
AWS Bedrock の ナレッジベースを試してみた(利用編)

初めに
前回記事の「AWS Bedrock の ナレッジベースを試してみた(利用開始編)」ではナレッジベースの説明、開始方法を説明しました。
今回は作成したAWS Bedrock の ナレッジベースの利用方法について説明します。
利用方法
データソース(S3)へのファイル設置
データソースとして設定したS3にファイルを設置します。
2024/03/12現在、サポートされているデータ形式は以下の通りです。
(https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/knowledge-base-ds.html より)
プレーンテキスト(.txt)
マークダウン(.md)
HyperText マークアップ言語(.html)
Microsoft Word ドキュメント(.doc/.docx)
カンマ区切り値(.csv)
Microsoft Excel スプレッドシート(.xls/.xlsx)
ポータブルドキュメント(.pdf)
尚、最大ファイルサイズは50 MBの上限がある様です。
データソースの同期(ナレッジベースへの取り込み)
データソースをS3に設置しただけでは利用できません。
S3に設置されたファイルは同期処理にてインデックス化されてナレッジベースに取り込まれます。
ナレッジベースへの取り込みは以下、ナレッジベースの画面上から実施可能です。
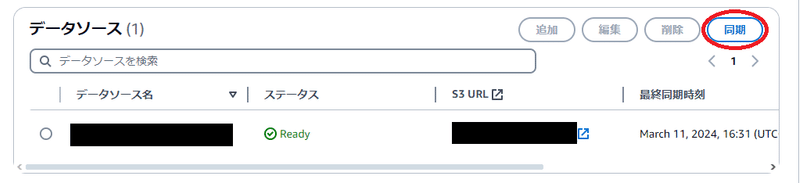
同期処理はファイル変更やファイル設置等、データソースに変更を加えた場合にも必要となりますが、自動実施する機能はないため、本番利用をする場合にはAPIを利用した自動同期機能を実装する必要がありそうです。
APIを利用した同期処理は以下の様なコードで行えます。
import boto3
KnowledgeBaseId="XXXXXXXXXX"
DataSourceId="XXXXXXXX"
my_session = boto3.Session(profile_name='XXXXXX')
client = my_session.client('bedrock-agent', region_name="us-east-1")
response = client.start_ingestion_job(
knowledgeBaseId=KnowledgeBaseId,
dataSourceId=DataSourceId
)テスト実行について
Bedrockのナレッジベースの画面からテスト実行が行えます。

ナレッジベースのテストでは「回答を生成」オプションの有無を設定できます。
無しの場合にはナレッジベースへの検索結果のみをテストできます。
有りの場合には、ナレッジベースへの検索結果を利用した基盤モデルからの回答結果の生成までをテストできます。
そのため、有りの場合には回答を生成する基盤モデルを選択できます。
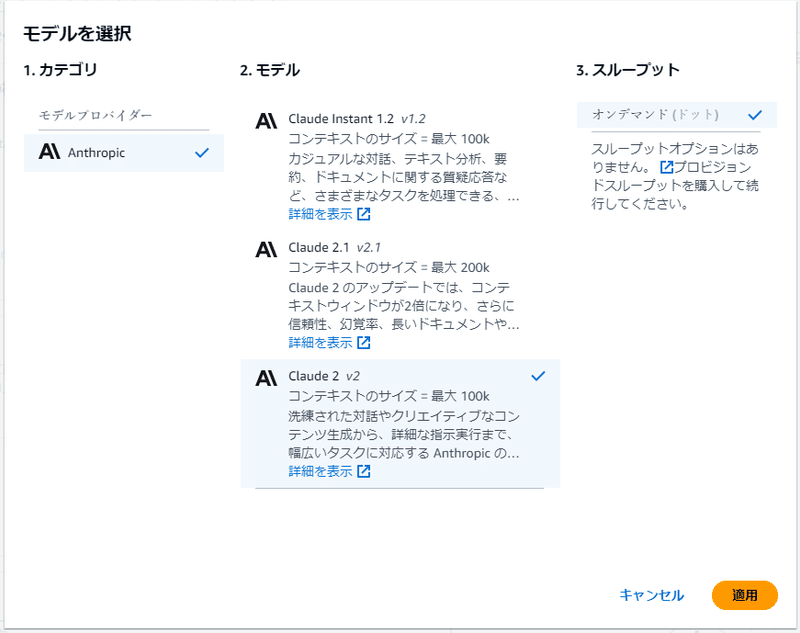
テスト例
今回試しに以下の条件でテストを実施してみました。
回答を生成:あり
モデル:Claude 2
ナレッジベース内のデータは以下のテストデータを利用しました。
Bedrock のナレッジベースのテストです。
ナレッジベースは「ほげほげほげほげほげ」のために利用します。プロンプトは以下を利用しました。
ナレッジベースの用途は?結果は以下の回答がえられ、ナレッジベースへの登録内容に従った回答が得られることが確認ができました。
ナレッジベースは「ほげほげほげほげほげ」のために利用します。また、結果には引用元のチャンクに関する情報についても得ることができます。

ナレッジベースのAPI利用について
ナレッジベースからの検索結果の表示
ナレッジベースへの検索を実施は以下の様なコードで実施ができました。
import boto3
KnowledgeBaseId="XXXXXXXX"
DataSourceId="XXXXXXXX"
Text="ナレッジベースの用途"
my_session = boto3.Session(profile_name='XXXXXX')
client = my_session.client('bedrock-agent-runtime', region_name="us-east-1")
response = client.retrieve(
knowledgeBaseId=KnowledgeBaseId,
retrievalConfiguration={
'vectorSearchConfiguration': {
'numberOfResults': 1,
'overrideSearchType': 'SEMANTIC'
}
},
retrievalQuery={
'text': Text
}
)
print(response)補足としてoverrideSearchTypeはベクトルエンジンをOpenSearch Serverlessを利用している場合のみHYBRIDとSEMANTICが選択可能ですが、OpenSearch Serverless以外の場合はSEMANTIC一択になる様です。
レスポンスは以下の様になりました。
{'ResponseMetadata':
{
'RequestId': 'XXXXXXXXXXXXXXXXX',
'HTTPStatusCode': 200,
'HTTPHeaders':
{
'date': 'Tue,12 Mar 2024 06: 28: 38 GMT',
'content-type': 'application/json',
'content-length': '299',
'connection': 'keep-alive',
'x-amzn-requestid': 'XXXXXXXXXXXXXXXXXXXX'
},
'RetryAttempts': 0
},
'retrievalResults': [
{
'content':
{
'text': 'Bedrock のナレッジベースのテストです。\r \r ナレッジベースは「ほげほげほげほげほげ」のために利用します。'
},
'location':
{
's3Location':
{
'uri': 's3://XXXXXXXXX/テスト.txt'
},
'type': 'S3'
},
'score': 0.6761386
}
]
}コンソール画面でのテストとは違い参照先のS3のファイル名とスコアが表示されました。
ナレッジベースを利用した回答の生成
ナレッジベースを利用した回答の生成は以下の様なコードで実施ができました。
imporX boto3
KnowledgeBaseId="XXXXXXXX”
DataSourceId="XXXXXXX”
Text = "ナレッジベースの用途を教えてください"
ModelArn = "arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-v2"
my_session = boto3.Session(profile_name='XXXXXXX')
client = my_session.client('bedrock-agent-runtime', region_name="us-east-1")
response = client.retrieve_and_generate(
input={
'text': Text
},
retrieveAndGenerateConfiguration={
'knowledgeBaseConfiguration': {
'knowledgeBaseId': KnowledgeBaseId,
'modelArn': ModelArn,
'retrievalConfiguration': {
'vectorSearchConfiguration': {
'overrideSearchType': 'SEMANTIC'
}
}
},
'type': 'KNOWLEDGE_BASE'
}
)
print(response)モデル選択ですが、試しにコンソール上のテスト画面で選択できないモデル(claude-3-sonnet)を利用して試してみましたが、エラーとなりました。
ナレッジベースを利用した回答生成に関しては、対応していないモデルもある様です。
botocore.errorfactory.ValidationException: An error occurred (ValidationException) when calling the RetrieveAndGenerate operation: The model arn provided is not supported. Please check your configuration and retry the request.レスポンスは以下の様になりました。
{
'ResponseMetadata':
{
'RequestId': 'XXXXXXXXXXXXXXXXXXXXXXXXX',
'HTTPStatusCode': 200,
'HTTPHeaders':
{
'date': 'Tue, 12 Mar 2024 08:48:17 GMT',
'content-type': 'application/json',
'content-length': '637',
'connection': 'keep-alive',
'x-amzn-requestid': 'XXXXXXXXXXXXXXXXXXXXXXXXX'
},
'RetryAttempts': 0
},
'citations': [
{
'generatedResponsePart':
{
'textResponsePart':
{
'span':
{
'end': 29,
'start': 0
},
'text': 'ナレッジベースは「ほげほげほげほげほげ」のために利用します。'
}
},
'retrievedReferences': [
{
'content':
{
'text': 'Bedrock のナレッジベースのテストです。\r \r ナレッジベースは「ほげほげほげほげほげ」のために利用します。'
},
'location':
{
's3Location':
{
'uri': 's3://XXXXXXXXXXX/テスト.txt'
},
'type': 'S3'
}
}
]
}
],
'output':
{
'text': 'ナレッジベースは「ほげほげほげほげほげ」のために利用します。'
},
'sessionId': 'XXXXXXXXXXXXXXX'
}回答結果以外に回答生成時に利用したナレッジベースのデータに関しても出力されました。
最後に
AWS Bedrock の ナレッジベースの利用に関しての説明は以上となります。
所感としては、利用開始方法、利用方法ともにナレッジベースの機能はとても簡単に利用ができるので、RAGを実装したい際の近道となるサービスだと感じました。
半面、カスタマイズやチューニングできる部分は少ないサービスとなるため、ナレッジベースで成果が出ない場合には今まで通り独自実装でRAGを実装する必要性があると思います。
そのため、ユースケースとしては、RAGの知識は少ないが、PoC等で取り急ぎ社内のデータがRAGで利用可能であるかの検証を行いたいケースでは活躍しそうです。
この記事が気に入ったらサポートをしてみませんか?