人気の記事一覧
ローカルLLMの長文推論、メモリ使用量を節約する方法:KVキャッシュの量子化
[Mac]Meta-Llama-3-8Bをgguf変換して量子化してみました
【実験】Claude 3 Opusに論文を読ませて、要約させる:BitNetとBMTの比較
スパース推定アルゴリズムと量子化技術による大規模言語モデルのデータ圧縮
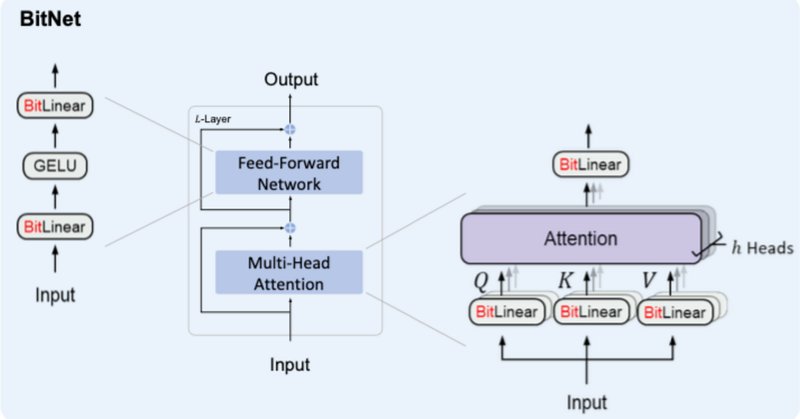
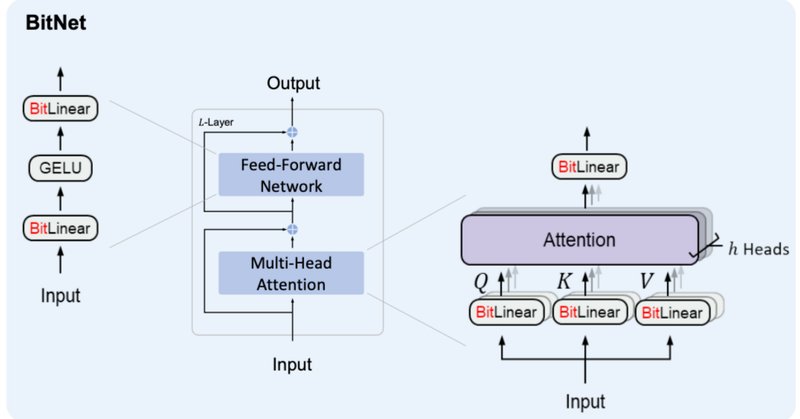
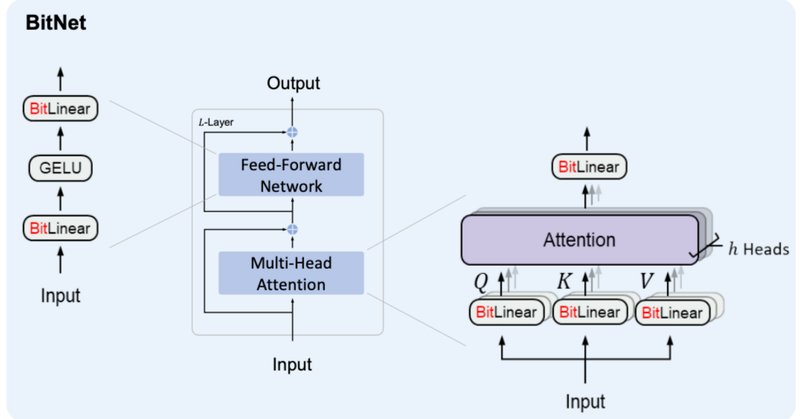
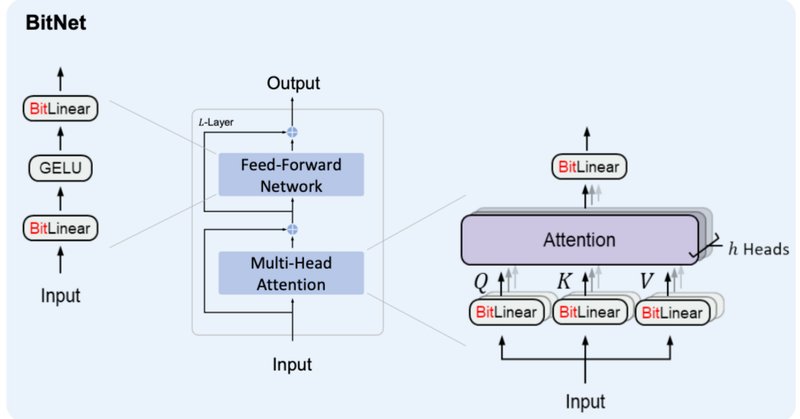
BitNetにおけるSTE(Straight-Through Estimator)の実装
llama.cppでHuggingFaceモデルを4bit量子化😚【GoogleColab】/大塚
【生成AI】入門者としておさえておきたい「大規模言語モデル(LLM)の現状の全体感」(2/3)
BitNet&BitNet b158の実装:参照まとめ
【ローカルLLM】Mixtral-8x7bをllama.cppで試す
llama.cppをローカル起動してFastAPIでAPI化
日本語対応の大規模言語モデル(LLM)をローカル環境で試す:VRAM 8GBの挑戦
Google ColabでQLoRA したLlama-3をMLXモデル(macOS)へ変換する