japanese-stablelm-instruct-alpha-7bを8bit量子化で動かす。

メモ:japanese-stablelm-instruct-alpha-7bが発表されたので、A4000で動かしました。
https://huggingface.co/stabilityai/japanese-stablelm-instruct-alpha-7b
まず、モデルカード記載の環境をインストールします。次にモデルカードからライセンスの承認を行い、ダウンロードできるように、
huggingface-cli login
をします。(注:事前にhuggingfaceアカウントの登録が必要です)
サンプルコードを動かすと、モジュール不足のエラーメッセージが、いくつか表示されますが、エラーメッセージに従ってインストールしてください。環境が正しくインストールされていれば、サンプルコードを動かすとモデルがダウンロードされます。大きなファイルなので時間がかかります。
その後、サンプルコードのままだと、強制終了されます。GPUのVRAM不足と推定し、
float16
8bit量子化
とモデルを小さくしながらテストしました。結果、8bit量子化で動作が確認できました。以下、GPUの状態。
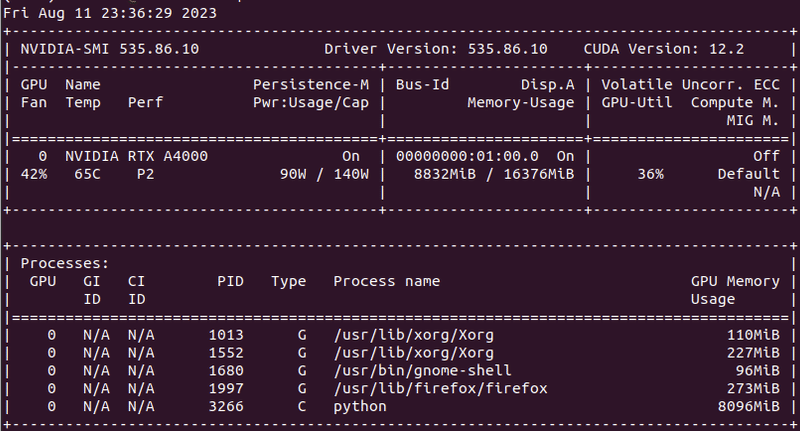
GPUのVRAMが8832MB(約8.8G)ですから、float16では16GのVRAMでは動かなかったんだと思います。8.8Gなら3060-12Gや10Gを搭載した他のGPUでも動きそうです。コードはモデルカードのサンプルに
load_in_8bit=True,
torch_dtype=torch.float16,
を追加し、以下をコメントアウトするだけです。
#model .half()
修正後のコード
import torch
from transformers import LlamaTokenizer, AutoModelForCausalLM
tokenizer = LlamaTokenizer.from_pretrained("novelai/nerdstash-tokenizer-v1", additional_special_tokens=['▁▁'])
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/japanese-stablelm-instruct-alpha-7b",
load_in_8bit=True,
torch_dtype=torch.float16,
trust_remote_code=True,
) #model .half()
model.eval()
def build_prompt(user_query, inputs="", sep="\n\n### "):
sys_msg = "以下は、タスクを説明する指示と、文脈のある入力の組み合わせです。要求を適切に満たす応答を書きなさい。"
p = sys_msg
roles = ["指示", "応答"]
msgs = [": \n" + user_query, ": "]
if inputs:
roles.insert(1, "入力")
msgs.insert(1, ": \n" + inputs)
for role, msg in zip(roles, msgs):
p += sep + role + msg
return p
# this is for reproducibility.
# feel free to change to get different result
seed = 42
torch.manual_seed(seed)
# Infer with prompt with additional input
user_inputs = {
"user_query": "VR について、以下の比較対象との違いを箇条書きで教えてください。",
"inputs": "比較対象: AR"
}
prompt = build_prompt(**user_inputs)
input_ids = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt"
)
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=256,
temperature=1,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0][input_ids.shape[1]:], skip_special_tokens=True).strip()
print(out)結果
モデルカードとよく似た結果が生成されました。内容は似ていますが、なぜか6項しかありません。このあたりが8bit量子化の影響でしょうか。
以下は、VR と AR の比較対象の比較です。
1. VR はユーザーが3D 世界に入り込むことができ、体験型のゲームやビジネスソリューションに使用されることが多い。
2. AR は、2D 画像をユーザーの物理的な環境の上に重ねることができる。例えば、商品や建物等の画像の代わりに、実世界にある物を仮想環境にレンダリングすることが可能です。また、バーチャルなオブジェクトを現実世界に重ねて表示することも可能です。
3. VR はユーザーの周囲の景色が全てディスプレイで表現され、現実とは異なる視覚的な体験を提供するが、AR は現実世界にデジタル情報を重ねるため、ユーザーの周り全てが情報源となります。
4. AR は、VR ほど没入感がなく、ユーザーが体験する仮想世界を現実世界と融合させることができます。
5. AR は、コンピュータビジョン、コンピュータ生成、またはコンピューターによって生成された画像と現実世界の画像を相互作用させることで、ユーザーにバーチャルなコンテンツを提供します。
6. VR は、物理的な物体またはオブジェクトと相互作用することができ、例えば、オブジェクトを操作したり、インタラクティブなアクションを行うことができます。対話モデルであるjapanese-stablelm-instruct-alpha-7bは商用利用ができませんが、以下のjapanese-stablelm-base-alpha-7bならば商用利用も可能です。こちらもモデルカードにサンプルコードがあります。この記事同様に8bit量子化をすればVRAM容量が少なくても動きます。huggingfaceアカウントの登録も必要ありません。
日本語が優秀なLLMを10G-VRAMが搭載された比較的安価なGPUが搭載されたPCで、ローカルに動かすことができるのは大変有意義だと感じます。今までオープンソースのローカルLLMを試したことがない方でも簡単に動かすことができるので、この機会に是非動かしてください。
参考