
RCV WebUIでマイ声作ってみた話

こんにちは。今日は自分の備忘録も兼ねて、マイ声を作ってみた話を書きます。メモっぽくなっててすまん!
Retrieval-based-Voice-Conversion-WebUIって?

最近AIについても、絵を描いても、ビデオ作ってもなんか飽きてきてました。(たぶん魔改造Extravaganzaを作ってなんとなくやりきった感でいっぱいになってたのが原因かなと)
で、ちょっと趣向を変えて今一部で話題のTTS (Text To Speech)の方を見ていました。
その際に出会ったRCV(Retrieval-based-Voice-Conversion) WebUIで自分の声モデルを作ってみよう!というものをやってみました。
自分の声のモデルを作って、TextToSpeechでしゃべらせればYoutubeもVtubeも簡単に作れるのでは?と思います。あとは、画像もSDで用意したりしてSilly Tavernに全部ぶっこんで秘書ロボを作る事だって可能なんですよ!
今回はその第一歩という事で、なんとなく、暇なのでやってみようかなと。

セットアップ環境
今回はセットアップ方法は省略します。Gitから落としてピコピコ動かして出たエラーを修正する感じでできると思います。
環境はPaperspaceを利用しました。また、Pythonは3.10ベースで動かしています。
音源の準備
音源の準備がたぶん一番めんどくさいっす。
真っ暗で静かな所で一人で聖書を読むというプレイをおすすめします。
音源は10分以上とありますし、とりあえず写真の時と同じでクオリティが大事だと思うので、いらない音が入らない事等を重視しましょう

RCVのパラメタ設定
まず、以下を設定します
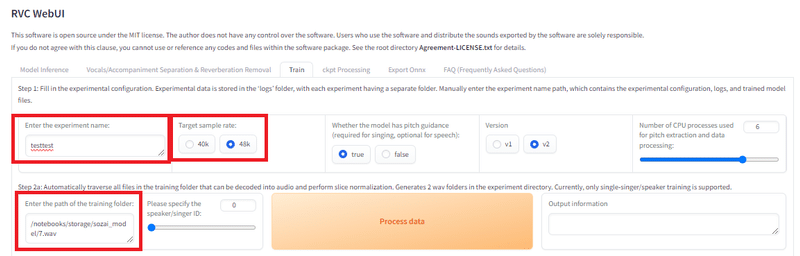
Enter the experiment name: モデルに付く名前
Target sample rate: 録音した時のサンプリングレート
Enter the path of the training folder: 先ほどの音声の入ったフォルダ
Process Dataボタンを押すとこんな感じになってなにかができます

次にその次の部分をやります
ここは何にも変更せず"Feature extraction"ボタンを押しました

最後はこんな感じにしました
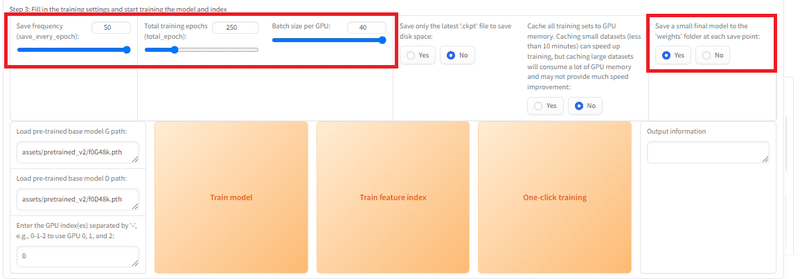
Save frequency (save_every_epoch): トレーニングを何回区切りで保存するか?
Total training epochs (total_epoch): 総トレーニング数
Batch size per GPU: パフォーマンス(多いとVRAMいっぱい必要)
Save a small final model to the 'weights' folder at each save point: "Save Frequency"毎にモデル作るか?
ぶっちゃけ何回やっていいのかわからんのですが、250回で十分という話を聞いたので、50区切りで5個モデル作ってどんな感じか見てみようという設定です。
できあがり
Model InterfaceタブのInferencing voice:内にtesttest.pthという名前で出てきました。s100とかはステップ100の時のものとかそういう事ですね。

このモデルを使って、変換前のセリフ等を用意する事で声をトレーニングさせた声に変換することができます。
とりあえず、適当なサンプルを拾ってきて、以前作ったYMMセットでこんな感じで出してみましたー!
うーん鼻声なのか…?
声が中の人と一致しているのかは謎ですが、今日はこんな感じで終わります!

あとがき
なんか声似ているか似てないかわからないという話がでてきたのでスポンジボブにしてみたよ!
どうだろうか…?
この記事が気に入ったらサポートをしてみませんか?