
【論文瞬読】大規模言語モデルの深層は不要?衝撃の層削除実験とその示唆

こんにちは!株式会社 AI Nestです。
今日は、大規模言語モデル(LLM)の効率化に関する興味深い研究を紹介します。この研究では、LLMの深層にある多くのレイヤーが冗長であり、それらを削除してもモデルの性能が大きく低下しないことが実証的に示されています。
タイトル:The Unreasonable Ineffectiveness of the Deeper Layers
URL:https://arxiv.org/abs/2403.17887
所属:Meta FAIR & UMD, Meta FAIR, Cisco, Zyphra, MIT & Sequoia Capital
著者:Andrey Gromov, Kushal Tirumala, Hassan Shapourian, Paolo Glorioso, Daniel A. Roberts
研究の背景と目的
LLMは、自然言語処理のさまざまなタスクで驚くべき性能を示していますが、そのパラメータ数の多さゆえに、学習や推論に膨大な計算コストがかかるという問題があります。この研究は、LLMの効率化を目指して、深層のレイヤーの冗長性に着目しました。
研究チームは、以下の仮説を立てました:
LLMの深層レイヤーは冗長であり、削除可能である。
深層レイヤーほど削除の影響が小さい。
削除に成功したレイヤーブロックは、入力と出力の表現が類似している。
これらの仮説を検証するために、彼らはさまざまなLLMファミリーを対象に大規模な実験を行いました。
実験の概要
実験では、Llama-2、Qwen、Mistral、Phi-2などのさまざまなLLMファミリーを対象に、2.7B〜70Bパラメータの幅広いモデルサイズが使用されました。研究チームは、以下の手順で層の削除と評価を行いました:
隣接する層間の類似度を計算し、最も類似度の高いレイヤーブロックを特定。
そのブロックのレイヤーを削除し、QLoRAと呼ばれる効率的なファインチューニング手法により性能を回復。
質問応答ベンチマーク(MMLU、BoolQ)の精度と自己回帰損失を評価。
この一連の実験により、LLMの深層レイヤーの冗長性と、削除が性能に与える影響が詳細に分析されました。下記の図は、研究チームが提案する層プルーニング戦略の概要と、Llama-2-70Bモデルに適用した際の例示的な結果を示しています。

(c) 異なるブロックサイズnにおける層間の角度距離、
(d) Llama-2-70Bのプルーニング結果(ファインチューニングの有無で比較)
驚きの結果と考察
実験の結果、質問応答タスクの精度は、ある臨界点までレイヤーを削除してもほとんど低下せず、臨界点を超えると急激に低下するという現象が観察されました。下記の図は、さまざまなモデルファミリーにおける、レイヤードロップ率とMMLU精度の関係を示しています。この臨界点は、モデルファミリーやサイズによって異なりますが、多くの場合、全レイヤーの20%〜55%の範囲でした。
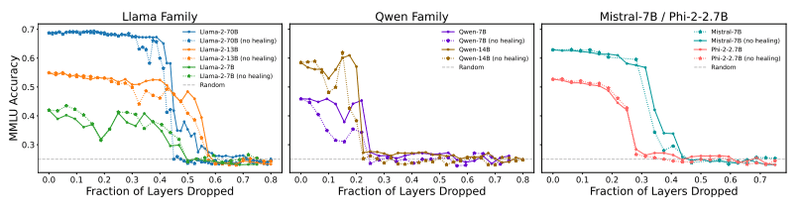
(左: Llama-2ファミリー、中: Qwenファミリー、右: Mistral-7BとPhi-2)
一方で、自己回帰損失は連続的に変化し、臨界点付近でも滑らかな曲線を描くことが示されました。下記の図は、レイヤードロップ率とC4検証損失の関係を、ファインチューニングの有無で比較しています。これは、質問応答タスクと言語モデリングタスクで必要とされる知識の性質が異なる可能性を示唆しています。
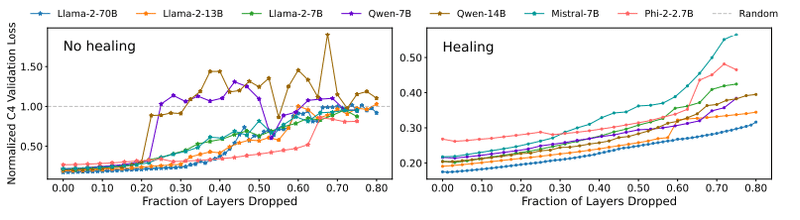
(左: ファインチューニング前、右: ファインチューニング後)
これらの結果から、研究チームは以下の考察を述べています:
現在の事前学習手法では、LLMの深層パラメータが適切に活用されていない可能性がある。
LLMの浅い層が知識の保存に重要な役割を果たしている可能性がある。
タスクによって、必要な知識が保存されている層の深さが異なる可能性がある。
今後の展望と私の感想
この研究は、LLMの効率化と解釈性の向上に向けた重要な一歩を示していますが、まだ多くの課題が残されています。例えば、レイヤードロップ後のファインチューニングが質問応答の精度と損失の不整合を生む原因や、タスクに応じた最適なプルーニング方法の探索などです。
また、より深層を有効活用するための事前学習アーキテクチャや目的関数の改善も、今後の重要な研究テーマになるでしょう。LLMの進化とともに、より洗練された知識の表現と処理メカニズムが明らかになることを期待しています。
個人的には、この研究の丁寧な実験と分析に感銘を受けました。著者らの洞察力と実証的アプローチは、LLM研究の発展に大きく貢献すると思います。同時に、LLMの効率化は、より多くの人々がLLMを活用できるようになるための重要な課題でもあります。この研究がその一助となることを願っています!