
「サンプルサイズが大きすぎると良くない」と思います

ハローワールド!アイシアです!

(写真は謎の美少女とのツーショット)
いつもはデータサイエンス VTuber として、統計、機械学習、 Deep Learning の動画などを出してます。
よかったらチャンネル登録してね!
ちょっと前に twitter でバズっていたこの記事を拝見して、バーチャル Data Scientist なりに考えたことを書いてみようと思います。
統計的有意と実務的有意
いきなり結論に近いことを言います。
「有意」という言葉は、「意味がある」という意味で使われる言葉です。
そして、この「有意」という言葉には、視点の違う2つの意味があります。
この2つを区別することが、ビジネス上の実務や研究でも重要になります。
統計的有意とは
まず、みんながよく耳にするのは統計的検定の文脈で、そこでは「統計的有意」という言葉が使われます。
例えば、有意性の水準を 5% に設定していたとしたら、p値が5%より小さいことを、「統計的有意」といいます。
このp値とは何でしょうか?
一言でいうと、どれくらい不自然なことが起きたかの指標です。
p値が1%の事象が起こったとすると、これは、「普通に生きていたら1%くらいの確率でしか遭遇しないことに遭遇した」という意味です。
もとの note と同じ、サイコロの例で説明します。
サイコロは、基本的に、どの目も1/6の確率で出るはずです。
でも、例えば、サイコロを6回振ったからといって、実際にどの目も1回ずつ出るということはほぼありえません。
例えば、6回振った結果、1が2回、2が2回、3が1回、4が1回、5が0回、6が0回だったとしましょう。
これは、「普通に生きていたらどれくらいの確率で遭遇すること」なのでしょうか?
統計の手続きに従って計算すると、 54.94% くらいの確率で起こることだそうです。
(正確に言うと、この 54.94% というのは、今回の 2, 2, 1, 1, 0, 0 という目の出方の不均等さと、同じかこれ以上に不均等な結果(たとえば、3, 3, 0, 0, 0, 0 など)が得られる確率のことです。)
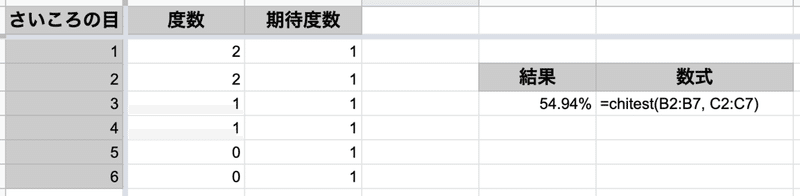
Google spreadsheet でも簡単に計算できます。
実務的有意とは
統計的有意とは別に、実務的有意という概念も、実世界においては非常に重要です。これは、「実際的に意味のある差」という意味です。または、言い換えると、「この情報を知ったことによって、自分の行動を変えるに値するほどの差か」という意味です。
具体的に説明してみましょう。例えば、コンビニでジュースAとジュースBが売っていたとしましょう。でもあなたはダイエット中です。あまり太らない飲み物が飲みたいと考えています。
ここで、ジュースAの糖質は10g、ジュースBの糖質は10.1gだったとします。
もし、ジュースBが飲みたい気分だったとしても、0.1g糖質が少ないジュースBに変更すべきでしょうか?
これが、実務的有意の考え方です。統計的有意とは異なり、確実にジュースBのほうが糖質が多いですが、実際にはこの差を気にせず、ジュースBを選択する人が多いと思います。
この0.1gの差は、実務的有意ではなかったということです。
ちょっと早いですが、、、。
「統計的有意性」の観点では、サンプルサイズが大きいことに何の問題もないですが、
「実務的優位性」の観点では、サンプルサイズが大きいことが問題になる場合があります。
これが、今回の note のポイントです。
統計的有意性とサンプルサイズ
冒頭で紹介した note でもありましたが、帰無仮説が成り立たない場合、サンプルサイズを大きくする極限で、統計的有意である確率は100%に近づきます。
もう少し噛み砕いて説明します。
実は、ここに持っているサイコロは歪んでいて、1が出る確率が1/6ではなく1.1/6だったとしましょう。若干、1が出る確率が高いのです。
とはいえ、60回振って1が11回出たからといって、即座にこのサイコロが歪んでいるという結論は出せないでしょう。なぜなら、歪んでいないサイコロでも、60回振って1が11回出ることも珍しくなさそうだからです。
実際、p値を計算してみても、72.90%もあります。つまり、歪んでいないサイコロであっても、72.90%の確率で出会う事象なのです。全く珍しくありません。

今度は、サイコロを6000回振ったとしましょう。そのうち1100回も1が出たとしたら、確率1/6のサイコロであるとは考えにくいのではないでしょうか。
実際、p値を計算してみると、0.05%しかありません。「実は1/6のサイコロだったが、0.05%の確率でしか起こらない事象を引いた」と考えるより「このサイコロは歪んでいて、1が若干出やすい」と考えるのが自然ですよね。

ここから何が言えるかと言うと、1/6と1.1/6の違いを、サンプルサイズ(サイコロを投げる回数)を増やすことで、統計的に見分けることができたということになります。
素晴らしいじゃないですか!
ですが、素晴らしいだけではないのです。
歪みがどんなに小さくとも、サンプルサイズを大きくすれば、ほぼ100%統計的有意性を導くことができてしまうのです。
たとえば、今持っているサイコロの歪みが非常に小さく、1が出る確率は1.001/6だったとします。
1/6 = 16.667% に対して、 1.001/6 = 16.683% ですので、0.016%の差しかありません。
それでも、サイコロを6000万回振り、1が1001万回出たとすると、p値は再び0.05%となり、統計的に有意となります。
これは、素晴らしいのでしょうか?

サンプルサイズが大きすぎるときにp値を盲信するのは良くない
最後の例の、 16.667% と 16.683% は、サンプルサイズを6000万にすることによって、統計的な有意性を得ることができました。
ですが、これは果たして実務的有意なのでしょうか?
お店にサイコロが2つあり、あなたはそのうちの1つを買いました。
会計が終わった瞬間、謎の神通力で、実はあなたが買ったサイコロは歪んでいて、1が出る確率が16.683%あると気づいてしまいます。
もう一方を買っていれば、16.667%だったのに!
この場面で、あなたは、返品をし、別のサイコロを選ぶでしょうか。(今のサイコロのほうがお気に入りの色なのに!)
多くの人は、選ばないと思います。
つまり、統計的有意であっても、実務的有意でないことがあるのです。
これは、ビジネスの場面で、重大な問題を引き起こすことがあります。
ビッグデータがあふれるようになった現代、サンプルサイズが大きすぎるデータを手に入れることは用意になりました。
例えば、あなたは web サイトを運営していて、登録フォームに A/B テストを仕掛けたとしましょう。
(ユーザーによって別の登録フォームを表示し、どちらのほうが登録率が高いかを調べるテスト)
昔ながらのフォームAの登録完了率は10%、新しく作ったフォームBの登録完了率は10.01%、この差は統計的有意だったとします。
では、フォームBに切り替えるべきでしょうか?
フォームAからフォームBに切り替えることによって、たしかに登録者数は微増するかもしれません。
ですが、フォームBに切り替えるのに人件費がかかるばあい、この0.01%の差での利益増加では、その人件費がペイしない可能性があります。
何がいいたいかと言うと、サンプルサイズが大きすぎる場合には、実務的には有意でない程度の僅かな差しかない場合でも、統計的に有意と判定されてしまうことがあるのです。
このような場合に、p値を過信してしまうと、重要な意思決定を謝る可能性があるのです。
サンプルサイズが大きいことが悪いわけではないのです。
ですが、p値を過信し、実務的に無意味な差に統計的有意性を見出して、変な意思決定をする大人にはならないでいたいなと思うのでした。
チャンネル登録してね!
データサイエンス VTuber として統計や Deep Learning の動画出してます!
よかったらそっちも見てくれると嬉しいです!
Twitter もやってるよ!
よかったらフォローしてね! → https://twitter.com/AIcia_Solid
この記事が気に入ったらサポートをしてみませんか?