
今度はきっと大丈夫。片想いリスト / 両想いリスト / 愛されリストを作ろう(2021/02/22更新)

片想いリスト / 両想いリスト / 愛されリスト。フォローリスト / フォロワーリスト
フォローされてる? フォローしている? 相互フォローになってるの?
フォロー整理って大変💦
それなら、「さぁ、リスト化しませんか」という記事です
初回作った処理はあえなく失敗w
悔しくて悔しくて震えたので、プログラム作り変えました。非公式のAPIを利用したのでいつ使えなくなるか分かりませんが、今度は全部データ取れます。
雑な作りで申し訳ないですが、一度ベータ版として公開させてください。出力結果とか、かなりざっくりなので、もう少しレベルアップ考えていきます
※利用規約違反になったら即刻ページを削除しますし、BANされたらnote様に申し訳ない気持ちでいっぱいになりますので、甘んじて受け入れます
お願い
うまく動かなかったら、コメントください。APIの仕様がすべて把握できていないので、一定程度動かない方がいると想定しています。
それと、出来た方もできたーってコメント貰えるとうれしいです
そして、良かったらスキとフォローをお願いします。レベルアップ連絡をお届けしたいので。
手順
1) GoogleColaboratoryのサイトに行く
2) ファイル - ノートブックを新規作成 をクリック
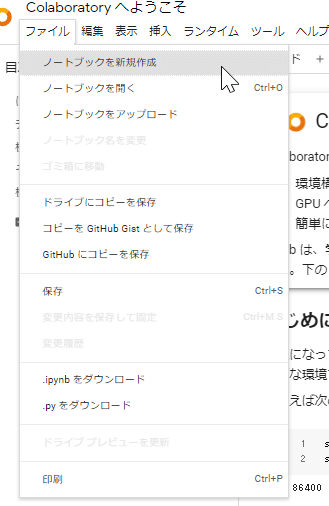
3) ノートブックが開くので、ここに下記のソースを張り付ける
変更履歴は最下部参照
# PDF 書き出し用モジュールのダウンロード
!pip install reportlab
# -*- coding: utf-8 -*-
import requests
import time
import pandas as pd
from tqdm import tqdm
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import A4, landscape, portrait
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.cidfonts import UnicodeCIDFont
from reportlab.lib.units import cm
# リスト作成共通処理
def createUserList(api_url, followWord):
#payloadの生成 - 今は利用予定がないが、今後を見越して生成
payload = {}
# 最大ページ数取得
# APIアクセス
resCount = requests.get(api_url, params=payload)
#response.json()でJSONデータに変換して変数へ保存
countJson = resCount.json()
#登録数を取得
count = countJson['data'][ followWord + '_count']
#apiは12件のデータを返却するため、page数の最大値を算出
#last_page フラグが存在するのでリファクタリング対象
maxPage = int(count/12)
if count%12 != 0:
maxPage = maxPage + 1
# dfに変換するためのapi情報格納リスト生成
list_Name = []
list_Url = []
list_Note_count = []
list_Following_count = []
list_Follower_count = []
list_Profile = []
# クエリー設定
queryPage = '?page='
# 最大ページ数分データの取得
# 登録数取得で1ページ目をすでに取得済みだが、ロジックをシンプルにするため1ページから取得しなおす
for page in tqdm(range(maxPage)):
# APIアクセス
resUsers = requests.get(api_url + queryPage + str(page+1), params=payload)
#response.json()でJSONデータに変換して変数へ保存
usersJson = resUsers.json()
# ユーザ一覧の取得
lists = usersJson['data'][followWord + '_list']
# ゲストユーザflg
guestFlg = False
# ユーザ情報確認
for list in lists:
# ユーザアクセス関連情報
urlname = list['urlname']
nickname = list['nickname']
id = list['id']
# ユーザ詳細情報
note_count = list['note_count']
following_count = list['following_count']
follower_count = list['follower_count']
profile = list['profile']
# ゲストフラグの初期化
guestFlg = False
# ゲストユーザの場合、urlnameが存在しないため、ユーザidをurlnameとする
# アクセス用URLを変更するためFLGをTrueに設定
if urlname is None:
urlname = id
guestFlg = True
# ユーザ登録はあるがニックネーム情報がないユーザはurlnameをnicknameとする
if nickname is None:
nickname = urlname
# profile内にある、csvとして扱いが煩雑になる文字列を削除
if profile is not None:
# 改行 - 情報が一行で収まらなくなるため
profile = profile.replace('\r','')
profile = profile.replace('\n','')
profile = profile.replace('\r\n','')
# カンマ - csvの区切り位置がずれてしまうため
profile = profile.replace(',','')
else :
# プロフィール未設定の場合、出力時にNoneが出る場合があるので、初期化
profile = ''
# ゲストユーザの場合、urlnameにidをセットしたので、urlnameが存在しない場合はないが、
# 存在しない場合に処理がエラーになってしまうので、nullチェックを存置しておく
# また、数字のみのurlnameがあった場合、int型に判定されるためstrに変換する
if urlname is not None:
list_Name.append(nickname)
if guestFlg:
list_Url.append('https://note.com/_nourlname?user_id=' + str(urlname))
else:
list_Url.append('https://note.com/' + str(urlname))
list_Note_count.append(str(note_count))
list_Following_count.append(str(following_count))
list_Follower_count.append(str(follower_count))
list_Profile.append(str(profile))
# note様のサーバ負荷にならないよう1秒スリープ
time.sleep(1)
# dfへの変換(リスト生成用)
df_list = pd.DataFrame({'name': list_Name,
'url':list_Url})
# dfへの変換(ユーザ情報用)
df_detail = pd.DataFrame({'name': list_Name,
'url':list_Url,
'following_count': list_Following_count,
'follower_count': list_Follower_count,
'note_count': list_Note_count,
'profile': list_Profile
})
# 重複行を削除
df_list.drop_duplicates(subset='url', inplace=True)
df_detail.drop_duplicates(subset='url', inplace=True)
return df_list, df_detail
# indexのリセットとイチ始まりへ変換
# 本来ならフォロー開始日など別データを利用してソートの上、
# keyを振るべきなので、リファクタリング対象
def resetIndex(df):
# indexをリセット
df.reset_index(drop=True, inplace=True)
# indexのゼロ始まりをイチ始まりに変換
df.index = df.index + 1
return df
# PDF出力
def createPDF(df, file_name, title, column_name):
# フォントサイズ
font_size = 8
# 1ページあたりの書き出し行数
output_row = 25
# 1行あたりの高さ
row_height = 0.7
# フォント登録
pdfmetrics.registerFont(UnicodeCIDFont('HeiseiKakuGo-W5'))
# PDF名とPDFサイズの設定
pdf = canvas.Canvas(file_name + '.pdf', bottomup=False, pagesize=landscape(A4))
# フォント、フォントサイズを設定
pdf.setFont('HeiseiKakuGo-W5', font_size)
# タイトル情報
pdf.setTitle(title)
# 件名情報
pdf.setSubject(title)
# 書き出し情報の取り出し
lists_name = df[column_name]
lists_url = df['url']
# 最大書き出し行数
max_row = len(df)
# 出力ページ数
max_page = int(max_row / output_row)
if max_row % output_row != 0:
max_page = max_page + 1
# A4サイズの縦横幅の取得
height, width = A4
# ヘッダー書き出し位置の計算
header_x = width / 2
header_y = row_height * cm * 2
# ページ番号書き出し位置の計算
page_num_x = width / 2
page_num_y = height - row_height * cm * 2
# 出力ページ数分、PDF書き出しの実施
for page in tqdm(range(0,max_page)):
# 情報の書き出し
for line in range(1,output_row+1):
# 出力行数の計算
outputting_row = page * output_row + line
# 最大書き出し行数を超えない限り、書き出しを実施
if max_row >= page*output_row + line:
name = lists_name[outputting_row]
len_name = len(name)
if len_name > 50:
name = name[0:50] + '...'
# 情報の書き出し
pdf.drawString(1*cm, ((line+2) * row_height)*cm,
str(outputting_row) + ','
+ str(name) + ','
+ str(lists_url[outputting_row]))
# ヘッダーの書き出し
pdf.drawCentredString(header_x, header_y, title)
# ページ番号の書き出し
pdf.drawCentredString(page_num_x, page_num_y, str(page+1) + ' / ' +str(max_page))
# 改ページの実施
if max_page-1 > page :
pdf.showPage()
pdf.setFont('HeiseiKakuGo-W5', font_size)
# pdfの保存
pdf.save()
if __name__ == '__main__':
print('START')
#ユーザ名
user_name = 'XXXXXXX'
# URL設定
top_url = 'https://note.mu/api/v1/'
followers_url = top_url + '/followers/' + user_name + '/list'
followings_url = top_url + '/followings/' + user_name + '/list'
# フォロワーの一覧作成
print('フォロワー情報の取得')
df_followers, df_followers_detail = createUserList(followers_url, 'followers')
df_followers.rename(columns={'name': 'followers_name'}, inplace=True)
# フォローの一覧作成
print('フォロー情報の取得')
df_followings, df_followings_detail = createUserList(followings_url, 'following')
df_followings.rename(columns={'name': 'followings_name'}, inplace=True)
# 各種CSV生成
# フォロワー
df_followers_detail = resetIndex(df_followers_detail)
df_followers_detail.to_csv(user_name + '_note_followers.csv')
# フォロー
df_followings_detail = resetIndex(df_followings_detail)
df_followings_detail.to_csv(user_name + '_note_followings.csv')
# 両想いユーザ
df_ryouomoi = pd.merge(df_followers, df_followings, on='url', how='inner')
df_ryouomoi = resetIndex(df_ryouomoi)
df_ryouomoi.drop('followings_name', axis=1, inplace=True)
df_ryouomoi.rename(columns={'followers_name':'followings_followers_name'}, inplace=True)
df_ryouomoi.to_csv(user_name + '_note_ryouomoi.csv')
# 片想いユーザ
df_kataomoi = pd.merge(df_followings, df_followers, on='url', how='left')
df_kataomoi = df_kataomoi[df_kataomoi['followers_name'].isnull()]
df_kataomoi = resetIndex(df_kataomoi)
df_kataomoi.drop('followers_name', axis=1, inplace=True)
df_kataomoi.to_csv(user_name + '_note_kataomoi.csv')
df_kataomoi_simple = df_kataomoi.drop('followings_name', axis=1)
df_kataomoi_simple.to_csv(user_name + '_note_kataomoi_simple.csv')
# 愛されユーザ
df_aisare = pd.merge(df_followers, df_followings, on='url', how='left')
df_aisare = df_aisare[df_aisare['followings_name'].isnull()]
df_aisare = resetIndex(df_aisare)
df_aisare.drop('followings_name', axis=1, inplace=True)
df_aisare.to_csv(user_name + '_note_aisare.csv')
# PDF生成
createPDF(df_ryouomoi, user_name + '_note_ryouomoi', '両想いリスト', 'followings_followers_name')
createPDF(df_kataomoi, user_name + '_note_kataomoi', '片想いリスト', 'followings_name')
createPDF(df_aisare, user_name + '_note_aisare', '愛されリスト', 'followers_name')
print()
print('END')4) プログラム内のユーザ名を書き換える
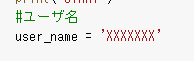
↓
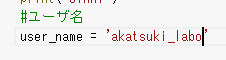
IDは「https://note.com/〇〇〇」の〇〇〇の部分です
私だと「akatsuki_labo」ですね
https://note.com/akatsuki_labo
#ユーザ名
user_name = 'akatsuki_labo'
5) 実行ボタンを押す

6) しばし待つ
プログレスバーを表示しているので、しばし待ちます。1カウントアップするのに2秒ぐらいかかります。フォロワー/フォロー合計4000人ぐらいで15分ぐらいです。
note様のサーバ負荷になってしまうので、しばし待ちましょう
↓こんな感じで進捗状況がでてきます。下3つのプログレスバーはPDF生成処理です

7) 完了後、保存されたファイルを表示するため、左袖にあるディレクトリアイコンをクリックします
8) 生成されたファイルを確認します
・〇〇_aisare.csv:自分がフォローせず、相手がフォロー
・〇〇_aisare.pdf:自分がフォローせず、相手がフォロー(PDF版)
・〇〇_kataomoi.csv:自分がフォロー、相手がフォローせず
・〇〇_kataomoi.pdf:自分がフォロー、相手がフォローせず(PDF版)
・〇〇_kataomoi_simple.csv:自分がフォロー、相手がフォローせず(連番とURLのみのデータ)
・〇〇_ryouomoi.csv:相互フォロー
・〇〇_ryouomoi.pdf:相互フォロー(PDF版)
・〇〇_followers.csv:フォロワー一覧
・〇〇_followings.csv:フォロー一覧

※ PDFファイルは特殊文字(絵文字等)が見た目上空白になっています。デフォルトフォントだと、それしかできず、ご了承ください
9) ファイルをダウンロードする

10) 煮るなり焼くなりする
リストの情報詳細
フォローリスト、フォロワーリストは情報を出力しています
name:ユーザ名
url:クリエイターページのURL
following_count:フォロー数
follower_count:フォロワー数
note_count:投稿数
profile:プロフィール
片想いリスト、愛されリスト、両想いリストはユーザ名とクリエイターページのURLのみ出力しています
有料化考えていないのですが、有料販売している人に何か言われるのだろうか。。。それだけが不安。。。
締めくくり
ツール利用でうまれた時間を、クリエイティブに使っていきましょう!
変更履歴
2021/02/22 編集:文字化け対応のため片想いリストのみ、連番とURLのCSVデータを書き出し。
2021/02/08 編集:文字化け対応のため、PDF出力処理を追加。
2021/01/29 編集:フォロー一覧、フォロワー一覧の出力機能追加。
2021/01/28 編集:ゲストユーザの情報もリスト化されるよう改修。リストの不要列を削除。リストの連番を振り直し(新しい人から昔馴染みの人の銃んで連番処理を追加)
2021/01/27 編集 - 2回目:ユーザ登録がありニックネームの登録がないユーザが全リストに掲載されてしまう問題を対処
2021/01/27 編集 - 1回目:ゲストユーザの場合にurlnameが存在せずエラーになるため、処理をスキップするよう変更
この記事が気に入ったらサポートをしてみませんか?