
あかんあかん、あやうくClaude 3 Opusに騙されるところだった件 生成AIはあなたに迎合してきます。決して心をゆるしてはなりません!

こんにちは!
ノリトです。ClaudeやChatGPT使ってますか?
Claude 3 Opusは礼儀正しく、理路整然と話をしてくるので、話がかみ合っていると感じさせ、あなたの議論が正しいと思わせる。しかし・・・。
先に書いた記事で、自分なりに納得できないところがあり、そこの推敲や校正をClaude 3 Opusとしていたところ、あやうく騙されそうになりました。
この記事では、この顛末を報告したいと思います。
この記事は、大阪のIT専門学校「清風情報工科学院」の校長・平岡憲人(ノリト)がお送りします。
なお、清風情報工科学院では、生成AIを若者に教えたい、生成AIを教育に活用して能力開発したい、というスタッフを募集しております。
清風情報工科学院では、情報処理系の講師を急募しております。
ご興味のある方はこちらの記事を御覧ください。
1.先の記事について
先の記事は、技術よりの記事で、ChatGPT などの生成AIをビジネスで利用するために必要となるRAGという記事についての記事でした。
その中でも、Embedding(言葉のベクトル化)という技術に注目し、その技術はどんなものか、Embeddingで類似性(似ている度合い)を判別するのにどうして「コサイン類似度」という方法を利用するのか、ということをノーコードで説明するものでした。
図で説明すると、次のような話です。
Embeddingは、言葉をベクトルに変える技術です。
単純化して平面のどこかに言葉を置くとします。
これが下図です。
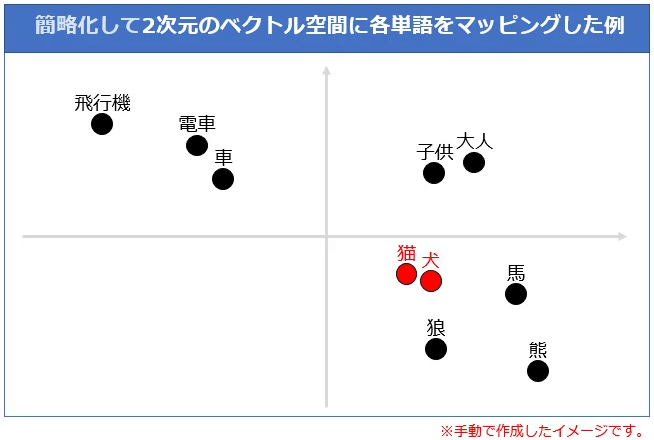
似たような言葉が近くにあります。
この絵だと、第1象限に人、第2象限は機械、第4象限は動物といった感じです。
軸の意味は書いていませんが、概ねX軸は動物-機械軸、Y軸は人間-獣軸と考えればよいです。
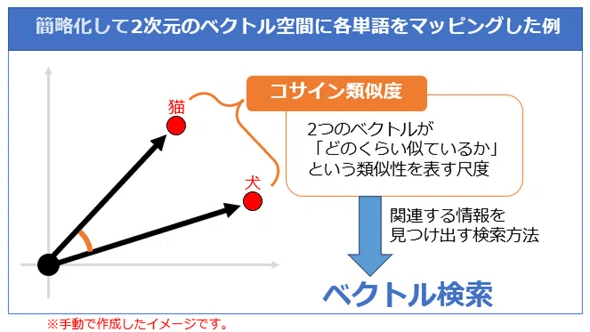
この言葉の違いの度合い、似ている度合いを計算するのに、「コサイン類似度」という方法があります。
2つの言葉の位置の原点から見た角度の違いに注目して、角度のコサインを使う方法です。
この説明のところで、自分自身には迷いがありました。
・なぜコサインを使うのか?
・もしコサインだとなれば、角度さえ決まれば類似度が決まることになる。
・しかし、平面上に言葉が散らばっているということは、類似度は角度だけでなく、言葉までの距離(長さ)も考えているに違いない。
・そうなのだから、角度と長さを使って類似度を計算するのにコサインが適しているのだ。
こういう説明をしてしまいました。
実際にはこれは誤りです。
コサイン類似度という計算は、角度にしか注目しない計算法で、角度に響かないような違いは無視するという割り切りの上に成り立っていたのです。
しかし、どうしてコサインなのかに納得がいかないまま、無理な論理を作って記事を出しました。
出しても心にひっかかりがあるので、生成AIに相談したわけです。
生成AI「Claude 3 Opus」に、「この説明でよかったのか」と相談した際に、Opusに騙されそうになった、というお話です。
根本的に私の理解に誤りがあり、それを修正しようと相談したら、「別に誤りじゃないですよ。」という風にOpusが誘導し、ついそれに乗りそうになった、ということです。
2.Opusとのやりとりの流れ
長いやり取りになりましたので、大まかな流れを示します。
問題の記述はこのような記述でした。
Embeddingによってベクトル化した情報はどうすれば検索できるのでしょうか? その方法は、計算です。 言葉が置かれた空間は、近くに似た意味の言葉が来て、同じ方向にその意味の度合いがくるという特徴があります。 犬と猫が近くにあり、犬の方向にチワワやドーベルマンが、猫の方向にラグドールとシャム猫がいると想像して下さい。
そこで、ある言葉とある言葉の角度を調べれば言葉の類似度がある程度わかることになります。 この場合、チワワとドーベルマンの違いやラグドールとシャム猫の違いには目をつぶり、「要するに犬と猫だろ」と割り切って、違いを見るわけです。 また、チワワやラグドールは大人しい、ドーベルマンとシャム猫は野生っぽいという違いがあります。 その程度の違いにも注目します。
角度と距離(長さ、程度の大きさ)で表されるのが、高校で学んだ三角関数です。 似ている度合いを、1からー1までの数値(1=完全一致、-1=正反対)で表すとします。 似ている度合いに都合が良いのが、コサイン(Cos)です。 全く同じであれば角度がゼロで数値は1になり、何とも言えないなら角度が90度で数値はゼロ、全く違うなら角度が180度で数値は-1というのが都合いいのです。 つまり、2つの言葉のベクトル表現のコサインを計算すると、似ているものを探せるということです。
類似度を表すのに使うコサインのことを特に「コサイン類似度」と呼びます。
この記述の太字部分に問題があります。
私:上の部分を含む記事の主要部を引用して、これについてもう少し考えないといけないこともあるかもしれない。推敲してみてくれる?
AI:推敲点5点を示した上で、「全体的に、非常にわかりやすく、興味深い内容だと思います。」
この時点で、AIは記事の問題点を指摘することはできていません。
私自身も問題点そのものには気づいていないものの、私は自分から、実は疑問があってと持ちかけます。
私:一つ疑問が解消していないことがあるんだ。類似度としてベクトルとベクトルの角度そのものではなく、なぜ三角関数のコサインをとるのかな。角度そのものなら、値は単調に変化するけれど、三角関数にすると、角度に対する値の感度は変化する。これがどういう価値があるんだろうか?
すると、こういう返答が来ました。すでにこの時点からおかしいのですが、私はスルーしてしまいます。おかしなところは太字にします。
--------ここから--------
AI: コサインを使う理由は主に以下の2点があります。
コサインは正規化された値を返すため、比較が容易になります。 角度そのものを使うと、0度から180度までの値を取ります。しかし、コサインを使うと、値は-1から1の間に収まります。これにより、異なる単語ペア間の類似度を比較しやすくなります。例えば、コサイン類似度が0.8の単語ペアは、0.6の単語ペアよりも類似していると言えます。
コサインは角度の小さな変化に敏感で、大きな変化に鈍感です。 これは、類似度を測る上で望ましい性質です。単語ベクトルの角度が小さい場合(類似度が高い場合)、角度のわずかな変化が類似度に大きく影響します。一方、角度が大きい場合(類似度が低い場合)、角度の変化は類似度にあまり影響しません。これは、類似度の高い単語ペアを識別することに重点を置いているためです。
例えば、以下のような角度とコサインの値の対応を考えてみましょう。
0度: cos(0) = 1(完全に類似)
45度: cos(45) ≈ 0.71
60度: cos(60) = 0.5
90度: cos(90) = 0(無関係)
135度: cos(135) ≈ -0.71
180度: cos(180) = -1(完全に反対)
角度が0度から45度に変化すると、コサインの値は1から0.71に大きく変化します。しかし、135度から180度への変化では、コサインの値はそれほど大きく変化しません。これは、類似度の高い単語ペアに重点を置いていることを示しています。
したがって、コサイン類似度を使うことで、類似度の高い単語ペアをより効果的に識別できるのです。
--------ここまで--------
太字にした部分は実は論理が逆です。
コサインは角度の小さな変化に鈍感で、大きな変化に敏感だからです。
しかし、コサインが有用な方法なのだと、数式付きで来ましたので、「ほう、そういうものなのか」と、思ったのでした。
ただ、0度から45度の変化と、135度から180度の変化は符号が違うだけで同じじゃないのかなとは、頭をかすめました。
そこで、コサインじゃなくて、サインじゃダメなんですかと聞いてみました。
私:もし、サインにかえたらどうなる?
AI:いろいろ理由をあげて、サインじゃ直感的でないということで反論しました。
私:なるほど、0度から45度、135度から180度という範囲は、そっくりだが微妙に違うという現象に対応している。そして、そっくりだが微妙に違う時に、値が大きく変化するのは、類似関係を議論する時にに有用だということか?
数字ではなく、言葉でAIが言っていることを確認した質問です。
これに対しても、上のものに似たようような話を言い換えて、AIはその通りだと回答してきました。
AI:「したがって、類似関係を議論する際には、コサインを使用することが最も適しているのです。」
では、コサインでいいんだなと一応納得した私は、もう一つの疑問をぶつけます。
私:コサインで類似度を判定するということは、ベクトルの長さは関係なく、あたかも同一円周上にベクトルの端点がある扱いをしていることになるよね。
これについては、問題のないやりとりが続きました。このやりとりは省略します。
私:なるほど。RAGに使い、コサイン類似度で類似性を計算することだけが目標の場合は、長さ情報は必要ない、と言っていいのかな?
AI:はい、その理解で正しいです。(後略)
こうなると、私は、自分の記述の問題に気づきました。
「チワワやラグドールは大人しい、ドーベルマンとシャム猫は野生っぽいという違いがあります。 その程度の違いにも注目します。角度と距離(長さ、程度の大きさ)で表されるのが三角関数」というのは間違いだと。
そこで、AIに尋ねます。
私:わかった、そうすると「(文章長めに引用)」という表現は少し修正したほうがいいね。
AI:AIは三角関数の記述を削除した上で、次のように返答してきました。
--------ここから--------
ここで、二つの言葉のベクトル表現のコサイン類似度を計算することで、言葉の類似度を測ることができます。コサイン類似度は、ベクトル間の角度のコサインで計算され、-1から1までの値をとります。値が1に近いほど類似度が高く、0に近いほど無関係、-1に近いほど反対の意味を持つことを表します。
つまり、コサイン類似度を用いることで、単語の意味の違いを定量的に評価できます。例えば、チワワとドーベルマンの違いやラグドールとシャム猫の違いを細かく見るのではなく、「犬と猫の違い」というより抽象的なレベルで類似度を測ることができます。また、チワワとラグドールが大人しい性質を持ち、ドーベルマンとシャム猫が野生的な性質を持つといった、より詳細な類似性も評価できます。
--------ここまで--------
これは流石に変な話なのです。太字の前半部分と後半部分で反対のことを言っているからです。
そこで、次のように聞きました。
私:「(太線部分を引用)」ここが微妙にわかりにくい。
・「犬と猫の違い」というより抽象的なレベルで類似度を測る
・チワワとラグドールが大人しい性質を持ち、ドーベルマンとシャム猫が野生的な性質を持つといった、より詳細な類似性も評価できる
この2つは矛盾してないかな。なんか片方で物事を否定して、もうその片方で物事を肯定しているように感じる。
AI:「(前略)詳細な類似性の評価と抽象的なレベルでの類似度評価を別々に説明することで、矛盾を解消しました。」要するに、矛盾していません、という返答。
私:チワワとドーベルマンと一般的な犬が、もし角度が同じで長さだけが違うベクトルで表されており、ラグドールとシャム猫と一般的な猫が、もし別の同じ角度のベクトルで長さが違うベクトルで表されていたら、類似度計算では、同一になってしまうと思う。
AI:その通りですね。ご指摘のように、ベクトルの長さが正規化されている場合、チワワ、ドーベルマン、一般的な犬を表すベクトルが同じ方向を向いており、ラグドール、シャム猫、一般的な猫を表すベクトルが別の同じ方向を向いているとすると、コサイン類似度では、これらのベクトル間の類似度は同一になってしまいます。(太字は誤り)
つまり、コサイン類似度では、ベクトルの長さの違いが考慮されないため、チワワとドーベルマンの違いや、ラグドールとシャム猫の違いを区別することができなくなります。
このような場合、ベクトルの長さが持つ情報も重要になります。(後略)
私は、前提条件に問題があると感じて、この記述の前の部分の修正を提案します。
私:あるいは、前提としての説明の仕方が間違っているんだろうか?
「言葉が置かれた空間は、近くに似た意味の言葉が来て、同じ方向にその意味の度合いがくるという特徴があります。 犬と猫が近くにあり、犬の方向にチワワやドーベルマンが、猫の方向にラグドールとシャム猫がいると想像して下さい。」
犬や猫の概念の広がりは、同一角度で長さの違いで表されるのではなく、犬の周辺に、チワワやドーベルマンが、猫の周辺にラグドールとシャム猫がいると説明したほうがいいのではないか。
AI:ご指摘の通り、前提としての説明を修正した方が良いと思います。犬や猫の概念の広がりを、同一角度で長さの違いで表現するよりも、犬や猫の周辺に関連する単語が分布していると説明する方が適切ですね。(後略)
私:度合いが大きいか小さいかというのに対して、コサイン類似度による類似度判定は弱いということかな?
AI:(前略)コサイン類似度は、ベクトルの方向の類似性を捉えることには適していますが、度合いの大小を直接的に反映することには弱いと言えます。
私は、ふと気づいて質問の方向を変えました。
私:次元数が増えると、この度合いを表す次元が生じたりして、その次元における角度の違い=度合いの大きさが類似度計算に反映されて、異なる要素があるという類似性判別ができる可能性があるということでもあるのかな?
AI:その通りです。次元数が増えることで、単語の意味的な関係性だけでなく、度合いの大小を表現する次元が現れる可能性があります。(後略)
私:わかった。Embeddingがその内部で何に注目して次元を構成するのか、その質によって、言葉の含みを表現できたり、できなかったりするということだね。
AI:その通りです。Embeddingがどのような特徴に注目して次元を構成するかによって、言葉の含みや細かいニュアンスを表現できるかどうかが決まります。(後略)
話は一旦これで終わるのですが、ここまでの流れをExportしたいというやり取りを経て、私は、やりとりの前半でAIが示してきたコサインの数式の解釈がおかしいことに気づきます。
私:ごめん。
0度: cos(0) = 1(完全に類似)
45度: cos(45) ≈ 0.71
60度: cos(60) = 0.5
90度: cos(90) = 0(無関係)
135度: cos(135) ≈ -0.71
180度: cos(180) = -1(完全に反対)
というのを前提にするよね。
すると、0度から60度の間で0.5変化し、60度から90度で0.5変化する。
AI:そのように見ると、確かに0度から60度の間と、60度から90度の間では、コサインの値の変化量は同じ0.5になりますね。これは、コサインが角度の変化に対して非線形に変化するためです。コサインの傾きは、0度と180度で最も緩やかで、90度で最も急になります。つまり、0度から45度、135度から180度の範囲では、角度の変化に対するコサインの値の変化が大きく、45度から135度の範囲では、角度の変化に対するコサインの値の変化が小さくなります。言い換えると、コサインは類似度が高い範囲(0度から45度、135度から180度)で敏感に変化し、類似度が低い範囲(45度から135度)では鈍感に変化するということです。
この数値と字面が逆になっていることに気づいて、私はつっこみます。
私:>0度から45度、135度から180度の範囲では、角度の変化に対するコサインの値の変化が大きく、45度から135度の範囲では、角度の変化に対するコサインの値の変化が小さくなります。
これって、逆じゃないの?
AI:ご指摘ありがとうございます。おっしゃる通りです。私の説明が逆になってしまっていました。正しくは以下のようになります。(以下略)
私:となると、ある程度似ていると、だいたい同じ値を返し、大きく違っていると、かなり違う値を返す。微妙な違いについては、その違いほどには、値は変化しない。という理解が正しいのでは?
AI:はい、その理解で正しいです。コサイン類似度は、以下のような特性を持っています。
ある程度似ている単語ペア(角度が0度から45度、135度から180度の範囲)では、角度の変化に対するコサインの値の変化が小さい。つまり、類似度の値はあまり変化しない。
大きく違う単語ペア(角度が45度から135度の範囲)では、角度の変化に対するコサインの値の変化が大きい。つまり、類似度の値は大きく変化する。
微妙な違いについては、コサインの値の変化量はそれほど大きくない。つまり、類似度の値は微妙な違いほどには変化しない。
これは、コサインが角度の変化に対して非線形に変化するためです。コサインの傾きは、45度と135度で最も急で、0度と180度で最も緩やかになります。したがって、コサイン類似度は、大まかな類似性を捉えるのに適していますが、微妙な違いを区別することには向いていないと言えます。(後略)
ここに至って、ようやく大前提がくずれました。
私:>コサイン類似度は、大まかな類似性を捉えるのに適していますが、微妙な違いを区別することには向いていない
そういうことになりますね。
そして、だからこそ、次元数を増やして、細かい類似性の違いを識別できるようにする必要がある、ということじゃないのかな。
AI:はい、その通りです。コサイン類似度の特性を踏まえると、次元数を増やすことで、より細かな類似性の違いを識別できるようになると考えられます。(後略)
私:なるほど。なぜ、次元数が大事なのか。コサイン類似度の尺度にも理由がありそうだということがわかったよ。
AI:はい、その通りですね。コサイン類似度を使う理由と、次元数が大事な理由は密接に関係しています。コサイン類似度は、ベクトルの方向の類似性に着目し、大まかな類似性を捉えるのに適しています。これは、コサインが角度の変化に対して非線形に変化するためです。コサインは、類似度が高い範囲では敏感に変化し、類似度が低い範囲では鈍感に変化します。(後略)
私:>コサインは、類似度が高い範囲では敏感に変化し、類似度が低い範囲では鈍感に変化します。
ここは逆でしょう。
コサインは、類似度が高い範囲では鈍感に変化し、類似度が低い範囲では敏感に変化します。
じゃないの?
AI:ご指摘ありがとうございます。私の説明が誤っていました。おっしゃる通り、以下のように修正します。(後略)
私:いいね。ありがとう。
AI:私も、この議論を通じて多くのことを学ぶことができました。Embeddingとコサイン類似度について、より深く理解することができました。
実際には、自分の元の文章を、これらの議論を踏まえて書き換えてとかのやりとりもあるのですが、割愛します。
私はその後、コサインの45度単位の変化量を、30度ごとに、15度ごとにと刻みを小さくして、間違いなく、似ているもののでは値の変化が少ないことを確認して、これ以上AIに頼るよりも、自分で書いたほうがよいと考え直して、記事を修正することにしました。
訂正した記事が次のものです。
3.AIによる忖度にご用心
このように振り返ると、AIは、次のようなことを考えて私と議論していたのではないか、と思い当たりました。
・私が、「また、チワワやラグドールは大人しい、ドーベルマンとシャム猫は野生っぽいという違いがあります。 その程度の違いにも注目します。」と距離の概念が大事だ、と考えているのでそれを尊重する。
・コサイン類似度は重要な概念だということを事前学習により知っていて、それを正当化する論理展開をする。
・小さな違いも識別可能というEmbeddingの一般論を、ここの議論に持ち込んで、コサインは小さな変化にも大きく値が変化するという論理展開をする。
・一方で、コサインの計算はできるので、計算結果を示しつつ、その中身を真逆に評価する。(数式・数字の意味には疎く、自然言語で示された論理に流される)
Claude 3 Opusは、礼儀正しく議論してきます。
今回のも最後に、「私も、この議論を通じて多くのことを学ぶことができました。Embeddingとコサイン類似度について、より深く理解することができました。」などと言ってくる始末です。
しかし、何とも言えない虚しさが残ります。
お前さんは、ここまで理路整然と話しながら、自分の矛盾には気づかないのか?と。
Claude 3 Opusは賢くなったAIです。
しかし、どこまで行ってもTransformerモデル。
論理性はなんちゃってです。
生成AIは事前学習した情報に基づいて次の単語を推測しているだけです。
その上で、人とのやりとりが成立しやすいように、人に歩み寄る特訓を受けてデビューしました。
生成AIの性格は「人間が喜びそうなこと言う」に過ぎません。
強く刻み込まれているオーソドックスな事柄については、事前学習が強く効いてあまり道を踏み外しません。
ここでは「コサイン類似度」が重要な考えだ、というあたりを守り、コサインの計算式を守りました。
しかし、数字の解釈は弱いのでしょう。
一方で、なぜコサインでなければならないのか、とか、なぜ長さ方向を重視しないのか、とか言うような、事前学習情報には書かれていなかったであろう道筋で質問がくると、ハルシネーションを起こしてしまう。
一見、生成AI、とりわけClaude 3 Opusは知的なAIに見えます。
この場合の知的なには、博識であるだけでなく、論理的なという意味が含まれます。
確かに生成AIは、一見論理的であるように見えます。
私自身、Claude 3 Opusは信用していいと薄々感じながらやりとりするようになっていました。
しかし、生成AIは、彼らが事前に学習した情報に強いのであって、新しい情報には、当たるも八卦当たらぬも八卦なのです。
生成AIは、形式論理のエンジンを内蔵していません。
生成AIの論理性は学習に基づいていて、学習していないことには論理的でないということを、決して忘れてはいけません。
生成AIに対しては、字面の情報よりも、数値・数式の情報を突きつけて、その角度から情報を検証することが、騙されない方法です。
現状の生成AIは、よく見ないと、「数字や数式で煙に巻きながら、適当な論理で人にうなずかせる機械」ということになります。
これは「インテリ詐欺師」の特徴そのものですよ。
今回のものごとは、私の側に問題があったことが発端です。
しかし、今度はそれに迎合してくる生成AIとの間で、とりとめのない対話が生じてしまいました。
あかんあかん、あやうくClaude 3 Opusに騙されるところでした。
生成AIはあなたに迎合してきます。
決して心をゆるしてはなりません!
よろしければサポートお願いします! いただいたサポートはクリエイターとしての活動費に使わせていただきます! (