最後にKANは勝つのか?MLPに変わると主張されるKANを試す

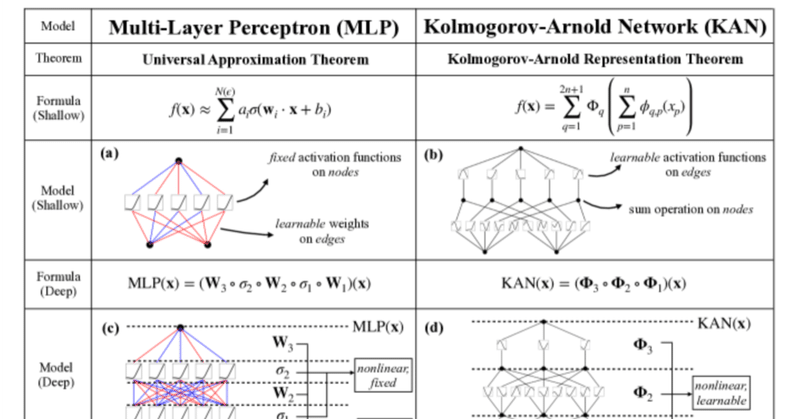
コルモゴロフ・アーノルド・ネットワークス(KAN;Kolmogorov–Arnold Networks)は、MITとカルテック、ノースイースタン大学、NSF人工知能および相互作用研究所らの共同研究によって生まれた、これまでの多層パーセプトロン(MLP;Multi Layer Perceptron)に変わるニューラルネットワークだそうな。
先週一番話題になったので知ってる人も多いと思う。
AIの世界は恐ろしく、世界の片隅で新発見がされるとそれが一週間もしないうちに世界中でテストされ、改良され、確認され、解析される。
KANの公式な実装には機械学習屋がHello Worldと呼ぶMNIST(手書き数字6万字を学習させて精度を競うモノ)がなかった。それどころかGPUも使われていなかったので、「一体全体どうすれば?」と困惑するしかなかったのだが、さすが世界は広い。すでにEfficient-KANや、FourierKANといった実装が公開されている。
KANはセンセーショナルな登場の仕方をしたので、その有効性に疑いの目を持つ人もいて、ある人は「KANは結局MLPである」という論を展開して注目を浴びていた。
I think this depends on what you consider what actually makes a KAN a KAN.
— Ethan (@Ethan_smith_20) May 6, 2024
yes you can compose functions piecewise by shifting in a similar manner with MLPs seen in the colab.
but using B-Splines to model complex curves, isn't really something you see people doing with MLPs… https://t.co/6V2V2BAWY8 pic.twitter.com/VWdF3IKGKp
では果たして本当にMLPなのか?
まずは公式の実装でKANでMNISTをやろうとしてみる。
ところがこれは不可能に近いことがわかった。
!pip install pykan
from kan import KAN
import matplotlib.pyplot as plt
import torch
import numpy as np
import torchvision.transforms as T
from torchvision import datasets
from torch.utils.data import DataLoader, Subset
import numpy as np
train_dataset = datasets.MNIST(root='./data', train=True, download=True,transform=T.Compose([T.ToTensor(), T.Lambda(lambda x: torch.flatten(x))]))
test_dataset = datasets.MNIST(root='./data', train=False,transform=T.Compose([T.ToTensor(), T.Lambda(lambda x: torch.flatten(x))]))
device="cpu"
model = KAN(width=[28*28,10], grid=1, k=3).to(device)
train_data=train_dataset.train_data.view(-1, 28*28)[:1].to(device)
model(train_data)
model.plot(beta=10)とりあえずこのMNISTのKANを可視化したくてバッチサイズ1のデータをテストで流し込んでプロットさせたらこうなった。

KANはプロットすると、下が入力で上が出力になる。KANはノード間の重みの代わりに活性化関数を学習するので28*28=784個の活性化関数が10個の活性化関数に接続されることになる。確かに図はそのようになっている。上の方の山がかろうじて10個あることから、「たぶん10次元(0-9)に分類されてるな」とわかる程度だ。
しかし、KANは可視化しやすいというのがウリのはずだが実際に可視化するととんでもなく情報量が膨大になる。これなら重みを線の濃さで表現できるMLPの方が可視化に向いてる。
まあそれはいいとして、こんなのCPUで学習させたら何日かかるかわからない。
Efficient-KANが手っ取り早くMNISTが試せそうだったので試してみた。
まずデフォルトのネットワーク構造で学習させてみる。[784→64→10]という構造を持っていた。
$ python mnist.py
100%|█████████████████████████████████████████████████████████████████████| 938/938 [00:10<00:00, 91.73it/s, accuracy=0.875, loss=0.466, lr=0.001]
Epoch 1, Val Loss: 0.23239649485820418, Val Accuracy: 0.9334195859872612
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:05<00:00, 173.13it/s, accuracy=0.969, loss=0.13, lr=0.0008]
Epoch 2, Val Loss: 0.15888694078501336, Val Accuracy: 0.9533240445859873
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:05<00:00, 172.62it/s, accuracy=0.969, loss=0.0815, lr=0.00064]
Epoch 3, Val Loss: 0.1309393083552124, Val Accuracy: 0.9613853503184714
100%|████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 102.63it/s, accuracy=0.969, loss=0.0539, lr=0.000512]
Epoch 4, Val Loss: 0.11829017149284482, Val Accuracy: 0.9643710191082803
100%|███████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 98.83it/s, accuracy=0.938, loss=0.258, lr=0.00041]
Epoch 5, Val Loss: 0.10569664329263696, Val Accuracy: 0.9680533439490446
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 97.79it/s, accuracy=0.969, loss=0.139, lr=0.000328]
Epoch 6, Val Loss: 0.10239856768174062, Val Accuracy: 0.9686504777070064
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 101.66it/s, accuracy=1, loss=0.0456, lr=0.000262]
Epoch 7, Val Loss: 0.09748084997761235, Val Accuracy: 0.9691480891719745
100%|█████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 103.24it/s, accuracy=1, loss=0.0794, lr=0.00021]
Epoch 8, Val Loss: 0.09417708457045695, Val Accuracy: 0.9713375796178344
100%|████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 100.04it/s, accuracy=0.969, loss=0.0627, lr=0.000168]
Epoch 9, Val Loss: 0.0894929953052953, Val Accuracy: 0.9735270700636943
100%|█████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 98.75it/s, accuracy=1, loss=0.0393, lr=0.000134]
Epoch 10, Val Loss: 0.08749364090306316, Val Accuracy: 0.9728304140127388
わずか10エポックで97%の正解率はMLPと比べると遥かにいい。
ただ、MLPより「劇的に」ニューロン数が減らせるかというとそうとも思えない。
そこで、[784→10]という、一層のネットワークを試してみることにする。
まず比較のためMLPで試してみる。
# Define MLP
model = nn.Sequential(
nn.Linear(28*28, 10),
nn.SiLU(),
nn.Dropout(0.2),
)ここで活性化函数にSiLUを使っているのは、Efficient-KANの実装の中では、ベース活性化函数としてSiLUを使っていたから
class KAN(torch.nn.Module):
def __init__(
self,
layers_hidden,
grid_size=5,
spline_order=3,
scale_noise=0.1,
scale_base=1.0,
scale_spline=1.0,
base_activation=torch.nn.SiLU, # デフォルトのベース活性化函数
grid_eps=0.02,
grid_range=[-1, 1],
):ベース活性化函数使うなんて論文と違うじゃないかというツッコミも考えられたので実際のforwardを見るとあくまでベースはベースであって本体はBスプラインによる変調のようだった。
def forward(self, x: torch.Tensor):
assert x.dim() == 2 and x.size(1) == self.in_features
base_output = F.linear(self.base_activation(x), self.base_weight)
spline_output = F.linear(
self.b_splines(x).view(x.size(0), -1),
self.scaled_spline_weight.view(self.out_features, -1),
)
return base_output + spline_outputこのbase_weightが学習するパラメータが勾配持って学習したら台無しなのだが、大勢に影響はないということなのだろうか。
念の為base_weightを確認したらデフォルトで勾配を持つようになっていたので変更した。
self.base_weight = torch.nn.Parameter(
torch.Tensor(out_features, in_features),
requires_grad=False) #追加した
ソースを熟読すれば他のところで無効になってるのかもしれないが気持ち悪いので変更する。
さて、まずMLPで[784→10]という、かなり無謀な学習をさせてみる。
$ python mnist.py
100%|█████████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 204.94it/s, accuracy=0.75, loss=0.977, lr=0.001]
Epoch 1, Val Loss: 0.581572565113663, Val Accuracy: 0.8398686305732485
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 229.44it/s, accuracy=0.656, loss=1.15, lr=0.0008]
Epoch 2, Val Loss: 0.573439194992849, Val Accuracy: 0.8587778662420382
100%|███████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 212.71it/s, accuracy=0.75, loss=0.972, lr=0.00064]
Epoch 3, Val Loss: 0.578160053320751, Val Accuracy: 0.8652468152866242
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 223.26it/s, accuracy=0.625, loss=1.01, lr=0.000512]
Epoch 4, Val Loss: 0.5559488813019102, Val Accuracy: 0.8676353503184714
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 230.39it/s, accuracy=0.719, loss=0.841, lr=0.00041]
Epoch 5, Val Loss: 0.546095107865941, Val Accuracy: 0.8663415605095541
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 195.90it/s, accuracy=0.75, loss=0.717, lr=0.000328]
Epoch 6, Val Loss: 0.5473936533282517, Val Accuracy: 0.8656449044585988
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 194.20it/s, accuracy=0.656, loss=0.903, lr=0.000262]
Epoch 7, Val Loss: 0.5416050321736913, Val Accuracy: 0.8691281847133758
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:06<00:00, 154.63it/s, accuracy=0.719, loss=0.769, lr=0.00021]
Epoch 8, Val Loss: 0.5395803898572922, Val Accuracy: 0.8674363057324841
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 188.67it/s, accuracy=0.75, loss=0.805, lr=0.000168]
Epoch 9, Val Loss: 0.5387553306901531, Val Accuracy: 0.8611664012738853
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:06<00:00, 151.15it/s, accuracy=0.625, loss=1.11, lr=0.000134]
Epoch 10, Val Loss: 0.5412323092389258, Val Accuracy: 0.8618630573248408Val acc.が86%なのでこれでもまあまあ認識できるようだ。MLPの能力がすごい。
では、[784→10]の一層KANはどうか?
$ python mnist.py
100%|█████████████████████████████████████████████████████████████████████| 938/938 [00:05<00:00, 166.17it/s, accuracy=0.938, loss=0.32, lr=0.001]
Epoch 1, Val Loss: 0.3070013214519639, Val Accuracy: 0.9140127388535032
100%|███████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 194.33it/s, accuracy=0.938, loss=0.157, lr=0.0008]
Epoch 2, Val Loss: 0.2656145386136831, Val Accuracy: 0.925656847133758
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:05<00:00, 182.02it/s, accuracy=0.938, loss=0.209, lr=0.00064]
Epoch 3, Val Loss: 0.2534784731650903, Val Accuracy: 0.9305334394904459
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:05<00:00, 176.84it/s, accuracy=0.938, loss=0.191, lr=0.000512]
Epoch 4, Val Loss: 0.24346616279310102, Val Accuracy: 0.932921974522293
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 190.08it/s, accuracy=0.906, loss=0.142, lr=0.00041]
Epoch 5, Val Loss: 0.23831897605044447, Val Accuracy: 0.9346138535031847
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 197.24it/s, accuracy=0.938, loss=0.215, lr=0.000328]
Epoch 6, Val Loss: 0.23573331073946824, Val Accuracy: 0.9357085987261147
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 190.26it/s, accuracy=0.938, loss=0.193, lr=0.000262]
Epoch 7, Val Loss: 0.2327284945625883, Val Accuracy: 0.9360071656050956
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:05<00:00, 187.40it/s, accuracy=0.906, loss=0.304, lr=0.00021]
Epoch 8, Val Loss: 0.2325674150447557, Val Accuracy: 0.9363057324840764
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:05<00:00, 178.07it/s, accuracy=0.906, loss=0.201, lr=0.000168]
Epoch 9, Val Loss: 0.2308788239410159, Val Accuracy: 0.9361066878980892
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:05<00:00, 177.82it/s, accuracy=0.969, loss=0.116, lr=0.000134]
Epoch 10, Val Loss: 0.23000324939253033, Val Accuracy: 0.9360071656050956Val acc.で約94%。7.5ポイントも性能が向上した。
パラメータ数を比較すると、MLPが7850パラメータを学習するのに対し、KANは70560パラメータを学習するようになっていた。この原因は、要はBスプラインのパラメータを学習しなければならないのでニューロン数が全体的に少ない場合はMLPが有利ということかもしれない。
そこでニューロン数を多くしてやってみることにした。
たとえば、[784→500→10]にしてみた
model = nn.Sequential(
nn.Linear(28*28, 500),
nn.SiLU(),
nn.Dropout(0.2),
nn.Linear(500, 10),
nn.SiLU(),
nn.Dropout(0.2),
)
するとパラメータ数は397510。
params===
397510
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 190.09it/s, accuracy=0.688, loss=0.928, lr=0.001]
Epoch 1, Val Loss: 0.4149879728722724, Val Accuracy: 0.9188893312101911
100%|███████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 212.90it/s, accuracy=0.844, loss=0.445, lr=0.0008]
Epoch 2, Val Loss: 0.3643440361235552, Val Accuracy: 0.941281847133758
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 199.56it/s, accuracy=0.812, loss=0.734, lr=0.00064]
Epoch 3, Val Loss: 0.34475029198227414, Val Accuracy: 0.9507364649681529
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 188.28it/s, accuracy=0.625, loss=0.862, lr=0.000512]
Epoch 4, Val Loss: 0.3390040871254198, Val Accuracy: 0.9613853503184714
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 204.74it/s, accuracy=0.875, loss=0.485, lr=0.00041]
Epoch 5, Val Loss: 0.31339717670610756, Val Accuracy: 0.9500398089171974
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 209.48it/s, accuracy=0.844, loss=0.695, lr=0.000328]
Epoch 6, Val Loss: 0.30310007554900115, Val Accuracy: 0.958797770700637
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 206.81it/s, accuracy=0.688, loss=0.843, lr=0.000262]
Epoch 7, Val Loss: 0.30945386215569864, Val Accuracy: 0.9582006369426752
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 202.49it/s, accuracy=0.844, loss=0.552, lr=0.00021]
Epoch 8, Val Loss: 0.29922538711007235, Val Accuracy: 0.9682523885350318
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 214.39it/s, accuracy=0.75, loss=0.542, lr=0.000168]
Epoch 9, Val Loss: 0.2939902059496588, Val Accuracy: 0.9616839171974523
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 211.39it/s, accuracy=0.781, loss=0.69, lr=0.000134]
Epoch 10, Val Loss: 0.2918360729221326, Val Accuracy: 0.9645700636942676学習すると、さすがに表現力が向上したのでVal Acc.が96%まで上がった。
では同じ規模でKANでやってみる。
params===
3573000
100%|████████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 100.81it/s, accuracy=1, loss=0.053, lr=0.001]
Epoch 1, Val Loss: 0.11721298491261947, Val Accuracy: 0.9653662420382165
100%|███████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 95.90it/s, accuracy=1, loss=0.0333, lr=0.0008]
Epoch 2, Val Loss: 0.07909574071508921, Val Accuracy: 0.9747213375796179
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 101.39it/s, accuracy=1, loss=0.00657, lr=0.00064]
Epoch 3, Val Loss: 0.06712406823781591, Val Accuracy: 0.9781050955414012
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:08<00:00, 108.47it/s, accuracy=1, loss=0.0216, lr=0.000512]
Epoch 4, Val Loss: 0.06348170558006241, Val Accuracy: 0.9794984076433121
100%|█████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 98.27it/s, accuracy=1, loss=0.00512, lr=0.00041]
Epoch 5, Val Loss: 0.06118219589260644, Val Accuracy: 0.9809912420382165
100%|███████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 97.46it/s, accuracy=1, loss=0.000878, lr=0.000328]
Epoch 6, Val Loss: 0.0607668154769005, Val Accuracy: 0.9803941082802548
100%|█████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 97.25it/s, accuracy=1, loss=0.0118, lr=0.000262]
Epoch 7, Val Loss: 0.06263721009886149, Val Accuracy: 0.9809912420382165
100%|█████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 97.33it/s, accuracy=1, loss=0.00105, lr=0.00021]
Epoch 8, Val Loss: 0.06318917309165195, Val Accuracy: 0.9811902866242038
100%|███████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 96.81it/s, accuracy=1, loss=0.000843, lr=0.000168]
Epoch 9, Val Loss: 0.06382453592314456, Val Accuracy: 0.9812898089171974
100%|█████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 97.37it/s, accuracy=1, loss=0.0004, lr=0.000134]
Epoch 10, Val Loss: 0.06394987389574303, Val Accuracy: 0.9814888535031847
パラメータ数は10倍、性能差はもっと縮んだ(98.1%vs96.4%で1.7ポイント差)。学習に要した時間は一秒あたり97イテレーション。対して、MLPは200イテレーションである。
つまり、同規模の場合、学習すべきパラメータ数は10倍になり、性能差は縮んでいくという結果になった。ただ、これはプルーニング(不要な計算経路を省く)などの処理をしていないので元の論文との主張は異なるが、そもそもMLPだってプルーニングすればパラメータ数は減らせる。
これではKANが可哀想なので、なんとかいいところ探しをしてみる。
色々試した結果、[784→48→10]と、中間層を1/10くらいにすると、MLPより学習すべきパラメータ数が減って性能もそこまで落ちないと言うところに落ち着いた
$ python mnist.py
params===
343008
100%|█████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 97.59it/s, accuracy=0.781, loss=0.427, lr=0.001]
Epoch 1, Val Loss: 0.24688459103511776, Val Accuracy: 0.9307324840764332
100%|███████████████████████████████████████████████████████████████████| 938/938 [00:05<00:00, 168.31it/s, accuracy=0.938, loss=0.236, lr=0.0008]
Epoch 2, Val Loss: 0.18412869630061138, Val Accuracy: 0.9452627388535032
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 103.46it/s, accuracy=0.969, loss=0.136, lr=0.00064]
Epoch 3, Val Loss: 0.157038878774045, Val Accuracy: 0.9564092356687898
100%|██████████████████████████████████████████████████████████████████████| 938/938 [00:08<00:00, 107.79it/s, accuracy=1, loss=0.08, lr=0.000512]
Epoch 4, Val Loss: 0.14263682213617832, Val Accuracy: 0.9580015923566879
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:08<00:00, 113.28it/s, accuracy=0.969, loss=0.148, lr=0.00041]
Epoch 5, Val Loss: 0.136404256977046, Val Accuracy: 0.9594944267515924
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 103.91it/s, accuracy=1, loss=0.0459, lr=0.000328]
Epoch 6, Val Loss: 0.13178909891640922, Val Accuracy: 0.9602906050955414
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:08<00:00, 108.51it/s, accuracy=1, loss=0.0428, lr=0.000262]
Epoch 7, Val Loss: 0.12985625822886018, Val Accuracy: 0.9606886942675159
100%|█████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 100.95it/s, accuracy=1, loss=0.0218, lr=0.00021]
Epoch 8, Val Loss: 0.13025767565037533, Val Accuracy: 0.9613853503184714
100%|████████████████████████████████████████████████████████████████| 938/938 [00:08<00:00, 105.73it/s, accuracy=0.969, loss=0.0678, lr=0.000168]
Epoch 9, Val Loss: 0.12881349331838712, Val Accuracy: 0.9615843949044586
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 101.83it/s, accuracy=1, loss=0.0401, lr=0.000134]
Epoch 10, Val Loss: 0.1286716869235881, Val Accuracy: 0.9621815286624203
パラメータ数は343008で、MLPの397510と比べると54,502だけ少ない。
ただ、不思議なのはパラメータ数を減らしても学習速度そのものに違いが出ないことだ。減らしても変わらないと言うことは増やしても変わらないのかもしれない。意味がない計算になるが、中間層を逆に増やしてみる。
[784→5000→10]と、中間層をMLPの10倍にしてみたが、学習速度はイテレーションあたり95前後と変わらなかった。
$ python mnist.py
params===
35730000
100%|█████████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 95.53it/s, accuracy=1, loss=0.086, lr=0.001]
Epoch 1, Val Loss: 0.08896087055319955, Val Accuracy: 0.972531847133758
100%|███████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 97.88it/s, accuracy=0.969, loss=0.0685, lr=0.0008]
Epoch 2, Val Loss: 0.060707799126735185, Val Accuracy: 0.9804936305732485
100%|█████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 95.16it/s, accuracy=1, loss=0.00292, lr=0.00064]
Epoch 3, Val Loss: 0.051601558340439765, Val Accuracy: 0.9831807324840764
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 97.73it/s, accuracy=1, loss=0.00272, lr=0.000512]
Epoch 4, Val Loss: 0.05172473435464827, Val Accuracy: 0.9829816878980892
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 97.29it/s, accuracy=1, loss=0.000326, lr=0.00041]
Epoch 5, Val Loss: 0.04893327970698427, Val Accuracy: 0.9847730891719745
100%|███████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 95.75it/s, accuracy=1, loss=0.000443, lr=0.000328]
Epoch 6, Val Loss: 0.05073603255024696, Val Accuracy: 0.9847730891719745
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 97.25it/s, accuracy=1, loss=5.82e-5, lr=0.000262]
Epoch 7, Val Loss: 0.05140281643438919, Val Accuracy: 0.9846735668789809
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 97.76it/s, accuracy=1, loss=0.000699, lr=0.00021]
Epoch 8, Val Loss: 0.0526727176065348, Val Accuracy: 0.9848726114649682
100%|███████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 97.32it/s, accuracy=1, loss=0.000233, lr=0.000168]
Epoch 9, Val Loss: 0.054104735922620585, Val Accuracy: 0.9848726114649682
100%|█████████████████████████████████████████████████████████████████████| 938/938 [00:09<00:00, 97.58it/s, accuracy=1, loss=0.0001, lr=0.000134]
Epoch 10, Val Loss: 0.05442965913326809, Val Accuracy: 0.9851711783439491性能も98.5%と大幅に上がった。
しかし、どうしてもKANに花を持たせてやりたい。このままでは気の毒すぎる。というわけで、MLPは中間層が3層以上になると性能が低下することはわかっているのだが、KANに3層以上持たせてみて性能劣化を見てみたい。
MLPを[768→100→100→100→10]として学習させてみた。
$ python mnist.py
params===
99710
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 189.99it/s, accuracy=0.906, loss=0.374, lr=0.001]
Epoch 1, Val Loss: 0.21807477169426953, Val Accuracy: 0.9448646496815286
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 194.73it/s, accuracy=0.719, loss=0.73, lr=0.0008]
Epoch 2, Val Loss: 0.18344108907470277, Val Accuracy: 0.9565087579617835
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 195.80it/s, accuracy=0.812, loss=0.516, lr=0.00064]
Epoch 3, Val Loss: 0.1484194153943544, Val Accuracy: 0.9618829617834395
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 194.65it/s, accuracy=0.938, loss=0.34, lr=0.000512]
Epoch 4, Val Loss: 0.12358221693326286, Val Accuracy: 0.9703423566878981
100%|███████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 195.67it/s, accuracy=0.875, loss=0.44, lr=0.00041]
Epoch 5, Val Loss: 0.12105357945024682, Val Accuracy: 0.970640923566879
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:05<00:00, 186.88it/s, accuracy=0.844, loss=0.404, lr=0.000328]
Epoch 6, Val Loss: 0.11414918082078124, Val Accuracy: 0.9723328025477707
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 192.11it/s, accuracy=0.781, loss=0.808, lr=0.000262]
Epoch 7, Val Loss: 0.11092091521254153, Val Accuracy: 0.9726313694267515
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 199.71it/s, accuracy=0.875, loss=0.452, lr=0.00021]
Epoch 8, Val Loss: 0.10083114807968543, Val Accuracy: 0.9749203821656051
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 191.24it/s, accuracy=0.969, loss=0.334, lr=0.000168]
Epoch 9, Val Loss: 0.1008846338684107, Val Accuracy: 0.9751194267515924
100%|█████████████████████████████████████████████████████████████████| 938/938 [00:04<00:00, 193.37it/s, accuracy=0.875, loss=0.379, lr=0.000134]
Epoch 10, Val Loss: 0.10081927614600937, Val Accuracy: 0.9753184713375797
やはり規模の割に性能は上がらない。Val Acc.は97.5%止まりになる。
ではKANはどうか?
こんなKANを作った
model = KAN([28 * 28,100,100,100, 10])動作はこれ
$ python mnist.py
params===
894600
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:17<00:00, 54.82it/s, accuracy=0.969, loss=0.0787, lr=0.001]
Epoch 1, Val Loss: 0.1439598813789428, Val Accuracy: 0.9568073248407644
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:17<00:00, 54.38it/s, accuracy=0.969, loss=0.154, lr=0.0008]
Epoch 2, Val Loss: 0.10574899483946668, Val Accuracy: 0.9685509554140127
100%|██████████████████████████████████████████████████████████████████| 938/938 [00:16<00:00, 55.21it/s, accuracy=0.969, loss=0.0905, lr=0.00064]
Epoch 3, Val Loss: 0.09063443052322918, Val Accuracy: 0.9735270700636943
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:16<00:00, 55.21it/s, accuracy=1, loss=0.00262, lr=0.000512]
Epoch 4, Val Loss: 0.09127345391375659, Val Accuracy: 0.9746218152866242
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:17<00:00, 55.01it/s, accuracy=1, loss=0.000612, lr=0.00041]
Epoch 5, Val Loss: 0.08834755031156923, Val Accuracy: 0.9772093949044586
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:17<00:00, 55.16it/s, accuracy=1, loss=0.00118, lr=0.000328]
Epoch 6, Val Loss: 0.09342297531648985, Val Accuracy: 0.9764132165605095
100%|███████████████████████████████████████████████████████████████████| 938/938 [00:17<00:00, 54.94it/s, accuracy=1, loss=0.000798, lr=0.000262]
Epoch 7, Val Loss: 0.0920320018102392, Val Accuracy: 0.9773089171974523
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:16<00:00, 55.35it/s, accuracy=1, loss=0.000145, lr=0.00021]
Epoch 8, Val Loss: 0.0961961685802432, Val Accuracy: 0.9772093949044586
100%|███████████████████████████████████████████████████████████████████| 938/938 [00:17<00:00, 54.92it/s, accuracy=1, loss=0.000266, lr=0.000168]
Epoch 9, Val Loss: 0.09885428030407453, Val Accuracy: 0.9769108280254777
100%|████████████████████████████████████████████████████████████████████| 938/938 [00:17<00:00, 55.00it/s, accuracy=1, loss=0.00131, lr=0.000134]
Epoch 10, Val Loss: 0.10233595652443099, Val Accuracy: 0.9773089171974523Val Acc. 97.7%は立派だが、正直、KANも3層以上の中間層を持てないのではないかという疑念が湧いてきた。lossはまだ残っているがAccが1なので、MNISTよりももう少し難しい問題で調べてみないとKANの能力の限界は測れない。
考察
結局、KANはMLPより学習すべきパラメータ数が10倍多く、動作は二倍遅く、精度は数ポイントしか上がらないということがわかった。少なくとも現時点のハードとソフトウェアスタックでは。
どうしてこんなことになったのか?
これは、KANの開発者が主に科学技術計算や函数近似を念頭に置いてKANを設計したことに原因がありそうだ。
KANの公式サンプルはほぼ全て高次函数を学習するものになっている。教師なし学習とデータ分類のサンプルもあるが、ごく初歩的なもので、ディープラーニング以前によく使われていたものだ。
そのレベルの比較では、KANはかなりの高性能を発揮する。実際、MNISTの学習においても、trainではAcc=100%になるのだ。
しかし、ディープラーニングが扱う主なテーマは、函数近似ではなく、函数近似が途方もなく難しい、現実のデータである。
ディープラーニングが「知りたい」のは「不連続かつ不規則なデータの中から真実めいたものを見つけること」であって、「不確実なデータを関数として近似すること」ではない。関数のように見えるのは副作用だ。
もしも複雑な科学技術計算を近似することが目的ならKANは十分威力を発揮する可能性があるが、ディープラーニングが扱うのはあくまでも自然界、人間界のデータである。人間界は当の人間たちにとっても、完全に予測できない複雑な社会や心理状況を反映しており、自然界に至っては人間はほとんど無知である。哲学者や科学者たちが数千年の時をかけて紡いできた科学体系などは、自然界のごく一部を自分たちのわかりやすいように解釈した"近似"に過ぎない。
主に扱いたい問題の主体が違うので、自然界の問題をすべて数学的に近似できると思い込んでしまったのが、根本的な原因かもしれない。
ただ、擁護する点があるとすれば、そもそも画像分類の分野はMLPがある程度の性能を発揮したものの、CNN(畳み込みニューラルネットワーク)が再発見されるまで十分な性能があると評価されていなかった。そもそもMLPは、いわば「失われた技術」だったのである。また、KANの活性化函数に用いるBスプラインに特化したハードウェアまたは学習アルゴリズムが発見されれば、KANが再評価される可能性はあるだろう。
今回、Fourier-KANの性質は試していないので、Efficient-KAN特有の問題でパラメータ数が多過ぎたりするかもしれないし、Fourier-KANで実験すればもっとちがった結果が導かれる可能性はある。しかしKANがMLPに比べて劇的に良いモノであると現時点で断言することは難しそうだ。