最近の記事



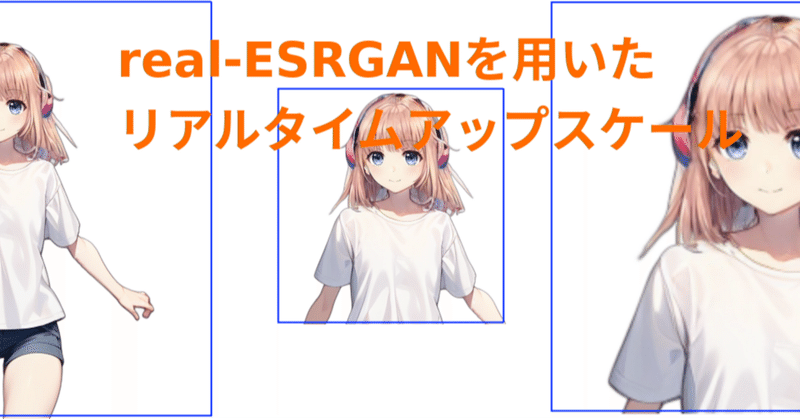
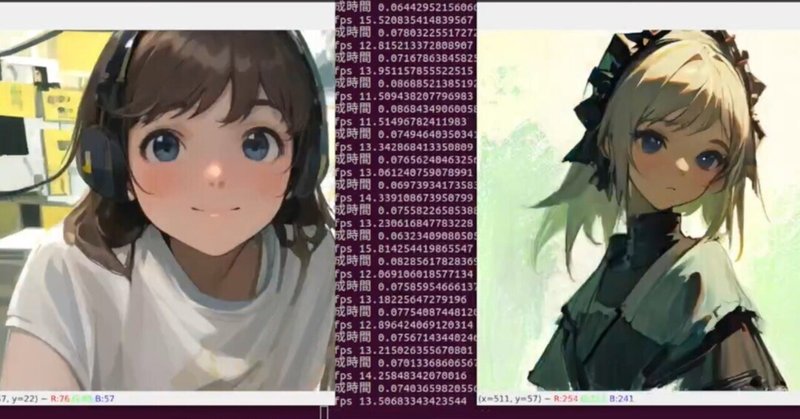
1枚絵からリアルタイムにアニメキャラを動かすーTalking-Head-AnimeFace3ー アップスケールで任意エリア拡大
はじめに前回はリアルタイムアップスケールの記事でした。前回の記事と、以前に書いた一枚絵からキャラを動かすTalkingHeadAnimefaceを組み合わて、キャラの任意の部分、例えば「胸から上」、「上半身」あるいは、「首から上」のようなエリス指定をしながらリアルタイムに拡大した動きを得るとができます。TalkingHeadAnimefaceとreal-ESRGANは生成速度に差があり、またapiサーバとすることで画像の大きさによる通信のオーバーヘッドも生じます。フレームレ







Diffusersの複数機能も簡単に扱えるDiffusersPipelineManagerを公開 (コードの解説と使い方)
この記事についてDiffusersはStable-Diffusionを始め、音声や、3Dにも対応する、拡散モデルのためのライブラリ群です。この記事ではStable-Diffusionによる画像生成をプログラミングで操作するためにDiffusersの機能を利用し、多岐にわたるDiffusersの持つ機能を纏めてアプリ開発で便利に利用できるような機能とするためにPythonによるクラス化を行いました。Diffusersの概要には、「 Our library is designe