの末尾に移すということを繰り返すソート方法です。

これをC言語で記述するとこのようになります。捜査対象の部分で最小値を探してそれを末尾にもっていくことを繰り返しています。
void select_sort(int* data, int numlen) { int i, j; int min; //最小値のインデックス for (i = 0; i < numlen - 1; i++) { min = i;//とりあえず先頭を最小値とする。 for (j = i + 1; j < numlen; j++) { if (data[j] < data[min]) { min = j; } } swap(data[i], data[min]); } }
void select_sort(int* data, int numlen) {
int i, j;
int min; //最小値のインデックス
for (i = 0; i < numlen - 1; i++) {
min = i;//とりあえず先頭を最小値とする。
//最小値を探す
for (j = i + 1; j < numlen; j++) {
if (data[j] < data[min])
{
min = j;
}
}
swap(data[i], data[min]);//最小値を先頭へ
}
}2.3挿入ソート
挿入ソートとは整列済みの要素を持つ配列に対して未整列のデータを適切な場所に挿入するアルゴリズムです。
挿入ソートをCで記述したものが以下のコードとなります。
void insert_sort(int* data, int numlen) {
int i, j;
for (i = 1; i < numlen; i++) { //整列されていない部分の先頭を指す
j = i; // 交換要素のためのインデックス
// 整列済みの場合は処理しない
while ((j > 0) && (data[j - 1] > data[j])) {
// 整列されていない隣り合う要素を交換する
swap(data[j - 1], data[j]);
// 隣り合う要素のインデックスを更新
j--;
}
}
}2.4クイックソート※超重要
続いてクイックソートです。ここまで結構雑に説明してきましたがこいつはかなり重要なので詳細に説明しますね。(基本情報でも頻出)
クイックソートについて述べる前に再帰関数についてお話します。再帰関数とは自分自身を呼び出す関数のことです。
…は?と思われる方も多いと思いますが以下のコードを例にしてわかりやすく解説します。
//一部抜粋
//再帰関数の例
int f(int num) {
//条件1,numの値が1だった時
if (num == 1)
{
return 1;
}
//条件2,1じゃなかったら再帰
else {
num = num + f(num - 1);
}
return num;
}
//これと同義
int sum,n;
int num = 5;
for (n = 1; n <= num; n++) {
sum += n;
}このコードは1~ある任意の数までの和を求めるプログラムです。上の部分が再帰関数を用いて実装した例、下の部分がfor文で実現した例です。再帰関数の処理の流れを図であらわすと以下のようになります。

要するに
1.引数が1じゃないときはf(n)=n+f(n-1)に化ける。
2.引数が1になるまで繰り返して1ならそのまま1を返す
って感じでやるとなんということでしょう。1~nまでの総和が求まってしまったではありませんか!!
というのが再帰関数です。これをクイックソートでは用います。
それでは本題に移ります。クイックソートとは以下の手順で行われるソートのことを言います。
1.ある配列から基準値となるものを1つ決める。
2.その基準値より値が大きいグループと小さいグループで分ける。
3.大きいグループと小さいグループで1→2を行い、これ以上分割できまいところまで手順を進めると昇順に並ぶ。
というものです。まあ文字を並べて説明してもわかりにくいんで例のごとく図を見てみましょう。


こんな感じです。でこれをコードで実装するとこうなります。
//left:配列の左端、right:配列の右端
void quick_sort(int* data, int left, int right)
{
int pivot;
int i, j;
i = left;
j = right;
pivot = data[(left + right) / 2];//とりあえず基準値は真ん中に取る
//基準値より値が大きいグループと小さいグループで分ける
while (1)
{
while (data[i] < pivot)
{
i++;
}
while(pivot < data[j])
{
j--;
}
//i>=jになったらグループ分け終了
if (i >= j)
{
break;
}
swap(data[i], data[j]);
i++;
j--;
}
if (left < i - 1)
{
quick_sort(data, left, i - 1);
}
if (j + 1 < right)
{
quick_sort(data, j + 1, right);
}
}この関数では引数としてデータ、データの左端のと右端のインデックスを与えます。次にカウンタと基準値を指定します。基準値はとりあえず真ん中の要素にしておきましょう。次に基準値より値が大きいグループと小さいグループで分けます。方法としては下図のような感じです。

あとは先ほど述べたとおりです。グループわけした先でもう一回基準値を定めてグループわけをします。この際に再帰関数を使うってことですね!!!
3.結局何が違うのよ
ここまで4つの代表的なソートアルゴリズムを紹介してきました。が、実際得られる結果は全部以下のような結果です。1列目でランダムに並んだ数値が2列目では昇順に整列されていることがわかります。

じゃあ何がちがうのよ?って感じですよね?確かに並び変えるという「目的」は遂行できています。それでいいじゃん!!って思ってる方も多いと思いますがもう少しお付き合いくださいね。
ソートアルゴリズム最大の特徴は計算量と安定性です。下の表をご覧ください。

計算量とは最悪計算時間とも呼ばれアルゴリズムを完遂するために必要な手数のことを指します。例えばO(n^2)ならデータの数が2倍、3倍となれば計算量が4倍、9倍と二次関数的に増加していくことを指します。今回取り上げた4つはすべてO(n^2)です。次に安定性。これは安定した整列が実現できるどうかを示すものです。安定性がないものは場合によっては正しくソートされないことがあります。今回取り上げたものだとクイックソート、選択ソートは安定性がありません。
4.まとめ
まとめるとこんな感じです。
ソートアルゴリズムには様々なものが存在する。
外部的に見れば得られる結果は等しいが、内部的には方法が異なり、それに応じて計算量や安定性に違いが出る。
ソートアルゴリズムをCで書いてみると再帰関数などいろいろな知識を得ることができる。
いかがでしたでしょうか。今回の記事は以上となります。ありがとうございました!!!
この記事が気に入ったらサポートをしてみませんか?