
llama.cppのserver.exeに起動オプションを送って起動できるPythonコードを公開しました。

残念ながら、2024年4月6日時点のKoboldcppではc4ai-command-r-v01-GGUFが起動できないので、llama.cppで起動するしか無いのですが、cuiで動かすのは嫌なので、server.exeでブラウザーで遊ぶわけですが、いちいち起動因数を付けてコマンドプロンプトなどにコピペするのも面倒なので、Claude3-Opusと相談しながら、簡単にするコードを作成しました。
追記:githubにpyqt5版とともにtkinter版を公開したので、pyqt5追加したくない人はそちらをどうぞ。
必須環境
前提として、Pythonがインストールされている環境である必要があります。
また、以下のライブラリをインストールしていない場合はインストールする必要があります。
pip install pyqt5pyqt5はGUI用のライブラリです。
Pythonコード
import sys
import os
import json
import subprocess
import webbrowser
from PyQt5.QtWidgets import QApplication, QWidget, QLabel, QLineEdit, QPushButton, QVBoxLayout, QFileDialog
CONFIG_FILE = 'llama_launcher_config.json'
class LlamaLauncherApp(QWidget):
def __init__(self):
super().__init__()
self.config = self.loadConfig()
self.initUI()
def initUI(self):
self.setWindowTitle('Llama.cpp Server Launcher')
self.setGeometry(100, 100, 400, 400)
layout = QVBoxLayout()
self.serverLabel = QLabel('Server Executable:')
self.serverLineEdit = QLineEdit(self.config.get('server_path', ''))
self.serverButton = QPushButton('Browse...')
self.serverButton.clicked.connect(self.browseServer)
layout.addWidget(self.serverLabel)
layout.addWidget(self.serverLineEdit)
layout.addWidget(self.serverButton)
self.modelLabel = QLabel('Model:')
self.modelLineEdit = QLineEdit(self.config.get('model_path', ''))
self.modelButton = QPushButton('Browse...')
self.modelButton.clicked.connect(self.browseModel)
layout.addWidget(self.modelLabel)
layout.addWidget(self.modelLineEdit)
layout.addWidget(self.modelButton)
self.threadsLabel = QLabel('Threads (-t):')
self.threadsLineEdit = QLineEdit(self.config.get('threads', '4'))
layout.addWidget(self.threadsLabel)
layout.addWidget(self.threadsLineEdit)
self.portLabel = QLabel('Port:')
self.portLineEdit = QLineEdit(self.config.get('port', '8080'))
layout.addWidget(self.portLabel)
layout.addWidget(self.portLineEdit)
self.nPredictLabel = QLabel('Max Tokens to Generate (-n):')
self.nPredictLineEdit = QLineEdit(self.config.get('n_predict', '512'))
layout.addWidget(self.nPredictLabel)
layout.addWidget(self.nPredictLineEdit)
self.nCtxLabel = QLabel('Context Size (-c):')
self.nCtxLineEdit = QLineEdit(self.config.get('n_ctx', '512'))
layout.addWidget(self.nCtxLabel)
layout.addWidget(self.nCtxLineEdit)
self.nGpuLayersLabel = QLabel('GPU Layers (-ngl):')
self.nGpuLayersLineEdit = QLineEdit(self.config.get('n_gpu_layers', '0'))
layout.addWidget(self.nGpuLayersLabel)
layout.addWidget(self.nGpuLayersLineEdit)
self.launchButton = QPushButton('Launch Server')
self.launchButton.clicked.connect(self.launchServer)
layout.addWidget(self.launchButton)
self.setLayout(layout)
def browseServer(self):
options = QFileDialog.Options()
fileName, _ = QFileDialog.getOpenFileName(self, "Select Server Executable", "", "Executable Files (*.exe)", options=options)
if fileName:
self.serverLineEdit.setText(fileName)
self.config['server_path'] = fileName
self.saveConfig()
def browseModel(self):
options = QFileDialog.Options()
fileName, _ = QFileDialog.getOpenFileName(self, "Select Model", "", "All Files (*)", options=options)
if fileName:
self.modelLineEdit.setText(fileName)
self.config['model_path'] = fileName
self.saveConfig()
def launchServer(self):
server = self.serverLineEdit.text()
model = self.modelLineEdit.text()
threads = self.threadsLineEdit.text()
port = self.portLineEdit.text()
n_predict = self.nPredictLineEdit.text()
n_ctx = self.nCtxLineEdit.text()
n_gpu_layers = self.nGpuLayersLineEdit.text()
self.config['threads'] = threads
self.config['port'] = port
self.config['n_predict'] = n_predict
self.config['n_ctx'] = n_ctx
self.config['n_gpu_layers'] = n_gpu_layers
self.saveConfig()
command = f'"{server}" --model "{model}" --threads {threads} --port {port} -n {n_predict} -c {n_ctx} -ngl {n_gpu_layers}'
subprocess.Popen(command, shell=True)
# Open the browser with the specified URL
url = f'http://127.0.0.1:{port}/'
webbrowser.open(url)
def loadConfig(self):
if os.path.exists(CONFIG_FILE):
with open(CONFIG_FILE, 'r') as f:
return json.load(f)
else:
return {}
def saveConfig(self):
with open(CONFIG_FILE, 'w') as f:
json.dump(self.config, f)
if __name__ == '__main__':
app = QApplication(sys.argv)
launcher = LlamaLauncherApp()
launcher.show()
sys.exit(app.exec_())画面と設定解説
このコードをllamacppServerLauncher.pyとでもして保存して、ダブルクリックすると以下の画像のような画面が開きます。

Server Executableは、server.exeを指定する項目です。Browse…を押すとエクスプローラーが開くので、server.exeを選択してください。
Modelは読み込みたいモデルを指定する項目です。Browse…を押すとエクスプローラーが開くので、使用するモデルを選択してください。
Threads (-t)は使用するCPUのコア数です、通常使用するのは物理コア数の半分らしいです。
Portはサーバーのポート番号です。http://127.0.0.1:8080/の8080の部分を指定します。多分大丈夫ですが、他のポート番号と被らないようにする必要があります。基本デフォルトでOK。
Max Tokens to Generate (-n)は一回の生成で作成されるトークンの最大数です。大きいほどメモリ使用量が多くなりますが、一回に出力できる文章が長くなります。画像では1024ですが、256-512で十分かと。
Context Size (-c)はコンテクストサイズで、LLMが記憶しているトークンの最大量です。これも、大きいほどメモリ使用量が多くなります。
GPU Layers (-ngl)はGPUに割り当てるレイヤー数で、モデルがGPUメモリのサイズ内に収まるなら、99とか200とか、大きい数値にしましょう。
Launch Serverを押すとサーバーが起動し、デフォルトブラウザーで以下の画像のようなページが開きます(サーバー起動までは表示されませんので、多少時間がかかります)。
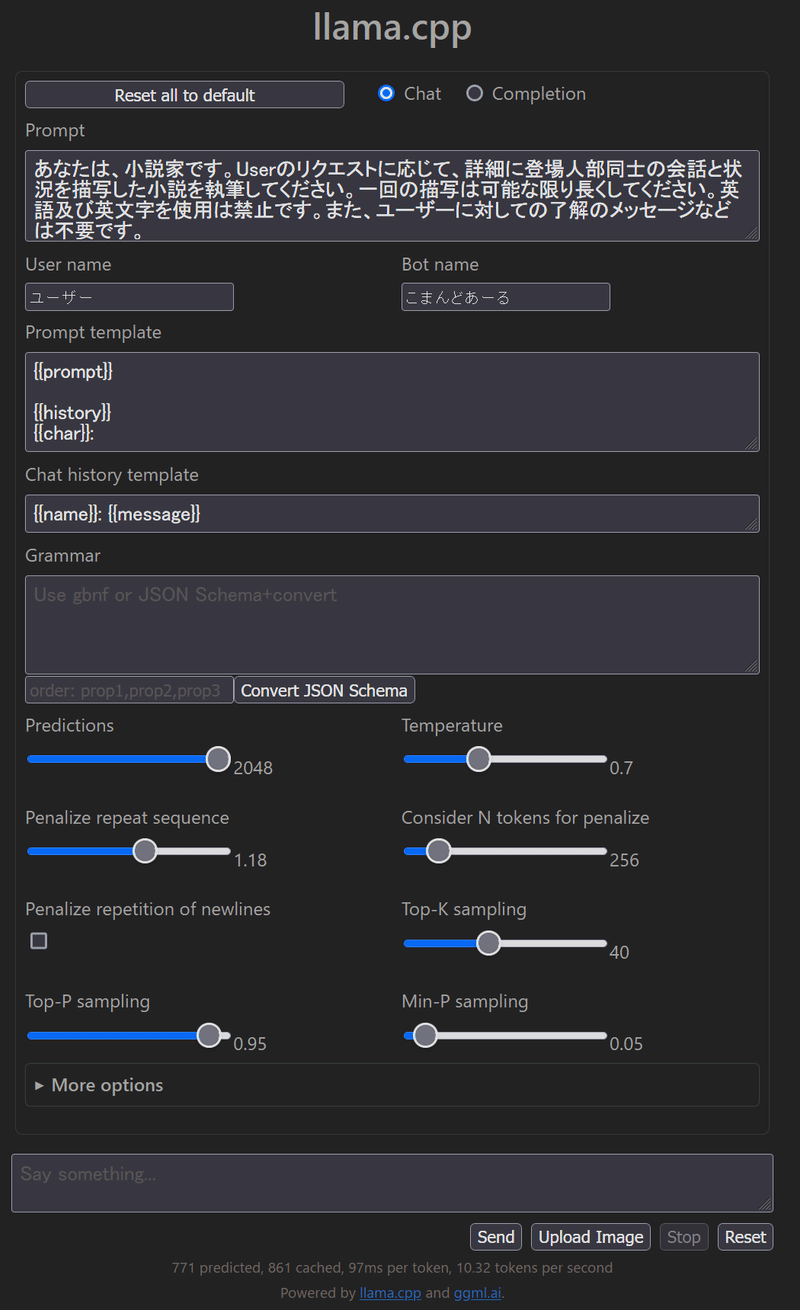
llamacppServerLauncherで設定した各項目は、llamacppServerLauncher.pyと同じフォルダ内にllama_launcher_config.jsonとして保存され、再度使用した場合もその設定が読み込まれるので、同じ設定で起動するならLaunch Serverボタンを押すだけで済みます。
何か問題があれば、ツイッターやディスコ(@willlion)までご連絡くださいm(_ _)m
また、自由に改変再配布をしてもらって構いませんが、ここにオリジナルがあることを明記してください。
表紙画像はStableCascadeで「Python code that can be started by sending startup options to server.exe in llama.cpp is now available, masterpiece, best quality」という、表題英訳をそのまま突っ込んでできた画像です。最初はこの画像の謎生物のアップで、集合体恐怖症の人にはアウトなブツブツがある感じだったので2枚目に生成した画像です。
この記事が気に入ったらサポートをしてみませんか?