高性能マルチモーダルMiniGPT-Vのデモを動かす

MiniGPT-4がV2にアップデートされて性能が大きく上がりました。早速試しましたので記事にまとめました。動かし方は公式のRead.MEに記載してあるとおりですが、筆者の環境では起動時に2件のエラーが出ていたので対処しています。
環境構築
anacondaのbaseをスタートとします。
ターミナルで以下のとおりにインストールを進めます。CUDA- ToolKitもダウンロードしてくれるようです。
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigptv筆者の環境では2件のエラーが出ました。
ModuleNotFoundError: No module named 'skimage'
ModuleNotFoundError: No module named 'visual_genome'
各々以下のようにインストール
pip install scikit-image
pip install visual_genomeLLMのモデルダウンロード
商用利用可能なLlama 2 Chat 7Bをダウンロードしました。
新たにフォルダーを作成しすべてのファイルを移動させます。
ホルダー名:Llama-2-7b-chat-hf
チェックポイントのダウンロード
3. Prepare the pretrained model checkpoints
に3種類のダウンロードが準備されています。
MiniGPT-v2 (after stage-2)ファイル名:checkpoint_stage2.pth
MiniGPT-v2 (after stage-3)ファイル名:checkpoint_stage3.pth
MiniGPT-v2 (online developing demo) ファイル名:minigptv2_checkpoint.pth
どれでも動きます。
ダウンロードしたチェックポイントは新たにcheckpointホルダーを作成して移動させておきます。
mkdir checkpointConfigファイルの編集
minigpt4/configs/models/minigpt_v2.yamlの14行目
model:
arch: minigpt_v2
# vit encoder
image_size: 448
drop_path_rate: 0
use_grad_checkpoint: False
vit_precision: "fp16"
freeze_vit: True
# generation configs
prompt: ""
llama_model: "./Llama-2-7b-chat-hf/"
lora_r: 64
lora_alpha: 16
preprocess:
vis_processor:
train:
name: "blip2_image_train"
image_size: 448
eval:
name: "blip2_image_eval"
image_size: 448
text_processor:
train:
name: "blip_caption"
eval:
name: "blip_caption"eval_configs/minigptv2_eval.yamlの8行目
model:
arch: minigpt_v2
model_type: pretrain
max_txt_len: 160
end_sym: "</s>"
low_resource: True
prompt_template: '[INST] {} [/INST]'
ckpt: './checkpoint/minigptv2_checkpoint.pth'
lora_r: 64
lora_alpha: 16
datasets:
cc_sbu_align:
vis_processor:
train:
name: "blip2_image_eval"
image_size: 448
text_processor:
train:
name: "blip_caption"
run:
task: image_text_pretrain起動コマンド
以下のコマンドでgradioサーバが起動します。
python demo_v2.py --cfg-path eval_configs/minigptv2_eval.yaml --gpu-id 0起動時のメッセージ
~/MiniGPT-4$ python demo_v2.py --cfg-path eval_configs/minigptv2_eval.yaml --gpu-id 0
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
Initializing Chat
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████| 2/2 [00:30<00:00, 15.20s/it]
trainable params: 33554432 || all params: 6771970048 || trainable%: 0.49548996469513035
Position interpolate from 16x16 to 32x32
Load Minigpt-4-LLM Checkpoint: ./checkpoint/minigptv2_checkpoint.pth
/home/animede/MiniGPT-4/demo_v2.py:547: GradioDeprecationWarning: 'scale' value should be an integer. Using 0.5 will cause issues.
with gr.Column(scale=0.5):
/home/animede/MiniGPT-4/demo_v2.py:647: GradioDeprecationWarning: The `enable_queue` parameter has been deprecated. Please use the `.queue()` method instead.
demo.launch(share=True, enable_queue=True)
Running on local URL: http://127.0.0.1:7860
Running on public URL: https://051dbf14fc80b896ec.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)
デモの開始
URL: http://127.0.0.1:7860を開くとデモ画面が開きます。

今回は公式のデモを動かすだけの作業でした。V2になってから色々とできることが増えています。
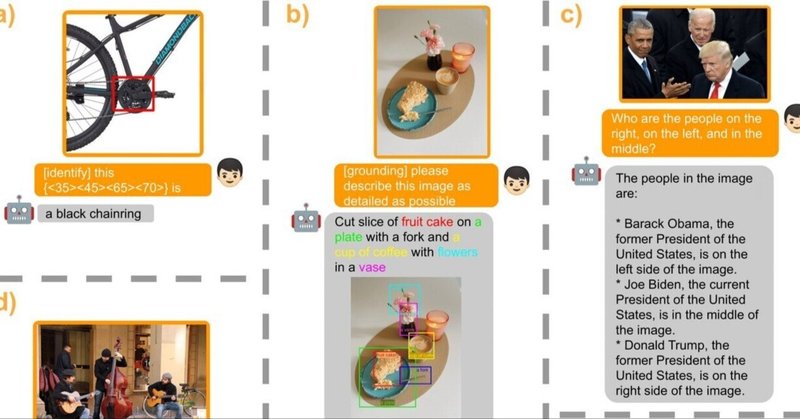
この例では範囲を指定して何が書いてあるのかを聞いています。バウンディングboxが表示されて推論結果が表示されています。

まとめ
マルチモーダルAIはOpenAIのChatGPT-4 V2など高機能なalが出ていますが、商用利用可能なローカル版としてはMniniGPT-Vは秀逸ではないでしょうか。