
【論文瞬読】大規模言語モデルの性能を引き出す秘訣Chain-of-Thought Prompting

こんにちは!株式会社AI Nestです。
今日は、最新の自然言語処理研究で注目を集めている「Chain-of-Thought (CoT) Prompting」について紹介します。この手法は、大規模言語モデル (LLMs) の性能を大幅に改善することができる画期的なアプローチなんです。
タイトル:Challenging BIG-Bench tasks and whether chain-of-thought can solve them
URL:https://arxiv.org/abs/2210.09261
所属:Google Research, Stanford University
著者:Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V. Le, Ed H. Chi, Denny Zhou, Jason Wei
BIG-Bench Hard - 難関タスクの登場
LLMの評価には、BIG-Benchと呼ばれる多様で挑戦的なタスクを集めたベンチマークがよく使われています。しかし、その中でも特に難しい23のタスクがあることが分かったんです。研究者たちはこれらのタスクをBIG-Bench Hard (BBH)と名付けました。

上の図を見ると、Answer-only プロンプティングではほとんどのタスクで人間の平均スコアを下回っていますが、CoT プロンプティングを用いることで多くのタスクで人間を上回る性能が得られていることが分かります。
Answer-only Promptingの限界
従来のLLM評価では、Answer-only Promptingという手法が主流でした。これは、タスクの入力と出力の例をいくつか与えるだけで、LLMに答えを生成させる方法です。

上の図を見ると、Answer-only Promptingでは入力と出力の例のみを与えているのに対し、CoT Promptingではタスクを解くための推論過程も含まれていることが分かります。しかし、複雑な推論を必要とするタスクでは、Answer-only Promptingでは LLMの能力を過小評価してしまう可能性があることが分かってきました。
Chain-of-Thought Promptingの登場
ここで登場するのが、Chain-of-Thought (CoT) Promptingです。CoTは、タスクを解くための推論過程を言語化したプロンプトを与えることで、LLMの推論性能を改善する手法なんです。つまり、答えを出すまでの思考の流れを示すことで、LLMに複雑な問題の解き方を教えるわけですね。

上の図は、BBHのタスクの例とCoT プロンプティングを用いたモデルの出力例です。推論過程が詳細に示されていることが分かりますね。
驚きの性能向上
研究者たちがCoTをBBHに適用したところ、驚くべき結果が得られました。
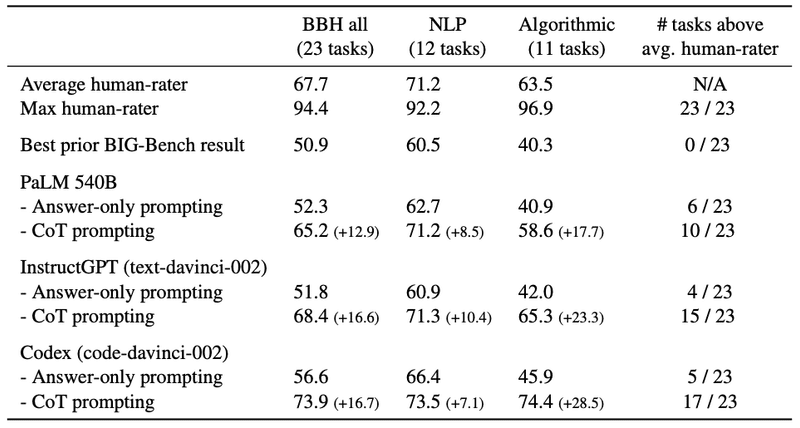
上の表を見ると、最も性能の良いCodexモデルは、CoT プロンプティングを用いることで23タスク中17タスクで人間の平均スコアを上回ったことが分かります。これは、CoTがLLMの潜在的な能力を引き出すのに非常に効果的であることを示しています。
モデルスケールとCoTの関係
ただし、CoTの効果を最大限に発揮するには、十分に大きなモデルが必要であることも明らかになりました。

上の図を見ると、モデルの規模が大きいほどCoTによる性能向上が顕著に現れていることが分かります。これは、大規模なモデルが複雑な推論に必要な知識を豊富に持っているためだと考えられます。
Emergent Task Performance - 新たな能力の発現
さらに驚くべきことに、CoTを用いることで、それまで単調なスケーリング曲線を示していたタスクでも、突然の性能向上(Emergent Task Performance)が見られたんです。

上の図は、3つのタスクにおけるモデルスケールと性能の関係を示しています。Answer-only Promptingでは単調なスケーリング曲線を示していますが、CoTを用いることでEmergent Task Performanceが得られていることが分かります。これは、CoTがLLMの潜在的な能力を引き出し、新たな可能性を開拓するための鍵となることを示唆しています。
まとめ
CoT Promptingは、LLM研究に新たな地平を切り開く画期的な手法です。しかし、真の言語理解や推論能力を獲得したかどうかは慎重に見極める必要があります。また、CoTプロンプトの生成を自動化・最適化する手法の開発も重要な課題です。
LLMの性能向上に向けた研究は、日進月歩で進んでいます。CoT Promptingはその一端を担う有望なアプローチですが、さらなる進展に向けて、多様な角度からの研究が求められています。言語モデルの内部表現の解析や、より洗練された評価指標の開発など、やるべきことはまだまだたくさんありそうですね。
みなさんも、こうした最先端の研究動向に注目して、自然言語処理の可能性を一緒に探求していきましょう!