
AtCoder Beginner Contest反省会 ~入水編~

AtCoder Beginner Contest反省会というnoteを、入水したら新しいnoteに移動するぞと思いながら、以前からABCのたびに書き足していたのですが、もうちょっとのところで入水できないままnoteの文字数制限(文字だけなら29万字っぽいが、他の条件でもっと減る)を超え、余計な文章やコードを消しながらがんばって続けてましたが、入水できそうと思ってからすでに10回くらい達成ならず、noteの文字数制限とギリギリの攻防を続けるのがあまりにも不毛で、もはやものすごいストレスになってしまっていたので、スッキリとあきらめて新しいnoteに移動してきました。本当は古いnoteのタイトルを、~入水編~としたかったんですが、古い方は~入緑編~となりました。このnoteは入水編です。ようやく、ARC162で入水できました。感じたことなどはARC162の欄に少し書いています。
AtCoder Beginner Contest 302
初の6完!今回簡単だったけど、パフォーマンスと順位は過去2番目に良かった。しかし、またしても入水ならず。モヤモヤ気持ち悪すぎて日常生活が破綻するので勘弁してくれ。これが入水したらあの子に告白するぞーとか思ってて、入水できずタイミング逃したらどうすんのよ。入水すれば、いいのです。Gもコンテスト時間内にひらめいたけど、10分くらいしか残ってなくて間に合わなかった。終わったあと、自力ACできた。今回Gまでノーミスで自力ACして解説見てないのは初めてだ。まあ確かに簡単ではあったけど、喜ぶべきこと。A-CとD-Fの時間が40数分で半々だったのが謎すぎる。Cはハミルトン路判定で、間に合うのかよと思いながらやったので。ちなみに先週は用事でABCもARCも出れなかったし、今週勉強してなくてボケボケでできそうになかったけど意外とこの成績だったのだった。実は酒のんでなくて、早寝しているというのも今週はいつもと違うのだが…。
B - Find snuke
o 18分かかったっぽい。遅いよね。Gに時間取れなかった原因なわけで…。ということでちゃんとBから反省だ!といっても方針は全マス全方位チェック、まあこれでいいよなぁ。単にこれを速く書けてないってことか。 2023-05-20
C - Almost Equal
o N = 8、M = 5。O(N!)か。21分もかかってしまった。グラフ作ってハミルトン路を全頂点からのDFSをして判定としていた。ハミルトン路を調べるのに時間がかかってしまった。解説見るとN!通りの順列を全部調べれば良いと書いてある。確かに気づけばそれが一番いいか。8! = 40320。これは覚えておかねば。っていうか階上ってどう変化するんだろう?うわー。11くらいが限界かなぁ。11!で4000万くらい。12!でもう5億に。 2023-05-20
8! = 40320
9! = 362880
10! = 3628800
11! = 39916800
12! = 479001600
G - Sort from 1 to 4
o 終了後に解けた。コードスッキリでいい感じ。 2023-05-20
from collections import Counter
N = int(input())
alist = list(map(int, input().split()))
acount = Counter(alist)
X = [[0]*5 for _ in range(5)] # [i][j] count j in range
cur = 0
for i in range(1, 5):
nex = cur + acount[i]
for j in range(cur, nex):
X[i][alist[j]] += 1
cur = nex
ans = 0
from itertools import permutations
for count in range(2, 5):
for sel in permutations(range(1, 5), count):
rem = X[sel[-1]][sel[0]]
for i in range(len(sel)-1):
rem = min(rem, X[sel[i]][sel[i+1]])
ans += rem * (count-1)
X[sel[-1]][sel[0]] -= rem
for i in range(len(sel)-1):
X[sel[i]][sel[i+1]] -= rem
print(ans)AtCoder Beginner Contest 303
5完で順位は悪かったが、水パフォだった。Cの問題文がひどいと感じた。ここで30分もかかった上に3ペナ。大きくパフォーマンスを下げて入水ならなかった。
C - Dash
o 上記の通り、トラブりまくって大きくパフォーマンスを下げる原因となった。「高橋君が一度も倒れることなくN回の移動を行えるか判定してください。」という問題だが、N回移動したあとで倒れるのをOKとするとWAが発生する。さすがに酷いと思った。あと同じ場所のアイテムは一度消費すると使えなくなるというのも、最初実装していなくてバグっていた。「消費したアイテムは使えなくなります」くらいていねいに書いて欲しい。コンテスト時間中に解釈のブレで苦労したくない。 2023-05-27
F - Damage over Time
どうも難しかったらしく、時間内に200人くらいしか解けてなかった。コンテスト中には時間切れになったが、閃きかけていたような感触だったので、そんなに難しいの?というのがいまいちピンとこない。コンテスト中、2分探索だろうと思っていて、その後終わってから風呂で考えていたら、2分探索は不要で、ただの積分かな?というのが現在の結論。一応頭の中では解き方まで導けているが、面倒そうな感じはする。 2023-05-27
o 黃Diffだが自力で解いた。難しくてめんどいが、いい問題だなぁと思った。N = 300000(魔法の数)、H = 10^18(モンスターの体力)。t幅の時間、モンスターの体力をd減らせる魔法で、最短時間でモンスターを倒すと何ターン目で倒せる?しばらく熟考してると、Tで倒す場合、1、2、3、…、Tのそれぞれの時間で最大の攻撃ができる魔法を使えば良いとわかる。魔法の効く時間tより長ければその魔法で減らせる体力はtdで確定。tよりも短い時間sであれば、sかけるdの攻撃となるので、dが一番でかいものが良い。なので、1、2、3、…において最大の攻撃を順番に実行していき、Hを超えたところが答えというちょっと意外な結論になる。ただ、1ずつ進めていくと、モンスターの体力は10^18もあるので、TLE不可避w、よって、魔法の継続時間と継続時間の間を関数で埋めていくような処理にすると、計算量が魔法の数Nに収まって、間に合うことになる。コンテスト時間中に実装しきれる気はしないけど、コツコツ続けていると整理するのもうまくなればよいなぁ。これくらも自力ACできるようになったのは喜ぶべきこと。yellow 2023-06-17
import heapq
N, H = map(int, input().split())
TD = []
dmax = t1dmax = 0
for _ in range(N): # time, damage
t, d = map(int, input().split())
TD.append((t, d))
dmax = max(dmax, d)
if t == 1:
t1dmax = max(t1dmax, d)
if t1dmax != dmax:
N += 1
TD.append((1, dmax)) # add max for convenience
TD.sort(key=lambda x:x[0]) # sort by time
pq = []
for i, td in enumerate(TD):
heapq.heappush(pq, (-td[1], i))
removed = [False]*N
itd = 0
F = 0 # F means fix
ans = 0
while itd < N and H > 0:
t = TD[itd][0]
while itd < N and TD[itd][0] == t:
F = max(F, TD[itd][0]*TD[itd][1])
removed[itd] = True
itd += 1
while pq and removed[pq[0][1]]:
heapq.heappop(pq)
if pq: # equivalent to itd < N
nt = TD[itd][0]
K = -pq[0][0]
T = F // K
Fr = min(T+1, nt)
if t < Fr:
damage = F * (Fr - t)
if damage >= H:
ans = t + H // F + (1 if H % F != 0 else 0) - 1
break
else:
H -= damage
Kl = max(T+1, t)
if Kl < nt:
damage = K * (Kl + nt - 1) * (nt - Kl) // 2
if damage >= H:
l = Kl
r = nt
while l + 1 < r:
m = (l + r) // 2
curd = K * (Kl + m - 1) * (m - Kl) // 2
if curd < H:
l = m
else:
r = m
ans = r - 1
break
else:
H -= damage
else:
ans = t + H // F + (1 if H % F != 0 else 0) - 1
break
print(ans)G - Bags Game
x N = 3000(袋の数)。O(N^2)。スライド最小値というアルゴリズムを使ったらO(N^2)になった。区間DPでいける。しかしO(N^3)になっちゃうなぁ。でもBとかDが大きいと遷移幅と打ち消しあって計算量が減ったりして間に合うのかなぁ、などと無駄な期待をして提出したら案の定半分くらいTLEだった。よく見ると特定の幅をの最小値を求める問題になっており、O(N)で計算しておけば、あとでループしながら最小値を求めなくても、使いまわせる。聞けばたしかにスライド最小値で解けるとわかるが、この問題は持ち込むためにも処理が必要で、結構複雑でスムーズに整理できない。スライド最小値が初めてだったからってのもあるだろうし、勉強になったしよかった。な。orange 2023-06-17
from collections import deque
N, A, B, C, D = map(int, input().split()) # A -> take B, C -> take D
X = list(map(int, input().split()))
Xsum = [0]*(N+1) # [0] is 0 dummy Xsum[1] is X[0]
for i in range(1, N+1):
Xsum[i] = Xsum[i-1] + X[i-1]
dp = [[-10**15]*N for _ in range(N)]
for i in range(N): # take 1
dp[i][i] = X[i]
for n in range(2, B+1): # take n with A
for j in range(n-1, N):
i = j - n + 1
dp[i][j] = Xsum[j+1] - Xsum[i] - A
for n in range(2, D+1): # take n with C
for j in range(n-1, N):
i = j - n + 1
dp[i][j] = max(dp[i][j], Xsum[j+1] - Xsum[i] - C)
for n in range(1, N+1): # when n left
if n == 1:
for i in range(N):
dp[i][i] = X[i] # this is the best
continue
else: # n >= 2
for j in range(n-1, N):
i = j - n + 1
dp[i][j] = max(dp[i][j], X[i] - dp[i+1][j], X[j] - dp[i][j-1])
if n <= B:
for j in range(n-1, N):
i = j - n + 1
dp[i][j] = max(dp[i][j], Xsum[j+1] - Xsum[i] - A)
else:
m = n - B # take B and leave m
sub = [0]*N
for k in range(N-m+1): # kから始まる幅mの値
sub[k] = Xsum[k+m] - Xsum[k] + dp[k][k+m-1]
slidemin = [0]*N
q = deque([])
for i in range(B+1):
while q and sub[q[-1]] >= sub[i]:
q.pop()
q.append(i)
slidemin[0] = sub[q[0]]
for i in range(1, N-n+1): # i-1を消してi+Bを入れてslidemin[i]確定
if q[0] == i-1:
q.popleft()
while q and sub[q[-1]] >= sub[i+B]:
q.pop()
q.append(i+B)
slidemin[i] = sub[q[0]]
for j in range(n-1, N):
i = j - n + 1
total = Xsum[j+1] - Xsum[i]
dp[i][j] = max(dp[i][j], total - A - slidemin[i])
if n <= D:
for j in range(n-1, N):
i = j - n + 1
dp[i][j] = max(dp[i][j], Xsum[j+1] - Xsum[i] - C)
else:
m = n - D # take D and leave m
sub = [0]*N
for k in range(N-m+1):
sub[k] = Xsum[k+m] - Xsum[k] + dp[k][k+m-1]
slidemin = [0]*N
q = deque([])
for i in range(D+1):
while q and sub[q[-1]] >= sub[i]:
q.pop()
q.append(i)
slidemin[0] = sub[q[0]]
for i in range(1, N-n+1): # i-1を消してi+Dを入れてslidemin[i]確定
if q[0] == i-1:
q.popleft()
while q and sub[q[-1]] >= sub[i+D]:
q.pop()
q.append(i+D)
slidemin[i] = sub[q[0]]
for j in range(n-1, N):
i = j - n + 1
total = Xsum[j+1] - Xsum[i]
dp[i][j] = max(dp[i][j], total - C - slidemin[i])
print(dp[0][N-1])AtCoder Regular Contest 161
2完。入水目指していたがならず。冷やしてしまった。もうちょっとだと思うんだけど、マジで心折れる。気持ち悪すぎてストレスが半端ない。助けてください。Cは青Diffで、まあまあ難しかったらしいが、コンテスト中に閃いて実装していたが、間に合わなかった。こういうの精神的にきつい。コンテスト終了後、自力ACできた。確かに難しいし、これが自力でできるんだから、入水させてくれ。ていうかAも注意不足でバグが発生して時間かかってて、Cもそんな感じで結構時間がかかったから、「結局注意不足でバグる」という部分を解決しないとパフォーマンスは伸びないと思う。時間かかっちゃってるから。時間かかったら後ろの問題解けない。それはあたりまえで、そりゃそうだろうということ。いや、C自力でいけるんだよ。時間内にいったら確実に入水なんだよ。ストレスが尋常じゃないんだ。助けてくれ。2週間断酒してたけど今2週間ぶりにビール飲んでる。昨日寝れなかったんだよね。断酒+ABC303中のコーヒーが原因かなと思ってる。
A - Make M
o N = 200000。O(N)。考えていると奇数番目はソートした下半分、偶数番目はソートした上半分でいいとわかる。貪欲にいかない理由はないので。で、奇数番目に配置する数字の最大と偶数番目に配置する数字の最小が異なれば何も問題なく、Mにできる。同じ場合どういう条件か?まあ、考えたらわかった。で実装したらバグりまくり。for文でbreakすべきところでしてなかったというバグ。不注意。55分使ってしまい、辛すぎる。Cが解けたら入水というところで、Cに十分時間を使えない原因を、このAで作ってしまった。本当につらい。 2023-05-28
import sys
N = int(input())
enum = N // 2 # 偶数
onum = enum + 1
alist = list(map(int, input().split()))
alist.sort()
if N == 1:
print('Yes')
sys.exit()
if alist[enum] < alist[enum+1]:
print('Yes')
sys.exit()
M = alist[enum]
a = b = c = d = 0
for i in range(onum):
if alist[i] == M:
a = i
b = onum-i
break
for i in range(onum, N)[::-1]:
if alist[i] == M:
c = i-enum
d = N-1-i
break
if a == 0:
print('No')
sys.exit()
if c <= a-1 and d >= b:
print('Yes')
sys.exit()
print('No')C - Dyed by Majority (Odd Tree)
o N = 200000(頂点数)。O(N)だろう。木DPも慣れたもので、こんな難しい問題も自力で解けてしまう。青Diff?rootの扱いでバグ修正に時間がかかったので、もしAが短時間で片付けていても、結局Cをコンテスト時間内に解くことは難しかったかも。今回Dの方が簡単だったらしいが、ぼくは順番にやるし、Aでトラブらず、このCをACして華麗に入水したかった。あーあー。 2023-05-28
T = int(input())
for _ in range(T):
N = int(input())
G = [[] for _ in range(N)]
for _ in range(N-1):
A, B = map(int, input().split())
A -= 1
B -= 1
G[A].append(B)
G[B].append(A)
S = list(input())
if N == 2:
S.reverse()
print(''.join(S))
continue
root = 0
for v in range(N):
if len(G[v]) > 1:
root = v
break
P = [-2]*N
P[root] = -1
ans = [None]*N
stack = [~root, root]
NG = False
while stack:
cur = stack.pop()
if cur >= 0:
for nex in G[cur]:
if P[nex] == -2:
P[nex] = cur
stack.extend([~nex, nex])
else:
cur = ~cur
if len(G[cur]) == 1: # leaf
p = P[cur]
if ans[p] is None:
ans[p] = S[cur]
elif ans[p] != S[cur]:
NG = True
break
ans[cur] = S[p]
else:
deg = len(G[cur])
count = 0
for nex in G[cur]:
if nex == P[cur]:
continue
if ans[nex] is None:
ans[nex] = S[cur]
count += 1
elif ans[nex] == S[cur]:
count += 1
need = deg // 2
if count > need:
pass
elif cur != root and count == need:
p = P[cur]
if p >= 0:
if ans[p] is None:
ans[p] = S[cur]
elif ans[p] != S[cur]:
NG = True
break
else:
NG = True
break
if NG:
print(-1)
else:
if ans[root] is None:
ans[root] = 'W'
print(''.join(ans))D - Everywhere is Sparser than Whole (Construction)
o ND = 50000。密度Dの定義は辺数/頂点数、Nは頂点数、つまり、NDが辺数であり、次数の合計は2NDで、次数の平均が2D。Dは整数であるという条件もある。真部分集合の誘導部分グラフの密度がD未満になるグラフを構築せよという問題。考えていると自然に気づく。全頂点に平均次数が分散してすべての頂点の次数が2Dとすると、頂点を消すたびに減っていくことに。で、最初全頂点に2Dを割り振り、つなぐたびに0になるまでそれを消費していくという方法を考えた。頂点iでループして、つなぐ先は常にiより大きい頂点とする。するとWAが大量発生した。なんでかと思ったら、その方法だと、(解くときに頭の中でイメージしていた)連結グラフではなく、複数の2D+1頂点の完全グラフに分離してしまう。すると完全グラフをまるごと消して部分集合を作った場合、密度はDに戻ってしまい、条件を満たさない。なかなかの罠だ。解説の方法はすべての頂点に対して、両隣N点ずつを結ぶ。対称性を維持しながらグラフを作ることができて良い。かなりシンプルなコードで完了。Cより簡単というのはうなずける。lb 2023-06-03
N, D = map(int, input().split())
if 2*D > N-1: # degree is maximum N-1
print('No')
else:
print('Yes')
for i in range(1, N+1): # 1...N-1 to 2...N
for j in range(i+1, i+D+1):
if j > N:
j -= N
print(i, j)AtCoder Beginner Contest 304
ABCDE、5完。攻撃によりジャッジが詰まり、コンテスト時間20分延長。Eのジャッジ結果は終了の23時までわからなかった。長時間結果わからないのはキツい。Fを考えていて、ほぼ諦めてるところで延長で、割とつらかったが、最後まで取り組んだ。F、水色上位は解けるレベルだったようだけど、なかなか難しかった。ぼくは終了後解説見て勉強した。
D - A Piece of Cake
o N = 200000(イチゴの数)。A = B = 200000(ケーキカット箇所数)。O(N + (Log N)^2)っぽい?イチゴの位置とカット位置が与えられ、1片に乗ってるイチゴの最大、最小数を求める。カット位置が両方向200000あるので、カット位置でループすると間に合わない。1方向でソートし、カット位置でループしてまずイチゴを分けて、その中ではもう一度別の方向でイチゴをソートし、イチゴでループしながら2分探索でカット位置を決める。イチゴの数が合計200000なので、計算量を抑えられるはず。1回で通ったが30分かかった。みんなこれ時間かからないのかな。 2023-06-03
F - Shift Table
x N = 100000。O(Nの約数の数)?とりあえず約数というのはまあまあ少ないので、計算量増えない。しかしこれはコンテスト時間が20分伸びて50分考えてもお手上げになってしまった。これが解けないと入水は厳しそうということで、なんだかんだ言って水Diffの問題でも全然抜けてるところがある現実を痛感する。コツコツ積み上げていくしかない。小さい約数で作ったシフトテーブルが大きい約数で作ったシフトテーブルとかぶっているケースを省く方法がわからなかった。数え上げで、どうやれば排他的に数えられるか?はいつも乗り越えるべき課題だ。Nの約数は1から順にNを割って、小さい順に列挙していける。この場合、排他的であるためには、その約数より小さい約数では現れないことが重要。6で作ったシフトテーブルを数えると、1、2、3で作ったシフトテーブルが含まれてしまう。よって、6以下に現れないものを数えるには、1で初めて現れるシフトテーブル、2で始めて、3で初めて、を全部引けば良い。約数を小さい順に列挙しているので、約数の約数はすでに調査済みだ。だから引けばその約数で初めて出てくるものを数えることができる。6で作るパターンに2で作るパターンは全部含まれるっていう感覚も大事だな。条件を満たすシフトテーブルをすべて作っているのだから、当たり前なんだけども。 2023-06-04
M = 998244353
N = int(input())
S = list(input()) # # is work . is off
mincx = {}
for cycle in range(1, N):
if N % cycle == 0:
count = 0
# 高橋休みあり -> 出社確定、他(count) -> 選べる
for i in range(cycle):
j = i # check S[j]
while j < N:
if S[j] == '.':
break
j += cycle
else:
count += 1
cur = pow(2, count, M)
for c, x in mincx.items():
if cycle % c == 0:
cur -= x
mincx[cycle] = cur % M
print(sum(mincx.values()) % M)G - Max of Medians
x ★ N = 100000。数列の長さは2N = 200000。ビット数d = 30。O(Nd log(d))のはず。解説読んでもなかなか理解できず。かなり苦労した。数列Aの中で適当にペア作ってXORし、できた値の中央値の最大を求めよという問題。中央値を求めると言われると、「は?できるかよ」とひるんでしまうが、こういうのは確かに二分探索だったりする。つまりx以上のペアを何個作れるか?という問題を解いて、個数が半分になるところを二分探索で調べれば値が求まるというもの。この解説、理解に苦労した。しっかり整理して順序立てて考えれば確かにそうだが、これは難しい。再帰関数を使って解くが、他の方法は考えられない気がする。最初再帰呼び出しのたびにリストを作って渡していたが、TLEx6となったので、やめた。Aを最初にソートしておけば、kビット目が0になるものと1になるものは、左右に分離しているので、再帰呼び出し時に部分範囲を渡していくだけとわかる。これを直してもTLEx6、変わらず。幅0のときに、0ビット目のベースケースまで処理せず、return 0できることがわかるので、それを実装して、制限時間5秒のところ、1427msとなった。5人のPython勢ACでは最速でうれしい。やはり赤Diffは難しいし、おもしろいし、勉強になる。red 2023-07-01
自分の中で過去トップレベルでムズい。
— あのこね10歳 anoconne (@anoconne) June 30, 2023
N = int(input())
A = list(map(int, input().split()))
A.sort()
def g(cl, cr, dl, dr, x, k):
global A
if cl == cr or dl == dr:
return 0
bit = 1 << k
c0r = cl
while c0r < cr and 0 == A[c0r] & bit:
c0r += 1
c1l = c0r
lenc0 = c0r - cl
lenc1 = cr - c1l
d0r = dl
while d0r < dr and 0 == A[d0r] & bit:
d0r += 1
d1l = d0r
lend0 = d0r - dl
lend1 = dr - d1l
if x & bit:
if k == 0:
return min(lenc0, lend1) + min(lenc1, lend0)
else:
return g(cl, c0r, d1l, dr, x, k-1) + g(c1l, cr, dl, d0r, x, k-1)
else: # xk == 0
if k == 0:
return min(cr-cl, dr-dl) # all
elif lenc0 <= lend1 and lenc1 <= lend0:
return lenc0 + lenc1
elif lend0 <= lenc1 and lend1 <= lenc0:
return lend0 + lend1
elif lenc0 < lend1 and lend0 < lenc1:
return lenc0 + lend0 + min(lenc1-lend0, lend1-lenc0, g(c1l, cr, d1l, dr, x, k-1))
else: # lenc1 < lend0 and lend1 < lenc0
return lenc1 + lend1 + min(lenc0-lend1, lend0-lenc1, g(cl, c0r, dl, d0r, x, k-1))
def f(bl, br, x, k):
global A
if bl == br:
return 0
bit = 1 << k
b0r = bl
while b0r < br and 0 == A[b0r] & bit:
b0r += 1
b1l = b0r
lenb0 = b0r - bl
lenb1 = br - b1l
if x & bit:
if k == 0:
return min(lenb0, lenb1)
else:
return g(bl, b0r, b1l, br, x, k-1)
else: # xk == 0
if k == 0:
return (br - bl) // 2
elif lenb1 < lenb0:
return lenb1 + min(lenb0-lenb1, f(bl, b0r, x, k-1))
elif lenb0 < lenb1:
return lenb0 + min(lenb1-lenb0, f(b1l, br, x, k-1))
else: # lenb1 == lenb0:
return lenb0
need = (N+1) // 2
l = 0
r = 2**30
while l+1 < r:
m = (l+r) // 2
if f(0, 2*N, m, 30) < need:
r = m
else:
l = m
print(l)AtCoder Beginner Contest 306
ボロボロでしたが、なぜかUnratedでした。Eが苦手な感覚が強く、しんどい。
E - Best Performances
o ★ めっちゃ苦手。上位K個をsetで管理してたらTLE、やめたら4.5秒になってなんとかACできた。1度こういうのやったことあって、その時もしんどーって思った記憶が強い。苦手だー。set使ったらTLEってのもいやだ。プライオリティキュー使ってるので、削除の別管理が必要だけど、同じインデックスの数字がどんどん変わっていくので、version管理して、プライオリティキューに(値, インデックス, バージョン)という3要素もあるタプルを追加して管理した。バージョンが古いものは削除済みとみなす。削除済みとみなす必要があるものは、popが必要なときに全部先にpopしてから本当に欲しい値にたどり着けるというしくみになっている。Pythonのheapqで、AtCoderで使えるバージョンでは、特定のキーだけ見てソートできず、3要素入れちゃうと時間がかかるのが難点。仕方ないが。この問題めっちゃ苦手だけど、みんなさっと解けるの、なんでやねん。lb 2023-06-18
import heapq
N, K, Q = map(int, input().split())
version = [0]*(N+1)
value = [0]*(N+1) # real value
big = [False]*(N+1)
bigcount = 0
#bigset = set()
pqbig = [] # (a, id, version) 小さいものが[0]
pqsmall = [] # (-a, id, version) 大きいものが[0]
ans = 0
for _ in range(Q):
x, y = map(int, input().split())
if version[x] == 0 and bigcount < K:
#bigset.add(x)
big[x] = True
bigcount += 1
version[x] = 1
value[x] = y
heapq.heappush(pqbig, (y, x, 1))
ans += y
elif version[x] > 0 and big[x]:
#bigset.remove(x)
big[x] = False
version[x] += 1
ans -= value[x]
value[x] = y
heapq.heappush(pqsmall, (-y, x, version[x]))
while pqsmall and pqsmall[0][2] < version[pqsmall[0][1]]:
heapq.heappop(pqsmall)
sy, sx, sv = heapq.heappop(pqsmall)
#bigset.add(sx)
big[sx] = True
heapq.heappush(pqbig, (-sy, sx, sv))
ans -= sy
else:
version[x] += 1
value[x] = y
if y <= pqbig[0][0]:
heapq.heappush(pqsmall, (-y, x, version[x]))
else:
ans += y
#bigset.add(x)
big[x] = True
heapq.heappush(pqbig, (y, x, version[x]))
while pqbig and pqbig[0][2] < version[pqbig[0][1]]:
heapq.heappop(pqbig)
by, bx, bv = heapq.heappop(pqbig)
ans -= by
#bigset.remove(bx)
big[bx] = False
heapq.heappush(pqsmall, (-by, bx, bv))
print(ans)F - Merge Sets
o N = 10000(数列数)、M = 100(数列長さ)。O(NM Log(NM))のはず。全部ソートして何番目か見ればいいんじゃない?って思ったけど、f(Si,Sj)をカウントする条件がi<jなので、順番に追加していく必要がある。座圧してフェニック木でカウントできるなーと思うけど、自分自身は別にカウントしてあとで加える必要があり、その扱いでミスしてて、バグって修正に時間がかかった。ちゃんと整理しないとダメねぇ。lb 2023-06-18
N, M = map(int, input().split())
As = []
all_ = []
for _ in range(N):
As.append(list(map(int, input().split())))
all_.extend(As[-1])
As[-1].sort()
all_.sort()
a2i = {a:i+1 for i, a in enumerate(all_)}
bit = BIT(N*M+1)
ans = 0
for j in range(N)[::-1]:
for a in As[j]:
if j < N-1:
ans += bit.prod(a2i[a])
for k, a in enumerate(As[j]):
i = a2i[a]
bit.add(i, 1)
if j < N-1:
ans += (k+1) * (N-j-1)
print(ans)G - Return to 1
x N = 200000(頂点数)、M = 200000(有効辺数)。O(N Log N)かな。強連結成分分解はO(N+M)なの?なので、最大公約数の処理が一番効いてくるのでN Log Nになる気がする。数学的な背景が最初わからなかったので、解けなかったけど、勉強になったし、すごくおもしろい問題だ。1から1に戻る、ちょうど10^(10^100)回で。この回数は2と5だけが約数ってことと、むちゃくちゃでかいってことだけに意味がある。1から1に戻るので、強連結成分分解するのは当然だろう。そして同じ強連結成分の中だけを調べればいい。で、2と5だけの倍数回で1に帰ってくる方法があるか?ax+byの値は、aとbの最大公約数の倍数しか取らないことが知られている。(これはユークリッドの互除法や1次不定方程式の話の中で出てくるような内容。)1から1に戻る距離aとbがあって、その最大公約数が2と5のみを約数に持てば、適切x、yを設定することで10^(10^100)回にできそうだ。aやbの取りうる値は無限にあるのでどうするか?というと、最大公約数を求めるときに、aとbがわかっていなくても、aと「aとbの差」がわかっていればいい。これはユークリッドの互除法の原理と同じ。なので、BFSで1から1までの取りうる距離を求めつつ途中ですでに通った頂点に戻ったり、合流したときは、別の経路でその頂点に到達したときの距離との差を記録していく。するとaやbの取りうる値を全列挙しなくても、その差として取りうる値は列挙できるので、それらの差の集合を使って最大公約数を求めることができる。数学的な背景がなかなか難しいし、おもしろい。ついでに拡張ユークリッドの互除法など見直して、以前ちょっと消化不良だなーと思ってたのも復習してよくわかって知識を定着できたような気がする。おもしろい。ってあれ?なんか変だな。3変数で作る場合考えないと。って思ったら、aとbの最大公約数をdとすると、ax+byをdwとおけるのか。すると、ax+by+cz = dw+czは、dとcの最大公約数の倍数にできることになって、結局全部の数字の最大公約数の倍数を作れるのか。このa,b,cの並びは多ければ多いほど、最大公約数は小さくなっていくので、確かに全部つっこんで最大公約数を求めて、それが、2と5のみを約数に持つかどうか調べるのが最適な考え方。あらためておもしろい。orange 2023-06-20
from collections import deque
T = int(input())
for _ in range(T):
N, M = map(int, input().split())
G = [[] for _ in range(N)]
for _ in range(M):
a, b = map(int, input().split())
G[a-1].append(b-1)
Grev = [[] for _ in range(N)]
for v in range(N):
for next in G[v]:
Grev[next].append(v)
kaeri = []
t_order = [-1]*N
used = []
def dfs(v):
stack = [~v, v]
while stack:
cur = stack.pop()
if cur >= 0:
if used[cur]:
stack.pop()
continue
used[cur] = True
for next in G[cur]:
if not used[next]:
stack.extend([~next, next])
else:
kaeri.append(~cur)
def rdfs(v, k):
used[v] = True
stack = [v]
t_order[v] = k
while stack:
cur = stack.pop()
for next in Grev[cur]:
if not used[next]:
used[next] = True
stack.append(next)
t_order[next] = k
# scc
used = [False]*N
for v in range(N):
if not used[v]:
dfs(v)
used = [False]*N
k = 0
for v in reversed(kaeri):
if not used[v]:
k += 1
rdfs(v, k)
res = []
theto = t_order[0]
dists = [-1]*N
used = [False]*N
q = deque([0])
used[0] = True
dists[0] = 0
while q:
cur = q.popleft()
for nex in G[cur]:
if t_order[nex] == theto:
if not used[nex]:
q.append(nex)
used[nex] = True
dists[nex] = dists[cur] + 1
else:
if nex == 0:
res.append(dists[cur] + 1)
else:
d = dists[cur] + 1 - dists[nex]
if d != 0:
res.append(d)
if not res:
print('No')
else:
gcd = res[0]
for i in range(1, len(res)):
a, b = gcd, res[i]
while b:
a, b = b, a % b
gcd = a
while gcd % 2 == 0:
gcd //= 2
while gcd % 5 == 0:
gcd //= 5
if gcd == 1:
print('Yes')
else:
print('No')AtCoder Regular Contest 162
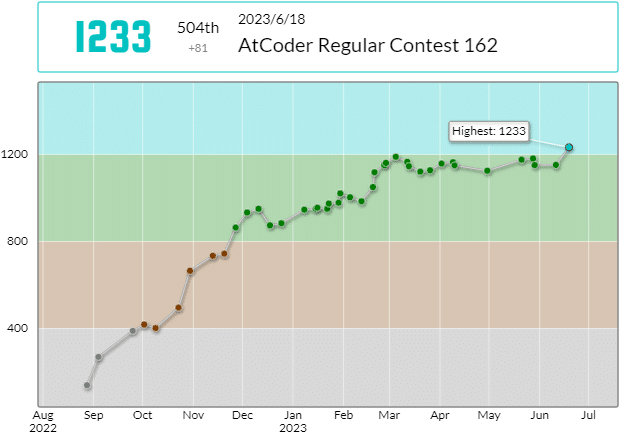
ついに入水しました。ABC、3完。3月4日に、ABC292でRating 1189になったときは、もうすぐに入水できると思っていたのですが、そこから3ヶ月半も(!)かかってしまいました。毎回、そろそろいけるだろうと期待しまくって参加してるので、その反動で落胆もすさまじく、長い期間かなりのフラストレーションを感じていました。次のチャンスは1週間後かぁ、と、悶々と平日を過ごすのです。気分が晴れません。入水したらあれをやるぞ、これを買うぞみたいなことを頭の中で考えながら「入水してないからできない」と、身動きがとれないのです。それだけに、達成感というより、解放感みたいなものも感じています。脱落するかもしれませんが、まあひとまずヨシ!です。今回、Bを54:10に、Cを108:55にACしました。なかなかの粘りです。それぞれ苦労があり、よっしゃ解けたと思いましたが、過去のコンテストで、よくできたと思っても、自分が解けたらみんな解けているということが多く、パフォーマンスが伸びないというのは何度も経験しています。しかし今回は、パフォーマンスが初の青パフォで1777、順位も過去最高で504位でした。Acceptedがこのコンテストの直前で499、終了時に502という状況で、Accepted 500を超えると同時に入水したことになります。始めて半年とか、Rated35回とか40回とか、意識したけど逃したタイミングはいろいろありましたが、Accepted 500ってのも中々わかりやすいタイミングです。緑期間はほぼ半年でした。個人的には他にも象徴的な意味があったりしますが。
#ARC162 で、入水しました。
— あのこね10歳 anoconne (@anoconne) June 18, 2023
キタ━━━━(゚∀゚)━━━━!! pic.twitter.com/41q6EiONOs
A - Ekiden Race
o N = 1000(人数)。O(N^2)。復路で抜かれてなければ、区間賞だったかもしれない。結構難しい。復路で抜かれた人の数をカウントして、全体から引けばよい。人数が少ないので普通にN^2でカウント。 2023-06-18
T = int(input())
for _ in range(T):
N = int(input())
P = []
for i, p in enumerate(map(int, input().split())):
P.append((p, i+1))
P.sort(key=lambda x:x[0])
ans = 0
for i in range(N):
p, j = P[i]
for x in range(i):
if P[x][1] > j:
ans += 1
break
print(N-ans)B - Insertion Sort 2
o N = 1000。O(N^2)のはず。並んだ2つを同時に移動するので、偶置換しかできない。よって転倒数が奇数の場合はNo、偶数なら必ずできる。1から順に並べていけば良い。しかし次正しい位置に移動したい数字が、1番うしろにある場合は、一旦後ろでない位置に移動してから移動すれば良い。すると2回の移動が必要になる可能性があるが、2000回以内には必ず収まることがわかる。で、ぼくはPythonで解いている。リスト操作で中間のリストを消したり、挿入したりというのはO(N)かかる。しかしN = 1000でO(N^2)に収まるので、気にせずリスト操作をした。なので、今まで競プロで使ったことがないリスト操作をした。その判断ができたのは良いこと。計算量の見積もり大事。g 2023-06-18
N = int(input())
P = list(map(int, input().split()))
count = 0
for i in range(N-1):
for j in range(i+1, N):
if P[i] > P[j]:
count += 1
if count % 2 == 1:
print('No')
else:
print('Yes')
ans = []
for x in range(1, N+1): # 値xを正しい位置[x-1]に
for i in range(N):
if P[i] == x:
break
if i == x-1:
continue # do nothing
if i == N-1:
ans.append((N-1, N-3))
A = P[:N-3]
B = P[N-3]
move = P[N-2:]
P = A + move
P.append(B)
for i in range(N):
if P[i] == x:
break
if i == x-1:
continue # do nothing
ans.append((i+1, x-1))
A = P[:i]
move = P[i:i+2]
if i+2 < N:
A.extend(P[i+2:])
A[x-1:x-1] = move
P = A
print(len(ans))
for x in ans:
print(*x)C - Mex Game on Tree
o N = 1000(頂点数)。O(N Log(N))かな?問題読むと、ムズッと思って、考察がおもしろかった。最初は全然見当つかないけど、考えてるうちにちょっとずつ見えてくる。mexをKにするためには、すべて確定していてmex Kの部分木があるか、1つ確定していなくて0からK-1まで全部使われているか、0からK-1までのうち1つだけ抜けているか、という状態の部分木が存在する必要がある。最初気づいていなくて1ペナになったのだけど、確定していないのが2つある時点で、Bobはその部分木をつぶせる。Kを入れてしまえばmexはKにならないから。これに最初気づいていなくて、1ペナ。おもしろい問題解けてよかった。この青Diffを解けたおかげで、最高順位、最高パフォーマンスで入水につながった。今までこの1歩が間に合わなくて泣き続けていた。blue 2023-06-018
T = int(input())
for _ in range(T):
N, K = map(int, input().split())
P = [-1]*(N+1) # 1 is root
C = [[] for _ in range(N+1)] # children
for i, p in enumerate(map(int, input().split())):
P[i+2] = p
C[p].append(i+2)
A = [-1] + list(map(int, input().split()))
UK = [set() for _ in range(N+1)] # count 0..K-1 in sub tree
HK = [False for _ in range(N+1)] # has K in sub tree
Q = [0]*(N+1) # count -1
stack = [~1, 1]
while stack:
cur = stack.pop()
if cur >= 0:
for c in C[cur]:
stack.extend([~c, c])
else:
cur = ~cur
for c in C[cur]:
UK[cur] |= UK[c]
Q[cur] += Q[c]
if HK[c]:
HK[cur] = True
if 0 <= A[cur] < K:
UK[cur] |= {A[cur]}
elif A[cur] == -1:
Q[cur] += 1
elif A[cur] == K:
HK[cur] = True
for i in range(1, N+1):
if HK[i]:
continue # mex cannot be K
left = K - len(UK[i])
if left == 0 and Q[i] <= 1:
print('Alice')
break
if left == 1 and Q[i] == 1:
print('Alice')
break
else:
print('Bob')Educational DP Contest / DP まとめコンテスト
A - Frog 1
o 2023-04-19
B - Frog 2
o 2023-04-19
C - Vacation
o 2023-04-19
D - Knapsack 1
o 2023-04-20
E - Knapsack 2
o 問題Dと制限が異なることで、悩んでしまう。問題DではWが10^5以下という制限があり、100個以下だったので、重さの合計が10^7に収まっており、これをDPのパラメーターに使えたが、今回はWが10^9。これをパラメーターに使うと計算量が増大してしまう。が、問題Dで10^9以下だったvが、10^3以下と縮小されている。このおかげでvの合計をパラメーターに使うことで計算量を抑えられる。つまり同じ価値の時にできるだけ軽くする。しかしこの見方の転換はなかなかトリッキーで不思議な感じがする。問題Dと並べて露骨に違いが強調されて出てきたから解けたのかもしれないと思ったりする。 2023-04-20
F - LCS
x めっちゃ典型っぽい問題なのに難しい。最長の共通部分列の長さ、だけでなく実際の例も回答する問題。遷移の式を導ければ解ける。しかし全体的に見てるとなぜか導けない。あえてs[i]とt[j]だけに注目すると見えてくる。s[i] == t[j]かどうか?で分岐する遷移。 2023-04-24
s = list(input())
t = list(input())
lens = len(s)
lent = len(t)
dp = [[0]*(lent+1) for _ in range(lens+1)]
for i in range(1, lens+1):
for j in range(1, lent+1):
if s[i-1] == t[j-1]:
dp[i][j] = dp[i-1][j-1] + 1
else:
dp[i][j] = max(dp[i-1][j], dp[i][j-1])
ans = []
i, j = lens, lent
while True:
if s[i-1] == t[j-1]:
ans.append(s[i-1])
i -= 1
j -= 1
elif dp[i-1][j] >= dp[i][j-1]:
i -= 1
else:
j -= 1
if i == 0 or j == 0:
break
print(''.join(reversed(ans)))G - Longest Path
x 難しい。トポロジカルソートして後ろから順番に調べると、子から親へという遷移順が保証される。この考え方は大事そう。 2023-04-25
H - Grid 1
o 2023-04-25
I - Coins
o 表が上回らない確率を1から引く。 2023-04-25
J - Sushi
x ★ 難しい。遷移式がこれでいいのか?って思っている。しかし、この遷移式を見て、銀のエンゼルが5枚出るまでのチョコボールの購入回数の期待値が、1枚出るまでの購入回数の期待値の5倍であることを導けた。変なめぐり合わせだよ。残りn個の皿がm枚という状態で期待値が決まるはずなので、それで遷移を書く。 2023-04-26
N = int(input())
count = [0, 0, 0, 0]
for a in map(int, input().split()):
count[a] += 1
def idx(i, j, k):
return i + j*(N+1) + k*(N+1)**2
dp = [0]*((N+1)**3)
dp[0] = 0.0
for k in range(N+1):
for j in range(N+1):
for i in range(N+1):
if i == j == k == 0:
continue
z = N - i - j - k
temp = 1.0
if i > 0:
temp += dp[idx(i-1, j, k)] * i / N
if j > 0 and i+1 <= N:
temp += dp[idx(i+1, j-1, k)] * j / N
if k > 0 and j+1 <= N:
temp += dp[idx(i, j+1, k-1)] * k / N
dp[idx(i, j, k)] = temp / (1 - z / N)
print(dp[idx(count[1], count[2], count[3])])K - Stones
o 遷移先の中に手番が勝てる手があれば勝てるという、ゲームの木の考え方と同じ。 2023-04-27
L - Deque
o 区間DPでいけた。 2023-04-27
M - Candies
o 遷移元の区間和が必要で、累積和を使う。シンプル。 2023-04-27
M = 10**9 + 7
N, K = map(int, input().split())
dp = [0]*(K+1)
dp[0] = 1
for a in map(int, input().split()):
for i in range(1, K+1): # sum
dp[i] += dp[i-1]
dp[i] %= M
for i in range(K+1)[::-1]:
if i - a >= 1:
dp[i] -= dp[i-a-1]
print(dp[K] % M)N - Slimes
o 区間DPでいけた。 2023-04-27
O - Matching
o 計算量を見積もって、まあなんとかなるだろうと思ったけど、この方式だとTLEがなかなか解消できず、無理だった。この方式というのは、男性の方を、i人目まで確定したときの組み合わせ数を順番に調べていく方法。最後のあと1つだけTLEというところまでいったけど。 2023-04-27
from collections import defaultdict
M = 10**9 + 7
N = int(input())
alist = [[1 << i for i, a in enumerate(map(int, input().split())) if a == 1] \
for _ in range(N)]
dp = defaultdict(int)
for j in alist[0]:
dp[j] = 1
for i in range(1, N):
dp_new = defaultdict(int)
for bit, count in dp.items():
for j in alist[i]:
if j & bit == 0:
dp_new[j+bit] = (dp_new[j+bit] + count) % M
dp = dp_new
print(dp[2**N - 1])修正後。スタンダードなbitDPのループにしたら通った。Fあたりから、難易度増して(F、G、Jが解けなくて、前半からこの難易度が続くのかと思って)心折れかけてたけど、ここ何問かは調子良く半分まで来た。 2023-04-27
M = 10**9 + 7
N = int(input())
alist = [sum([1 << i for i, a in enumerate(map(int, input().split())) if a == 1]) \
for _ in range(N)]
dp = [0]*(2**N)
for bit in range(1, 2**N):
i = bin(bit).count('1')
if i == 1:
if alist[0] & bit:
dp[bit] = 1
else:
girls = alist[i-1] & bit
while girls:
smallest = girls&-girls
dp[bit] += dp[bit-smallest]
girls -= smallest
dp[bit] %= M
print(dp[2**N - 1])P - Independent Set
o N = 10^5、O(N)、木DP。この木DPは遷移がきれいに書けていい。 2023-05-05
Q - Flowers
o N = 2x10^5、O(N Log N)。log(200000) = 17.6。区間MAXを管理するフェニック木でDPを表現する。次の花の高さがhならすでに確定しているh-1までの最大のものから遷移するのがベストなので。 2023-05-05
R - Walk
o 頂点数N = 50、単純有向グラフ。ステップ数K = 10^18。O(N^3 log K)。50^3 = 125000、log(10^18) = 59.8。大体60。行列の掛け算を倍々で。普通に1歩ずつ進むDPで考えてたら10^18とか出てくるとビビる。 2023-05-05
M = 10**9 + 7
N, K = map(int, input().split())
def multiply_mm(a, b):
global N
res = [[0]*N for _ in range(N)]
for i in range(N):
for j in range(N):
for k in range(N):
res[i][j] += a[i][k] * b[k][j]
res[i][j] %= M
return res
def multiply_mv(a, v):
global N
res = [0]*N
for i in range(N):
for j in range(N):
res[i] += v[j] * a[j][i]
res[i] %= M
return res
alist = [list(map(int, input().split())) for _ in range(N)]
x = [alist]
go = 2
while go <= K:
prev = x[-1]
x.append(multiply_mm(prev, prev))
go *= 2
i = 0
ans = [1]*N
while K:
if K % 2 == 1:
ans = multiply_mv(x[i], ans)
K //= 2
i += 1
print(sum(ans) % M)S - Digit Sum
o K = 10^10000、つまり10000桁の桁DP。D = 100、Dで割り切れる数をカウントする問題。この問題は桁の数字を全部足すので、1桁上がるたびに10倍とかしなくていいタイプ。K以下、ってのがやらしいと感じるはず。上の桁から見ていって、Kに一致している場合は次の桁はK以下、そうでない場合は0-9全てに遷移する、という2パターンの遷移を管理すれば良い。O(桁数=10000 D=100 N=10)。Kかどうかなのでこの2倍でいけるけど、0-9までバラバラに処理しようとすると間に合わなくなりそうw 2023-05-05
T - Permutation
o N = 3000。O(N^2)。挿入DP。N^2 = 9000000。以前ABCで挿入DPに出会ったときに、この問題を勉強するように書いてあったので、1度ACしている。それでもまた難しかった。挿入した時点では、i-1とi番目の大小関係がわかるだけで、実際の数字はわからない。全部挿入し終わると、実際の数字が確定する。それがなかなか自然に受け止められない。でも頭ひねって思い出して、復習できてよかった。 2023-05-05
U - Grouping
o N = 16。計算量ちょっとややこしかった気がする。最初にグループの全パターンの得点を計算しておく。O(2^N N)か。2^16 = 65536。2^16 x 16 = 1048576。いい感じの大きさ。次に、bitDPしながら、その中で、全部分集合でループし、得点が最大になるものを見つける。部分集合の部分集合はO(3^N)らしい。典型90の045に出てきた。3^16 = 43046721。これがでかいので効いてるけどなんとかなりそうなサイズだ。3^16 -> 4000万。 2023-05-05
V - Subtree
x N = 10^5。答えは素数でないMで割る。全方位木DPというらしいが、下から上へ、その後上から下へとDPすればいけるなぁ、というところまでは、自力で導くことができた。しかし解けなかった。時間制限に引っかかってTLEx3が限界だった。計算量が大きすぎることは自分で気づいていた。Mが素数でないということが効いていて、N個の数字からN-1個選ぶN通りの掛け算の結果を求めたかったが、逆元が求められないので、抜く1つで割って計算できなかったのだ。なんと累積積という方法で、両側から計算しておくことで、1つ抜いて両側の積をかけてO(1)で求めるというテクニックを使っていた。累積積とは初めてで勉強になった。 2023-05-05
W - Intervals
x ★ N = 2x10^5、M = 2x10^5。O(M Log N)かなぁ。Log(200000) = 17.6。難しい問題だった。lかrでソートすんだろうなぁとは思ったものの、i番目まで確定したときの最後の1がj番目の時の最大スコアでDPする、ということまで導けなかった。確かにそれがi-1まで求まっていればiに遷移できるのだが。どう考えれば導けるのだろう?パラメーターiだけでは無理だなぁ、とまず思うだろう。もう1つは、最後の1の位置。。。排他的であることは重要で、最後の1の位置によって確実に排他的な状態をカウントできる。で、遷移できる方法を探って…みたいな感じかなぁ。わからんけど。遅延セグ木は1回だけ典型90の029で出会ったことがある。そのときに作ったものは強制的に区間に値をセットするだけだった。今回は区間に足したり引いたりするということで、修正が必要になったけど、バグりまくって手こずった。遅延セグ木2回目にて、修正を入れられて良かった。この問題は、遅延セグ木のクラスを除くとこんなにシンプルなコードになるのだ。2回見てもムズいなこれ、iがrに到達したときに初めてその区間を考慮するってのが。#遅延セグ木 #DP 2023-05-05
from collections import defaultdict
N, M = map(int, input().split())
alist = defaultdict(list)
for _ in range(M):
l, r, a = map(int, input().split())
alist[r].append((l, a))
dp = SEGT_LAZY(N+1)
for r in range(1, N+1):
dp.range_add(r, r+1, dp.query(0, r))
if r in alist:
for l, a in alist[r]:
dp.range_add(l, r+1, a)
print(dp.query(0, N+1))X - Tower
x N = 1000、w, s = 10000。w+sが小さい順に上から確定していくのが最適であることがわかり、ソートしてDPするとできる。のだが、その結論を自力で導くのはむちゃくちゃ難しい。Wの重さが確定していて、その下にブロックABの順、もしくはBAの順となる条件を式で書くと、s+wが小さい方が上になるということがわかる。ということは全部s+wが小さい順に考えればよいということになり、秩序だったDPが構築できる。激ムズ。どうすれば気づけるだろうか?なんらかの方法でソートしたいなぁと思い、ブロックAとBが並んでいる時どっちが上か考えてみる。という流れかな。式変形でs+wが小さい方が上でオッケーとなるまでもまあ難しいけど、そこはがんばるとしか言えないかなぁ。 2023-05-05
N = int(input())
blocks = [tuple(map(int, input().split())) for _ in range(N)]
blocks.sort(key=lambda x:x[0]+x[1])
dp = [0]*20001 # 0-20000
for w, s, v in blocks:
for i in range(1, s+1)[::-1]:
if dp[i] != 0:
dp[i+w] = max(dp[i+w], dp[i]+v)
dp[w] = max(dp[w], v)
print(max(dp))Y - Grid 2
x H, W = 10^5(グリッドのサイズ)、N = 3000(障害物の数)。O(N^2) = 9000000。2項係数の計算も必要で、O(H+W)。グリッドを、障害物を避けて端から端へ行く経路数というのはよく見るし、マスごとにカウントしていくのしか見たことない。この問題はマスが10^10もあって無理だ。主客転倒を行う。障害物を通る数を数えて引くのだ。障害物を通る数はどのように数えればよいのか?と考える。やはり排他的に数えることを考えると、i番目の障害物に初めてぶつかる数というのを考えると、それi-1番目までに最初にぶつかってi番目にもぶつかる経路数を引けば良いとわかる。よってすでに調べたものに対して計算を繰り返すのでO(N^2)になり、N = 3000なので、N^2 = 9000000だ。難しいの続くなぁ。 2023-05-05
Z - Frog 3
x N = 2x10^5。O(N)。FrogはこのEDPCに出てきたが、いける範囲が狭かった。この問題では、どこへでも一気にジャンプできるので、今までと同じようにやるとO(N^2)で、全然間に合わない。しかしひとまず遷移の式を書くと複数の1次関数のある値での最小値を求める必要があるとわかる。これはConvex Hull Trickというテクニックを使うとO(N)で計算できてしまう。1次関数を追加しながら、両側の要らなくなった(最小値を取り得なくなった)1次関数は削除していくが、追加したものを削除していくので、せいぜい2倍にしかならず、計算量はO(N)のままなのだ。Convex Hull Trickこと、CHTもABC289 Gで1度勉強したが、簡単に思い出せなかった。良い復習になって、今後使いこなせれば良いと思う。というわけで、EDPC、全部AC完了。典型90みたいに最後だけできないとかなくて良かったw 2023-05-05
ABC過去問
自力ACを目指そう。すなわち、すぐ解説を見ずに、今までよりねばる。
ABC301 E - Pac-Takahashi
o H = W = 300(よってマスは90000)。N = 18(お菓子の数)。O(2^N N^2)のはず。N = 18として2^N x N^2 = 84934656。制限時間が5秒とちょっと長めなのでいけそう。結果は1.5秒だった。思ったより速い。自分のマシンではかなり遅かったが、サーバー上のPyPy速い。最初順列全探索するのかと思ったが、18!は無理。11!で4000万くらいと覚えたばかり。もう1つ最初思ったのが、ダイクストラ?ってことだった。でも最短経路じゃなくて全部通る経路だからダメと気づく。書き始めるまで気づいてなかった。4方向に移動するのはコードコピペしたけど、HとWとかxとyとか修正し忘れてバグるので良くなさそう。オーバーヘッドあっても関数作ってループしたほうがミスらなくて良さそうだ。BFSはdequeのpopleftを使わなければならない。それも最初なぜかミスってた。普段ミスらんのになぁ。b 2023-06-01
INF = 10000000
H, W, T = map(int, input().split())
A = [list(input()) for _ in range(H)]
points = [(0,0)]
goal = (0,0)
for i in range(H):
for j in range(W):
if A[i][j] == 'S':
points[0] = (i,j)
elif A[i][j] == 'G':
goal = (i,j)
elif A[i][j] == 'o':
points.append((i,j))
points.append(goal)
p2i = {}
for i in range(len(points)):
p2i[points[i]] = i
N = len(points)
G = [[INF]*N for _ in range(N)]
for i in range(N):
G[i][i] = 0
from collections import deque
for v in range(N-1):
dists = [[INF]*W for _ in range(H)]
q = deque([])
q.append(points[v])
dists[points[v][0]][points[v][1]] = 0
while q:
x, y = q.popleft()
nd = dists[x][y] + 1
if x > 0:
nx = x-1
if A[nx][y] != '#' and nd < dists[nx][y]:
dists[nx][y] = nd
q.append((nx, y))
if A[nx][y] != '.':
u = p2i[(nx,y)]
if u > v:
G[v][u] = nd
G[u][v] = nd
if x < H-1:
nx = x+1
if A[nx][y] != '#' and nd < dists[nx][y]:
dists[nx][y] = nd
q.append((nx, y))
if A[nx][y] != '.':
u = p2i[(nx,y)]
if u > v:
G[v][u] = nd
G[u][v] = nd
if y > 0:
ny = y-1
if A[x][ny] != '#' and nd < dists[x][ny]:
dists[x][ny] = nd
q.append((x, ny))
if A[x][ny] != '.':
u = p2i[(x,ny)]
if u > v:
G[v][u] = nd
G[u][v] = nd
if y < W-1:
ny = y+1
if A[x][ny] != '#' and nd < dists[x][ny]:
dists[x][ny] = nd
q.append((x, ny))
if A[x][ny] != '.':
u = p2i[(x,ny)]
if u > v:
G[v][u] = nd
G[u][v] = nd
bit2i = {}
for i in range(N-2):
bit2i[1<<i] = i + 1
s = 0
g = N-1
if G[s][g] > T:
print(-1)
else:
ans = 0 # at least 0
dp = [[INF]*(1<<(N-2)) for _ in range(N-1)] # [last_v][S]
for bit in range(1, 1<<(N-2)):
count = f'{bit:b}'.count('1')
if count == 1:
v = bit2i[bit]
dp[v][bit] = G[s][v]
if dp[v][bit] + G[v][g] <= T:
ans = max(ans, count)
else:
bitcopy = bit
while bitcopy:
last = bitcopy&-bitcopy
v = bit2i[last]
other = bit - last
othercopy = other
while othercopy:
lastother = othercopy&-othercopy
u = bit2i[lastother]
dp[v][bit] = min(dp[v][bit], dp[u][other]+G[u][v])
othercopy -= lastother
bitcopy -= last
if dp[v][bit] + G[v][g] <= T:
ans = max(ans, count)
print(ans)ABC301 F - Anti-DDoS
o N = 300000。O(N)だよね。定数倍が重い。自力で解けた。それだけで十分。最後powを事前計算してTLEを解消して1.5秒。Pythonで回答してる人の中で遅めなのは気になる。僕の実装は重いけど、軽い人も多かった。一体どうやっているのだろう?左からDDになるパターンをカウント、右からoSになるものをカウント。oSのoの位置でDDとoSを掛け算して合計する方針。良い方法かはわからないけど、考えてるうちに計算量は減った。o 2023-06-14
M = 998244353
S = list(input())
N = len(S)
pow26 = [0]*(N+1)
pow26[0] = 1
for i in range(1, N+1):
pow26[i] = pow26[i-1] * 26 % M
pow52 = [0]*(N+1)
pow52[0] = 1
for i in range(1, N+1):
pow52[i] = pow52[i-1] * 52 % M
COUNT_MAX = max(26, N)
fact = [0]*(COUNT_MAX+1)
invfact = [0]*(COUNT_MAX+1)
fact[0] = 1
for i in range(1, COUNT_MAX+1):
fact[i] = fact[i-1] * i % M
invfact[COUNT_MAX] = pow(fact[COUNT_MAX], M-2, M)
for i in range(COUNT_MAX-1, 0, -1):
invfact[i] = invfact[i+1] * (i+1) % M
invfact[0] = 1
def choose(n, r):
return fact[n] * invfact[r] * invfact[n-r] % M
def perm(n, r):
return fact[n] * invfact[n-r] % M
used = [0]*26
canuse = [0]*N
cur = 26
ORDA = ord('A')
for i, c in enumerate(S):
if c.isupper():
used[ord(c)-ORDA] += 1
if used[ord(c)-ORDA] == 2:
canuse[i] = -1 # impossible to avoid DD
break
else: # first
cur -= 1
canuse[i] = cur
DDcount = [0]*N # DDが発生するパターン数
Qcount = 0 # 現在の?の数
cannotavoidDD = False
for i, c in enumerate(S):
if c == '?':
Qcount += 1
all_ = pow52[Qcount] # pow(52, Qcount, M)
if cannotavoidDD:
DDcount[i] = all_
continue
noDD = 0 # subtract from all_ afterward
umax = canuse[i]
if umax == -1:
cannotavoidDD = True
DDcount[i] = all_
continue
for upcount in range(min(Qcount+1, umax+1)):
noDD = (noDD + pow26[Qcount-upcount] * choose(Qcount, upcount) \
* fact[umax] * invfact[umax-upcount]) % M
DDcount[i] = (all_ - noDD) % M
Qall = Qcount
# 0 is before fixed upper
# 1 is after fixed upper
# 2 is lower again 2 is only 1 position next is 3
phase = 0
Qcount = 1 if S[N-1] == '?' else 0 # 現在の?の数
min_low = N
max_up = N-1
oScount = [0]*N
for i in range(N-1)[::-1]:
if S[i] == '?':
Qcount += 1
i2 = i + 2
if i2 < N:
if phase == 0 and S[i2].islower():
min_low = i2
elif phase == 0 and S[i2].isupper():
phase = 1
max_up = i2
elif phase == 1 and S[i2].islower():
phase = 2
elif phase == 2:
phase == 3
a, b = S[i], S[i+1]
if a.isupper() or b.islower():
pass # impossible oS place
else:
if phase == 0:
max_up = i + 1
if phase <= 1:
oScount[i] = (min_low - max_up) * pow26[Qcount] % M
else:
break
ans = 0
for i in range(1, N):
if oScount[i] > 0:
ans = (ans + DDcount[i-1] * oScount[i]) % M
print((pow52[Qall] - ans) % M)ABC301 G - Worst Picture
x 初めて銅Diff通した。むちゃくちゃ時間かかった。今まで書いたコードで一番長いかも。180行以上ある。難しいアルゴリズムはいらないけど、長いし複雑なので、流れを整理するのが大変だし、ミスでバグも入りやすい。1度入ったバグはなかなか取れない。コンテスト時間中に全部やり切るのは至難の業で、銅Diffというのも納得できる。面倒なだけでこんなの解いても得るものが少ないんじゃないかと思ったけど、学びはあった。まず、初めてnamedtupleを使ってみた。点や直線の要素にアクセスするときに、名前がついていたほうが読みやすくなる。というかこのプログラムで全部添字アクセスしてたら全く何やってるかわからない。namedtupleいいなぁと思って使っていたけど、最後TLEが10個くらい残って、それを解消できず、もしかしてnamedtupleか?と思ったらそのとおりだった。namedtupleはclassを作るようなもので、もはやtupleではなく、遅いようだ。盲点だった。盲点だったからこそこれも学びとなった。namedtupleは遅い。また、数値誤差を回避するために、有理数で計算する必要があった。そのためにFractionという有理数ライブラリを使用した。これをぼくは初めて知った。intと混ぜて使っても自然に使える。これを使用しないと、WAx3が取れなかった。勉強になった。あとは銅Diffのこれだけ面倒な問題をACまでこぎつけたという事実。大変さに対する耐性ってやらないとつかないし、大変さの上限を引き上げられたと思う。今後、大変だけどABC301 Gほどではないかなぁ?みたいに思える基準ができた。この問題で、いろいろ整理が必要だったのは、0割回避なんだよな。0割を回避するためにif分岐が大量に…。そして投影面上で直線が重なったときは別の方向に投影するけど、そのときにあり得るパターンは最初の投影面とは変わる。なかなかやっかいだ。bronze 2023-06-28
from collections import defaultdict
from fractions import Fraction
def para2(a, b):
'''assume a[0] != 0 and b.x != 0'''
return a[0] * b[1] == a[1] * b[0]
def scale2(a, s):
return (a[0] * s, a[1] * s)
def scale3(a, s):
return (a[0] * s, a[1] * s, a[2] * s)
def sum2(a, b):
return (a[0] + b[0], a[1] + b[1])
def sum3(a, b):
return (a[0] + b[0], a[1] + b[1], a[2] + b[2])
def sub2(a, b): # a - b
return (a[0] - b[0], a[1] - b[1])
def sub3(a, b): # a - b
return (a[0] - b[0], a[1] - b[1], a[2] - b[2])
def int2(a, b):
'''line 2d'''
if a[1] == b[1] == (0,0):
return None
if a[1] == (0,0) or b[1] == (0,0):
if b[1] == (0,0):
a, b = b, a
# a is dot, b is line here
if b[1][0] == 0:
if a[0][0] != b[0][0]:
return None
else:
return a[0]
# b[1][0] != 0
elif a[0][0] == b[0][0]:
if a[0][1] != b[0][1]:
return None
else:
return a[0]
else:
if para2(sub2(a[0], b[0]), b[1]):
return a[0]
else:
return None
# a, b are lines
if a[1][0] == b[1][0] == 0:
if a[0][0] != b[0][0]:
return None
else:
return 'other' # need to try xz projection
if a[1][0] == 0 or b[1][0] == 0:
if b[1][0] == 0:
a, b = b, a
# only a[1][0] == 0
return sum2(b[0], scale2(b[1], Fraction(a[0][0] - b[0][0], b[1][0])))
if para2(a[1], b[1]):
if a[0] == b[0] or para2(sub2(a[0], b[0]), b[1]):
return 'other'
else:
return None
# a, b are not parallel
if a[1][1] == 0 or b[1][1] == 0:
if b[1][1] == 0:
a, b = b, a
# a is vertical
if b[0][1] == a[0][1]:
return b[0]
else:
return sum2(b[0], scale2(b[1], Fraction(a[0][1] - b[0][1], b[1][1])))
return sum2(a[0], scale2(a[1], Fraction(b[1][1] * (b[0][0] - a[0][0]) - b[1][0] * (b[0][1] - a[0][1]), a[1][0] * b[1][1] - a[1][1] * b[1][0])))
def int2_(a, b):
'''line 2d'''
if para2(a[1], b[1]):
return None
else:
return sum2(a[0], scale2(a[1], Fraction(b[1][1] * (b[0][0] - a[0][0]) - b[1][0] * (b[0][1] - a[0][1]), a[1][0] * b[1][1] - a[1][1] * b[1][0])))
def int3(a, b):
'''line 3d'''
yz = int2((a[0][1:], a[1][1:]), (b[0][1:], b[1][1:]))
if type(yz) is tuple:
if a[1][1:] == (0,0) or b[1][1:] == (0,0):
l3 = a
if a[1][1:] == (0,0):
l3 = b
s = Fraction(yz[0] - l3[0][1], l3[1][1]) if l3[1][1] != 0 else Fraction(yz[1] - l3[0][2], l3[1][2])
return sum3(l3[0], scale3(l3[1], s))
# a, b are lines
sa = Fraction(yz[0] - a[0][1], a[1][1]) if a[1][1] != 0 else Fraction(yz[1] - a[0][2], a[1][2])
sb = Fraction(yz[0] - b[0][1], b[1][1]) if b[1][1] != 0 else Fraction(yz[1] - b[0][2], b[1][2])
ax = a[0][0] + a[1][0] * sa
bx = b[0][0] + b[1][0] * sb
if ax == bx and ax < 0:
return (ax, yz[0], yz[1])
else:
return None
elif yz == 'other':
if a[1][2] != 0:
xz = int2_(((a[0][0], a[0][2]), (a[1][0], a[1][2])), ((b[0][0], b[0][2]), (b[1][0], b[1][2])))
if type(xz) is tuple and xz[0] < 0:
sa = Fraction(xz[0] - a[0][0], a[1][0])
ay = a[0][1] + a[1][1] * sa
sb = Fraction(xz[0] - b[0][0], b[1][0])
by = b[0][1] + b[1][1] * sb
if ay == by:
return (xz[0], ay, xz[1])
else:
return None
else:
xy = int2_(((a[0][:2]), (a[1][:2])), ((b[0][:2]), (b[1][:2])))
if type(xy) is tuple and xy[0] < 0:
sa = Fraction(xy[0] - a[0][0], a[1][0])
az = a[0][2] + a[1][2] * sa
sb = Fraction(xy[0] - b[0][0], b[1][0])
bz = b[0][2] + b[1][2] * sb
if az == bz:
return (xy[0], xy[1], az)
else:
return None
else:
return None
else: # yz is None
return None
def check_online(a, b, c):
'''a,b,c are point 3d, assume a[0] != b[0]'''
if a[1:] == b[1:]:
if a[1:] == c[1:]:
return True
else:
return False
elif a[1] == b[1]: # a[2] != b[2]
if a[1] != c[1]:
return False
# a[1] == b[1] == c[1]
elif (c[0]-a[0])*(b[2]-a[2]) == (b[0]-a[0])*(c[2]-a[2]):
return True
else:
return False
elif a[2] == b[2]: # a[1] != b[1]
if a[2] != c[2]:
return False
# a[2] == b[2] == c[2]
elif (c[0]-a[0])*(b[1]-a[1]) == (b[0]-a[0])*(c[1]-a[1]):
return True
else:
return False
else:
if (c[0]-a[0])*(b[2]-a[2]) == (b[0]-a[0])*(c[2]-a[2]) \
and (c[0]-a[0])*(b[1]-a[1]) == (b[0]-a[0])*(c[1]-a[1]):
return True
else:
return False
N = int(input())
XYZ = [tuple(map(int, input().split())) for _ in range(N)]
linefound = [[False]*N for _ in range(N)]
lines = defaultdict(list) # line 3d -> [pid,,,]
for i in range(N-1):
for j in range(i+1, N):
if XYZ[i][0] == XYZ[j][0] or linefound[i][j]:
continue
l3 = (XYZ[i], sub3(XYZ[j], XYZ[i]))
lines[l3].extend([i, j])
for k in range(j+1, N):
if XYZ[i][0] != XYZ[k][0] and XYZ[j][0] != XYZ[k][0] and check_online(XYZ[i], XYZ[j], XYZ[k]):
# k is on l3
for x in lines[l3]:
linefound[x][k] = True
lines[l3].append(k)
lineslist = list(lines.items()) # [(line 3d, [pid, pid, ...]), (..]
linecount = len(lineslist)
p2rem = defaultdict(set)
for i in range(linecount-1):
for j in range(i+1, linecount):
p = int3(lineslist[i][0], lineslist[j][0])
if p is not None and p[0] < 0:
p2rem[p].add(i)
p2rem[p].add(j)
remmax = 0
for p in p2rem:
lset = p2rem[p]
cur = 0
for i in lset:
cur += len(lineslist[i][1]) - 1
remmax = max(remmax, cur)
for l3 in lines:
remmax = max(remmax, len(lines[l3]) - 1)
print(N-remmax)ABC299 F - Square Subsequence
x N = 100。O(26 N^3)。N=100なので、十分速い。しかし難しいなこれ。攻め方の見当つかない。コンテスト不参加だったけど、あとで解こうとして諦めたっぽいけど、再チャレンジしてまあ普通にAC。ポイントは数え上げの基本で、重複して数えないためにはどうするか?DPもムズいが、ともかく重複しない数え上げ方法のロジックを固めないと前に進めない。やり方はTを確定したら、先頭から順番に見つかった文字を使うようにして文字を選ぶ。最初に見つかった文字を使って作れない部分文字列は、どうやっても作れないからこれでいい。DPするときに2つ目のTの最初の文字の位置でループする。これがN通り。中のDPがN^2だから合わせて計算量はN^3になるけどN=100なので大丈夫。DP[i][j]は1つ目のTの最後がi文字目、2つ目がj文字目の数とする。DP[i][j]を結果として採用するかどうかは、2つ目のTの1文字目がi文字目との間に存在しないこと。先程の重複して数えない方法を満たすためだ。こうやって求まる。y 2023-06-13
import bisect
M = 998244353
S = [ord(c)-ord('a') for c in input()]
N = len(S)
inds = [[] for _ in range(26)]
for i, c in enumerate(S):
inds[c].append(i)
cs = [] # can select
for c in range(26):
if len(inds[c]) >= 2:
cs.append(c)
ans = 0
for x in range(1, N):
c = S[x]
if len(inds[c]) < 2 or x == inds[c][0]:
continue
dp = [[0]*N for _ in range(N)]
dp[inds[c][0]][x] = 1
for i in range(N-1):
for j in range(i+1, N):
if dp[i][j] == 0:
continue
for nc in cs:
nci = bisect.bisect_right(inds[nc], i)
if nci >= len(inds[nc])-1 or x <= inds[nc][nci]:
continue
ncj = bisect.bisect_right(inds[nc], j)
if ncj == len(inds[nc]):
continue
dp[inds[nc][nci]][inds[nc][ncj]] = \
(dp[inds[nc][nci]][inds[nc][ncj]] + dp[i][j]) % M
for i in range(N-1):
for j in range(i+1, N):
if dp[i][j] > 0:
nci = bisect.bisect_right(inds[c], i)
if inds[c][nci] == x:
ans = (ans + dp[i][j]) % M
print(ans)ABC299 G - Minimum Permutation
x N = 200000。O(N Log N)たぶん。難しい。M個の数字の一番右の数字に印をつけておく。その右端の数字より右側まで進んでいるのに、まだその数字の位置を確定していないというのは不正なので、確定するまで超えることはできない。確定したら次に進める。最近入水目指して水と青ばっかり集中してやってたので、久しぶりの黃Diffで難しいと感じてしまった。やっぱ難しいんだなぁ。解けたって思っても細かいところ詰めきれてなくて、実は穴があってダメな感じ。いろいろな情報を管理しなければならないのも難しいし、この最小値を取り出す処理をプライオリティキューで実装するのがまたトリッキー。セグ木でやりたいところだけど、位置情報付きセグ木オイラーツアーのLCAでしか使ったことないし苦手意識。プライオリティキューでサッといけるとよい。y 2023-006-12
N, M = map(int, input().split())
A = list(map(int, input().split()))
ids = [[] for _ in range(M+1)]
for i in range(N):
ids[A[i]].append(i)
last = [0]*N
for i in range(1, M+1):
last[ids[i][-1]] = 1
import heapq
pq = []
added = 0
for i in range(N):
heapq.heappush(pq, (A[i], i))
if last[i] == 1:
added = i
break
ans = []
fix = [False]*(M+1)
prev = -1
while pq:
a, i = heapq.heappop(pq)
while i <= prev or fix[a]:
a, i = heapq.heappop(pq)
prev = i
ans.append(a)
if len(ans) == M:
break
fix[a] = True
last[ids[a][-1]] = 0
if last[added] == 0:
for i in range(added, N):
if not fix[A[i]]:
heapq.heappush(pq, (A[i], i))
if last[i] == 1:
added = i
break
print(*ans)最初、いけた!と思ったらACx24、WAx23だったやつ。ダメと気づくのがむずかしい。
N, M = map(int, input().split())
A = list(map(int, input().split()))
temp = []
ids = [-1]*(M+1)
for i in range(N):
if ids[A[i]] == -1:
temp.append(A[i])
ids[A[i]] = len(temp) - 1
else: # already in temp
prev = ids[A[i]]
np = prev + 1
while np < len(temp) and ids[temp[np]] != np:
np += 1
if np < len(temp) and temp[np] < A[i]:
temp.append(A[i])
ids[A[i]] = len(temp) - 1
fixed = [False]*(M+1)
ans = []
for a in temp[::-1]:
if not fixed[a]:
fixed[a] = True
ans.append(a)
print(*reversed(ans))ABC298 G - Strawberry War
x ムズいDP。5次元???H = W = 6。なので、ケーキ上のイチゴのありうる数が(7C2)^2で400くらいしかない。最小個数、最大個数が取りうる値もこれに含まれる。重要な考察!ていうか枝刈りしないとTLE解消できなかったし、それでもぼくのは遅めで大変だったの思い出した。2か月前に解いたのを思い出して書いてるので。いやすごいなこれは。最小xとしてp個にカットした場合に最大yをどれだけ抑えられるか?をケーキが小さい順にDPで調べていく。全体である[0][H][0][W]まで来たらカット数[T+1]を確認。xとの差を候補として記録する。p個にカットした場合、ってのが5次元目のパラメーターになってるのがエグい。ウケるわ。確かにどこかでカットした場合、左と右とか上と下とかそれぞれのカット数の和になるので、遷移式を作ることができる。自分で思いつきて~! orange 2023-04-17
H, W, T = map(int, input().split())
slist = [list(map(int, input().split())) for _ in range(H)]
ssum = [[0]*(W+1) for _ in range(H+1)]
for i in range(1, H+1):
for j in range(1, W+1):
ssum[i][j] = ssum[i][j-1] + slist[i-1][j-1]
for j in range(1, W+1):
for i in range(2, H+1):
ssum[i][j] += ssum[i-1][j]
rectsum = {}
for u in range(H):
for d in range(u+1, H+1):
for l in range(W):
for r in range(l+1, W+1):
rectsum[(u, d, l, r)] = ssum[d][r] - ssum[d][l] - ssum[u][r] + ssum[u][l]
xs = sorted(set(rectsum.values()))
INF = 10**18
ans = INF
for x in xs:
if x * (T+1) > ssum[H][W]:
break
# [u][d][l][r][pcount]
dp = [[[[[INF]*(T+2) for _ in range(W+1)] for _ in range(W+1)] for _ in range(H+1)] for _ in range(H+1)]
for h in range(1, H+1):
for w in range(1, W+1):
for u in range(H-h+1):
d = u + h
for l in range(W-w+1):
r = l + w
thisrect = rectsum[(u, d, l, r)]
if thisrect >= x:
dp[u][d][l][r][1] = thisrect
if thisrect >= 2*x:
for pcount in range(2, T+2):
for first in range(1, pcount):
second = pcount - first
for m in range(u+1, u+h):
cur = max(dp[u][m][l][r][first], dp[m][d][l][r][second])
if cur != INF:
dp[u][d][l][r][pcount] = min(dp[u][d][l][r][pcount], cur)
for m in range(l+1, l+w):
cur = max(dp[u][d][l][m][first], dp[u][d][m][r][second])
if cur != INF:
dp[u][d][l][r][pcount] = min(dp[u][d][l][r][pcount], cur)
if INF > dp[0][H][0][W][T+1] >= x:
ans = min(ans, dp[0][H][0][W][T+1] - x)
print(ans)ABC265 E - Warp
x N = 300(移動回数)、M = 10^5。O(N^3 Log M)?3通りの遷移を300回ということで、3^300あるんじゃないかと思い、どう減らすの?と考えていると、よく考えたらありえる座標がかなり少ないと気づいた。移動Pと移動Qがあって、PQとQPの行き先が同じなので、ほとんどかぶっているはずと。具体的には300回の移動を3通りの遷移に振り分けるパターン数なので、299C2であることがわかる。299C2 = 44551で、行き先の座標はかなり少ない。そこから3通りの遷移なら合計12万回にしかならないはず。と、dictで実装したらTLEx17。半分以上TLEという有様。謎である。Pythonのdictよほど遅いんだろうか?コンテスト当時も時間制限が厳しいという議論がTwitterでなされていたらしいが、PythonでACしてる実装を見てかなり勉強になった。3通りの移動をi,j,k回やった場合のパターン数でDPすればよい。3次元のはずだが、記憶は2次元で済んでいる。移動先に移動元の数を足すだけなので、i->i+1の遷移は基本何もしなくていい。ただし、その座標が壁だった場合は0をセットする必要がある。かなり賢い実装だと思う。過去問早速解けず幸先が悪くて落ち込んだが、まだまだ知らないことが多いなぁと勉強になった。ていうかこれ速い!lb 2023-05-06
import sys
input = sys.stdin.readline
mod = 998244353
N, M = map(int, input().split())
a, b, c, d, e, f = map(int, input().split())
wset = set(tuple(map(int, input().split())) for _ in range(M))
dp = [[0]*(N+1) for _ in range(N+1)]
dp[0][0] = 1 # [j][k]
ans = 0
for i in range(N+1):
for j in range(N-i+1):
for k in range(N-i-j+1):
x = a*i + c*j + e*k
y = b*i + d*j + f*k
if (x, y) in wset:
dp[j][k] = 0
continue
if j > 0:
dp[j][k] += dp[j-1][k]
if k > 0:
dp[j][k] += dp[j][k-1]
dp[j][k] %= mod
if i+j+k == N:
ans += dp[j][k]
ans %= mod
print(ans)ABC264 E - Blackout 2
o クエリ先読みと逆再生、ひらめいた!N+M = 2x10^5(Union-Findのノード数)、Q = 5x10^5。O(E)ではないだろうか?逆再生して電線を全部つなぐので。いやーねばるぞと決めたので、思いついた。クエリを前から処理すると全くどうやればいいのか見当がつかないけど、電線を全部切った状態から逆につないでいくなら、Union-Findでできるとひらめいた。うれしい。Union-Findのグループ内のノード数を扱ったことはなかったけど、つなぐときにLeaderに合計を持たせれば良いな。これも初めての経験だったので良かった。最初、元々つながっているときはつなぐ必要なし、というのを気づかずバグっていたので、これもよい勉強になった。lb 2023-05-07
ABC264 F - Monochromatic Path
o H = W = 2000(グリッドサイズ)。O(HW)。マスを順にDP。青DIffということだが、閃いた!なんかできそうでできねーっていう時間が続いたが、ふと、いけるじゃんという境界線をまたぐ瞬間がくる不思議。この感覚を楽しんでいきたい。さすがに結構ややこしい。(i,j)まで確定したときのコストの最小値でDPだよなーとまず思うけど、なんか整理できない。下に遷移する時はその列(つまりj列目)を反転させるかどうかはすでに確定してしまっている。よって、(i,j)と(i+1,j)を一致させるにはi+1行目を反転させて色を揃える必要がある。逆に右に遷移するときは反転できるのはj+1列目。ということで、マスが反転していない、行反転してる、列反転してる、行列両方反転してる、という4つの状態を持ち、その状態が整合性を取れるように下と右に遷移していくように実装する必要がある。できてよかった。解けたのはいいけど、実装大変目なのは間違いない。コンテスト中だとイライラして間に合わないかも。b 2023-05-07
INF = 10**15
H, W = map(int, input().split())
rlist = list(map(int, input().split())) # row 行
clist = list(map(int, input().split())) # clumn 列
alist = [list(map(int, list(input()))) for _ in range(H)]
dp = [[[INF]*W for _ in range(H)] for _ in range(4)]
# 00 : no flip, 01=1 : column flip, 10=2 : row flip, 11=3 : both flip
dp[0][0][0] = 0
dp[1][0][0] = clist[0]
dp[2][0][0] = rlist[0]
dp[3][0][0] = clist[0] + rlist[0]
for i in range(H):
ni = i+1
for j in range(W):
nj = j+1
if i < H-1:
same = (alist[ni][j] == alist[i][j])
dp[0][ni][j] = dp[0][i][j] if same else dp[2][i][j]
dp[1][ni][j] = dp[1][i][j] if same else dp[3][i][j] # already flipped
dp[2][ni][j] = (dp[2][i][j] if same else dp[0][i][j]) + rlist[ni]
dp[3][ni][j] = (dp[3][i][j] if same else dp[1][i][j]) + rlist[ni]
if j < W-1:
same = (alist[i][nj] == alist[i][j])
dp[0][i][nj] = min(dp[0][i][nj], dp[0][i][j] if same else dp[1][i][j])
dp[1][i][nj] = min(dp[1][i][nj], (dp[1][i][j] if same else dp[0][i][j]) + clist[nj])
dp[2][i][nj] = min(dp[2][i][nj], dp[2][i][j] if same else dp[3][i][j])
dp[3][i][nj] = min(dp[3][i][nj], (dp[3][i][j] if same else dp[2][i][j]) + clist[nj])
ans = INF
for i in range(4):
ans = min(ans, dp[i][H-1][W-1])
print(ans)ABC263 E - Sugoroku 3
o N = 2x10^5。すごろくのマスの数。O(N)。できたー。EDPC J Sushiの期待値の遷移方法を覚えていられれば解ける。マスiからN-1(0-indexedとしたので、ゴールはN-1)までの期待値でDPする。DP[N-1] = 0で、遡っていく式を導くことができる。DP[i] = 1 + DP[i]/(Ai+1) + DP[i+1]/(Ai+1) + … + DP[i+Ai]/(Ai+1)。これ、2回やって身についたかなという感覚。身についていたらうれしい。遷移先がNのオーダーなので、そのままやるとO(N^2)になるが、累積和を使ってO(N)で解ける。コード短い。よしッ!Diffを見ると、ABC264 Fの方が難しいのか。まあ面倒ではあったけど、これ難しいと思うんだよなぁ。みんな期待値の典型として学習済みということか。b 2023-05-07
M = 998244353
N = int(input())
A = list(map(int, input().split()))
dp = [0]*N # dp[N-1] = 0
dpsum = [0]*N
for i in range(N-1)[::-1]:
invA = pow(A[i], M-2, M)
dp[i] = (A[i] + 1 + dpsum[i+1] - (0 if i+A[i] == N-1 else dpsum[i+A[i]+1])) * invA % M
dpsum[i] = (dp[i] + dpsum[i+1]) % M
print(dp[0])ABC262 D - I Hate Non-integer Number
o N = 100。O(N^4)???そのまま計算すると制限時間に間に合わなそうだけど、実際にはだいぶ少ないということだけはわかる。実際の、計算量は、NxΣ(1-N)n^3なので、小さいだろうと。Nはたった100だし。選択する数字の数をパラメーターとしてDPするけど、小さい順に遷移させると、不正な結果になって最初バグった。そんなミスは最初からしたくない。i個使う状態からi+1個使う状態を計算し、i+1個使う状態からi+2個使う状態を計算すると、先に更新した結果が後で更新するときに含まれてしまう。逆順にすればOK。lb 2023-05-07
M = 998244353
N = int(input())
alist = list(map(int, input().split()))
ans = N # select 1
for n in range(2, N+1): # select n nums
xlist = [a%n for a in alist]
dp = [[0]*n for _ in range(n+1)] # [used count][amari]
dp[0][0] = 1
dp[1][xlist[0]] = 1
for i in range(1, N):
for used in range(n)[::-1]:
for amari in range(n):
if dp[used][amari] != 0:
dp[used+1][(amari+xlist[i])%n] += dp[used][amari]
dp[used+1][(amari+xlist[i])%n] %= M
ans += dp[n][0]
ans %= M
print(ans)ABC262 E - Red and Blue Graph
x N = K = 2x10^5(頂点、赤い頂点)、M = 2x10^5(辺)。O(N)のはず。閃かず。これ、グラフの数学的性質を使わないと解けない。赤と青の間の辺の数を偶数にする。には、赤のK個の頂点の次数の合計が偶数であれば良い。なぜなら赤同士の間の辺は2回カウントされるので2の倍数になり、残った青と接続している辺の数を偶数にしようと思ったら、次数の合計を偶数にする必要があるとわかるから。悔しいが覚えなければ仕方ない。辺の数の偶奇性などが問題になる場合、次数に着目するとうまくいくことがあるのだろう。ここまでわかってしまえば、あとは組み合わせの数を簡単に求めることができる。K個選ぶって言われるとDPを思い浮かべるけど、DPでやろうとすると、O(NK)が頭に浮かんで、無理ってなるよね。だから違うんだなー、と方針変えないといけない。b 2023-05-07
ABC261 E - Many Operations
o N = 2x10^5。C = 2^30-1(2進数で30桁ということ)。O(N Log C)。Log C = 30。bitごとに処理して解いた。制限時間2秒のところ、1.5秒近くかかったので遅め。f'{C:030b}'で2進表記にし、処理後の10進表記はint(''.join(map(str, cur)), 2)で求めた。これが遅いかもしれんけど、まあいいか。ANDで0なら0、ORで1なら1、XORで1なら反転、で、それ意外のbitは何もしないという性質を考え、AND0、OR1で強制的にセットするbitを記録、強制的にセットしてからのXOR1で反転の回数を記録し、処理のたびに出力すればOK。lb 2023-05-09
N, C = map(int, input().split())
cur = list(map(int, list(f'{C:030b}')))
fix = [None]*30
xor = [0]*30
for _ in range(N):
T, A = map(int, input().split())
if T == 1:
act = list(map(int, list(f'{A:030b}')))
for i, a in enumerate(act):
if a == 0:
fix[i] = 0
xor[i] = 0
elif T == 2:
act = list(map(int, list(f'{A:030b}')))
for i, a in enumerate(act):
if a == 1:
fix[i] = 1
xor[i] = 0
else: # T == 3
act = list(map(int, list(f'{A:030b}')))
for i, a in enumerate(act):
if a == 1:
xor[i] ^= 1
for i in range(30):
if fix[i] is not None:
cur[i] = fix[i]
cur[i] ^= xor[i]
print(int(''.join(map(str, cur)), 2))ABC261 F - Sorting Color Balls
x N = 3x10^5。O(N Log N)。残念ながらひらめかず。これもDPでしょって思ったらDPでは無理で行き詰まった。それはよくあるパターン。バブルソートの交換回数 = 転倒数、っていうよくあるやつにボールの色が同じなら交換コスト0にします!とアレンジが入るだけで解けない。不甲斐ない。でもまあ、全体の転倒数から各色の転倒数を引く(コスト0なので)だけで良いという。まあできるかもなぁ、とも思う。全色サイズNのフェニック木で転倒数数えるわけにいかず、座圧も必要。座圧くらいで面倒とか思わないようにしたい。大したことないのだから。lb 2023-05-09
ABC260 E - At Least One
o N = M = 2x10^5。O(N+M)だろう。最初、Sが連続部分列というのを読み間違えて、部分列だと思っていた。その場合、点被覆パターン数え上げ問題となるけど、わからなかった。そのまま1日考えてしまった。連続ならいけると思った。しゃくとり法は自然だろう。特定の区間に全部1加えるという処理が必要になる。遅延セグ木?と思ったけど、最後に1回だけ計算すればよいので、いもす法なのだった。いもす法すごい。b 2023-05-10
N, M = map(int, input().split())
from collections import defaultdict
a2b = defaultdict(list)
amax = 1
bmin = M
for _ in range(N):
a, b = map(int, input().split())
amax = max(a, amax)
bmin = min(b, bmin)
a2b[a].append(b)
for a in a2b:
a2b[a].sort()
imos = [0]*M
l = 1
r = amax
imos[r-l] += 1
for l in range(2, bmin+1):
if l-1 in a2b:
bneed = a2b[l-1][-1] # a removed
if bneed > r:
r = bneed
imos[r-l] += 1
imos[M+1-l] -= 1
ans = [imos[0]]
for i in range(1, M):
ans.append(ans[-1] + imos[i])
print(*ans)ABC260 F - Find 4-cycle
o S = 3x10^5、T = 3000。SとTは2部グラフのそれぞれの独立集合。M = 3x10^5(辺の数)。O(M)かな?青Diffで結構上。問題は見慣れない感じだけど、自然にひらめくことができてうれしい!M = 3x10^5っていうのが、小さいし、M個の辺を調べれば解けるので、計算量は少なくて済む、ということに気づけばOK。T→S→Tと進んで、同じ頂点に到達すれば4-cycleができるので。ヨシッ。青2連発。b 2023-05-11
S, T, M = map(int, input().split())
G = [[] for _ in range(S+T)]
for _ in range(M):
u, v = map(int, input().split())
u -= 1
v -= 1
G[u].append(v)
G[v].append(u)
import sys
for v in range(S, S+T):
reach = {}
for n in G[v]:
for nn in G[n]:
if nn != v:
if nn in reach:
print(v+1, n+1, nn+1, reach[nn]+1)
sys.exit()
reach[nn] = n
print(-1)ABC259 E - LCM on Whiteboard
o N = 2x10^5(整数の数)、Σm = 2x10^5(素数の数)。O(Σm Log Σm)かな?N個の整数のうち、どれかの素数を一番多く含む数を1に変更すると、最小公倍数は変化するので、一番多く含む数の個数を数える。N個全部の場合は当然N個だが、N個より小さい場合は、残りは最小公倍数が変化しない数なので、それらの数を1に変更しても、すべての数の最小公倍数と同じままとなる。よって1足す。ヨシッ、自力AC続いてるぞ。自信つけ!lb 2023-05-11
N = int(input())
md = {} # p -> [e, [i,,,]]
for i in range(N):
m = int(input())
for _ in range(m):
p, e = map(int, input().split())
if p in md:
if e > md[p][0]:
md[p] = [e, [i]]
elif e == md[p][0]:
md[p][1].append(i)
else:
md[p] = [e, [i]]
ansset = set()
for p in md:
if len(md[p][1]) == 1:
ansset.add(md[p][1][0])
change = len(ansset)
if change < N:
change += 1
print(change)ABC259 F - Select Edges
o N = 3x10^5。O(N)かな?これも青Diffとなっているけど、順調に自力AC続いてる。ちょっと詰められてないような不安残し木DP書いたが、1発でACできた。速度も速い。不安ってのはreduce.pop()で例外発生するかもってことだけど、子供のエッジを選択数0になるまでしか減らさないので、当然reduceが空になってさらにpop()することは無いので大丈夫そうだ。木DPって初めてみた時、まだ新しいこんなDPでてくんのかよと疲れた記憶が新しいけど、典型90やEDPCにも確か入ってたし、もう5回目くらいかも。慣れて当然のようにできるようになるのであれば、うれしいことだ。解説と同じかわからないけど、エッジを選択する場合、しない場合の最大総和を、末端から根に向かってDPしていった。b 2023-05-12
N = int(input())
dlist = list(map(int, input().split()))
G = [[] for _ in range(N)]
dps = [0]*N # select edge id is the id of child vertex
dpd = [0]*N # deselect edge id is the id of child vertex
for _ in range(N-1):
u, v, w = map(int, input().split())
u -= 1
v -= 1
G[u].append((v, w))
G[v].append((u, w))
parent = [-2]*N
parent[0] = -1
stack = [~0, 0]
dps[0] = None
while stack:
cur = stack.pop()
if cur >= 0:
for nex, w in G[cur]:
if parent[nex] == -2:
parent[nex] = cur
stack.extend([~nex, nex])
if dlist[nex] > 0:
dps[nex] = w
else:
dps[nex] = None
else:
cur = ~cur
dnum = dlist[cur] # possible selection
reduce = []
select = 0
maximum = 0
for nex, w in G[cur]:
if nex == parent[cur]:
continue
if dps[nex] is None:
maximum += dpd[nex]
elif dps[nex] > dpd[nex]:
maximum += dps[nex]
select += 1
reduce.append(dps[nex] - dpd[nex])
else: # dps[nex] <= dpd[nex]
maximum += dpd[nex]
reduce.sort(reverse=True)
while select > dnum:
sub = reduce.pop()
maximum -= sub
select -= 1
dpd[cur] = maximum
if dps[cur] is not None:
while select > dnum - 1:
sub = reduce.pop()
maximum -= sub
select -= 1
dps[cur] += maximum
print(dpd[0])ABC258 E - Packing Potatoes
o N = Q = 2x10^5。O(N+Q)のはず。合計Xとかしゃくとりがよい。最後のクエリ処理のところ、K-=1を忘れてバグっていた。なかなか大変だ。先週旅行中でABC、ARC不参加で、その後断酒と早寝を決めて継続したところ、今まで夜やっていた競プロの勉強ができず、ボケボケだ。そのためこの問題もむっちゃ時間かかってしまった。今からABCで事前に解けるか微妙な感じで、ギリギリACできてよかった。明らかに調子悪いけど今日の久しぶりのABCをスキップするわけにはいかない。ていうかこの問題難しいのかなぁ。感覚がわからん。lb 2023-05-30
N, Q, X = map(int, input().split())
W = list(map(int, input().split()))
W2 = W[:] + W[:]
Wsum = sum(W)
amari = X % Wsum # need amari
least = N * (X // Wsum)
nex = [0]*N
jnum = [0]*N
j = 1
cur = W[0]
for i in range(N):
while cur < amari:
cur += W2[j]
j += 1
nex[i] = j % N
jnum[i] = least + j - i
cur -= W[i]
i = 0
a = b = 0
loop = [i]
passed = [-1]*N
passed[i] = 0
while True:
j = nex[i]
if passed[j] != -1:
a = passed[j]
b = passed[i] + 1
break
passed[j] = passed[i] + 1
loop.append(j)
i = j
looplen = b - a
for _ in range(Q):
K = int(input())
K -= 1
if K < a:
print(jnum[loop[K]])
else:
print(jnum[loop[a + (K-a) % looplen]])ABC258 G - Triangle
x N = 3000(頂点数)。O(N^3) = 270億?なんで間に合うんだよ!自分でこうやるのかなぁと思ってはいた。まあandを取ってpopcountするところが速くなるかなぁと思ってはいた。しかし絶対O(N^3)無理だろと思って解説を見たら、いけるらしい!なんで?今回はbitsetでC++で解いた。解説にはpythonで通す方法もていねいに書かれており、ありがたい。Pythonでもやっておかないとなぁ。b 2023-05-25
#include <iostream> // cout, endl, cin
#include <vector> // vector
#include <bitset> // bitset
using namespace std;
int main()
{
int N;
cin >> N;
vector<bitset<3000>> bits(3000);
for (int i = 0; i < N; i++) {
string S;
cin >> S;
for (int j = 0; j < N; j ++) {
if (S[j] == '1') {
bits.at(i).set(j);
}
}
}
long long ans = 0;
for (int i = 0; i < N; i++) {
for (int j = i + 1; j < N; j++) {
if (bits.at(i).test(j)) {
ans += (bits[i] & bits[j]).count();
}
}
}
cout << ans / 3 << endl;
return 0;
}ABC257 D - Jumping Takahashi 2
x N = 200(完全グラフ頂点数)。maxdist = 4x10^9(2分探索の範囲)。計算量O(N^3 Log(maxdist))。あれ?8000000 x 30 = 2.4億?これ間に合うのかよ。1.2秒くらいだったけど。ちゃんと取り組めなかったけどやられた。全頂点に到達できるか調べる計算量がDFSでもBFSでもいいけどO(N^2)。なぜなら完全グラフのエッジ数がN^2なので、O(N^2+N) = O(N^2)。で、全頂点から調べるのでO(N^3)。2分探索の範囲は10^9とかなのででかい。結構危なそうな感じだが、間に合う。ていうかこのNがそこそこ小さくて、2分探索の中で全探索するパターン、典型90で自力ACしたのにすぐ思いつけないとは不覚だわ。lb 2023-05-27
N = int(input())
points = [tuple(map(int, input().split())) for _ in range(N)]
dists = [[0]*N for _ in range(N)]
maxdist = 0
for i in range(N):
x, y, p = points[i]
for j in range(N):
if i != j:
xj, yj, pj = points[j]
dists[i][j] = (abs(xj-x)+abs(yj-y)) / p
maxdist = max(dists[i][j], maxdist)
l = 0
r = int(maxdist + 1)
while l + 1 < r:
m = (l+r) // 2
for u in range(N):
stack = [u]
used = [False]*N
used[u] = True
while stack:
cur = stack.pop()
for nex in range(N):
if not used[nex] and dists[cur][nex] <= m:
stack.append(nex)
used[nex] = True
for v in range(N):
if not used[v]:
break
else: # found route
r = m
break
else: # not found
l = m
print(r)ABC257 E - Addition and Multiplication 2
o N = 10^9。O(N)。出力のコストのみ。これはいけた。ただ実装は面倒でちょっと時間かかった。変数名でごちゃごちゃしてしまうパターン。桁は多ければ多いほどよいので、まず最小コストで何桁作れるか?確定してしまう。その後、上位桁は大きい程よいので、数字がでかい順に置き換えられる限り置き換えていく。この時、最小コストに対応する数字より他の数字が小さい場合もあって、置き換えることでより小さくなってしまい、最初バグってしまった。注意力なので、気をつけないと。lb 2023-05-27
import sys
N = int(input())
clist = list(map(int, input().split()))
cmin = min(clist)
for i in range(9):
clist[i] -= cmin
c2i = {}
for i, c in enumerate(clist):
c2i[c] = i+1
n_cmin = c2i[0]
c2i.pop(0) # remove
d = N // cmin
amari = N % cmin
if d == 0:
print(0)
sys.exit()
if not c2i:
print(''.join([str(n_cmin)]*d))
sys.exit()
c2ilist = sorted(list(c2i.items()), key=lambda x:-x[1])
ans = []
for c, n in c2ilist:
if n < n_cmin:
continue
d_cur = amari // c
ans.extend([str(n)]*d_cur)
d -= d_cur
amari -= c*d_cur
ans.extend([str(n_cmin)]*d)
print(''.join(ans))ABC257 F - Teleporter Setting
o N = M = 300000(頂点と辺の数)。ダイクストラ法の計算量なので、O((N+M)LogN) かな?両側からダイクストラということは早めに気づいたが、その頂点を通る必要はないので、1からNまで何もせずにいけるのであれば、そのコストは候補として覚えておかなければならない。もしそのコストの方が小さいならそれが答えになる。b 2023-05-28
ABC256 E - Takahashi's Anguish
x N = 200000(Functional Graphの頂点数)。強連結成分分解なので、O(N+N) ってマ?以前Functional Graphの問題を自力ACしたことがあって、Functional Graph?ふーん?となってたけど、ちゃんと調べてなくてこの問題を解けなかった。N頂点N辺なので、なもりグラフみたいな形になるはず、ということだけを頼りに解いた。この問題では、「Functional Graphの強連結成分は1つのループである」という事実を用いる。すると強連結成分を成すループの最もコストが小さい辺を削除すれば良いことがわかり、解ける。勉強になった。lb 2023-05-28
ABC255 E - Lucky Numbers
x N = 100000(数列の長さ)。M = 10(一致させるラッキーナンバーの数)。O(NM)。ひらめきが必要な問題で、閃かなかった。苦手な問題ってあるんだろうか?数列の隣り合う数の和が決まっていて、数列のできるだけ多くの数をラッキーナンバーにすると何個ラッキーナンバーにできるか?隣同士の和が決まってるので、a1を確定すると全数列が確定することになる。逆にaiがラッキーナンバーであれば、a1も確定する。そのa1の候補が10通りということ。よって、全項で計算して、一番出てきたa1が答え。ひえーこれ思いつきたいが難しいなぁという印象。勉強になった。lb 2023-05-28
from collections import defaultdict
counter = defaultdict(int)
N, M = map(int, input().split())
slist = [0] + list(map(int, input().split()))
xlist = list(map(int, input().split()))
mult = 1
cur = 0
for s in slist:
cur += -mult*s
for x in xlist:
counter[cur+mult*x] += 1
mult *= -1
print(max(counter.values()))ABC255 F - Pre-order and In-order
o N = 200000(二分木の頂点数)。すべての頂点で分割していくので、O(N)ではないだろうか?自力で解けてよかった。再帰的に分割した区間に対して処理をしていく。通りがけ順というのは、この問題で初めて知った。二分木のみが通りがけ順を持っている。道理で聞いたことがないはずだ。二分木の通りがけ順とは、左から順番に並べたもので、つまり二分木でソートした場合のソート結果の数列らしい。というわけで行きがけ順と通りがけ順が与えられるとグラフは一意に決まるはずだ。分岐する頂点は行きがけ順の最初に出てくる、その頂点で通りがけ順を分割すると、左右の部分木のサイズが確定する。同じサイズで行きがけ順も分割していけばどんどん下っていける。b 2023-05-28
import sys
N = int(input())
P = list(map(int, input().split()))
I = list(map(int, input().split()))
if P[0] != 1:
print(-1)
sys.exit()
inI = [-1]*(N+1)
ans = [[0,0] for _ in range(N+1)]
for i, v in enumerate(I):
inI[v] = i
stack = [(0, N-1, 0, N-1)] # pl, pr, il, ir
while stack:
pl, pr, il, ir = stack.pop()
top = P[pl]
topinI = inI[top]
if not (il <= topinI <= ir):
print(-1)
sys.exit()
if il+1 == topinI:
ans[top][0] = I[il]
elif il+1 < topinI:
ans[top][0] = P[pl+1]
diff = topinI-1-il
stack.append((pl+1, pl+1+diff, il, topinI-1))
if topinI+1 == ir:
ans[top][1] = I[ir]
elif topinI+1 < ir:
diff = ir-topinI-1
ans[top][1] = P[pr-diff]
stack.append((pr-diff, pr, topinI+1, ir))
for x in ans[1:]:
print(*x)ABC254 E - Small d and k
o N = 150000(頂点数)、M = 1.5xN(辺)、次数3、Q = 150000、k = 3(たどる距離)。O(3^3 Q)。次数が3なので、1つ答えるのに3^3までしか計算しなくて良い。そのことに気づけば愚直に毎回計算すれば良いとわかる。距離リストは、1つ答えるごとに3^3個の頂点を覚えておいて、リセットして次に備えることとした。そうしないと毎回毎回リストを作ってたら間に合わないんじゃないかな?lb 2023-05-29
ABC254 F - Rectangle GCD
x ムズい。N = Q = 200000。とあるN^2サイズのマスの部分長方形内の数字の最大公約数をQかい回答する。まじかよという問題。GCDも結合則が成り立つので、セグ木に乗せられるらしい。最大公約数は、数字の差の約数である。これはユークリッドの互除法が使っている性質だけど、これを使って、GCDセグ木に差を乗せていくとこの問題は解ける。GCDセグ木なるものを初めて作れて勉強になった。1回目の提出でACできてよかった。ミスは時間ロスにつながるので禁物。下のコードはセグ木を除く。b 2023-05-29
N, Q = map(int, input().split())
A = list(map(int, input().split()))
B = list(map(int, input().split()))
segtA = SEGT(N-1)
segtB = SEGT(N-1)
for i in range(N-1):
segtA.set(i, abs(A[i+1]-A[i]))
segtB.set(i, abs(B[i+1]-B[i]))
ans = []
for _ in range(Q):
h1, h2, w1, w2 = map(int, input().split())
curlist = []
cur = A[h1-1] + B[w1-1]
curlist.append(cur)
if h1 < h2:
cur = GCD(cur, segtA.query(h1-1, h2-1))
curlist.append(cur)
if w1 < w2:
cur = GCD(cur, segtB.query(w1-1, w2-1))
curlist.append(cur)
ans.append(cur)
print(*ans, sep='\n')ABC253 F - Operations on a Matrix
x N(行) = M(列)= Q = 200000。l列からr列までに足す操作があってj列目の値をあるタイミングで得る必要があるので、遅延セグ木?と思った。クエリ先読みで後ろから逆再生しながら遅延セグ木を使えば解けそうだなーと思ったけど、なんとなく解答見たらもっと良い方法で、その方がいい!使いこなしたい!と思った。そういえば遅延セグ木のようなレンジaddを扱う方法がもう1つあり、いもす法だ!いもす法は最後に累積和ですべての位置の値を求めるが、あるタイミングで特定の位置の値が必要になるパターンなので、ここではフェニック木を使えば良いと。いやーいいねぇこれ。遅延セグ木が頭に浮かんだときに、「いもす法でできない?」と思うクセをつけておくと良さそうだ。クエリ先読みは必要で、2と3を先に処理して、あとで1のみを処理していく感じで、まあまあややこしい。b 2023-05-29
class BIT():
def __init__(self, n):
self.n = n
self.sums = [0]*(n+1)
def add(self, i, input):
while i <= self.n:
self.sums[i] += input
i += i&-i
def prod(self, i):
'''return 0 if i == 0'''
res = 0
while i > 0:
res += self.sums[i]
i -= i&-i
return res
def prod_range(self, i, j):
return self.prod(j) - self.prod(i)
N, M, Q = map(int, input().split())
rows = [(0,0)]*(N+1) # time, value
qlist = [list(map(int, input().split())) for _ in range(Q)] # index = time - 1
from collections import defaultdict
ins = defaultdict(list)
outs = {}
ans = []
for i, q in enumerate(qlist):
time = i + 1
if q[0] == 2:
_, r, x = q
rows[r] = (time, x)
elif q[0] == 3:
_, r, c = q
ans.append([rows[r][1], c])
ians = len(ans) - 1
ins[rows[r][0]].append(ians)
outs[time] = ians
bit = BIT(M+1) # [M+1]
for i, q in enumerate(qlist):
time = i + 1
if q[0] == 1:
_, l, r, x = q
bit.add(l, x)
bit.add(r+1, -x)
else:
if time in ins:
for ians in ins[time]:
ans[ians][0] -= bit.prod(ans[ians][1])
if time in outs:
ians = outs[time]
ans[ians][0] += bit.prod(ans[ians][1])
for x in ans:
print(x[0])ABC252 E - Road Reduction
o N = 200000(頂点数)、M = 200000(辺数)。ダイクストラでどの辺を使ったか?を覚えておけば解けるだけなので、ダイクストラをいじって解く。ダイクストラ法の結果として1つのツリーが生成されるという事実に気づかせてくれる問題。そう考えたことなかった。lb 2023-05-29
INF = 10**15
N, M = map(int, input().split())
edges = [[] for _ in range(N+1)]
for i in range(M):
a, b, c = map(int, input().split())
edges[a].append((b, c, i+1))
edges[b].append((a, c, i+1))
costs = [INF]*(N+1)
costs[1] = 0
import heapq
pq = [(0, 1)]
ans = [0]*(N+1)
while pq:
cost, cur = heapq.heappop(pq)
if cost > costs[cur]:
continue
for nex, c, eid in edges[cur]:
if cost + c < costs[nex]:
ans[nex] = eid
costs[nex] = cost + c
heapq.heappush(pq, (cost + c, nex))
print(*ans[2:])ABC252 F - Bread
o N = 200000(切り分け回数)。プライオリティキュー。3つの場合を試すと、小さいの同士をつなぐのが最適な気がする。逆再生で小さいの同士をつないでいけばいいだろうと、無証明で投げたら通った。4以上に切り分ける場合の証明ができない。いずれちゃんと確認しよう。b 2023-05-29
N, L = map(int, input().split())
alist = list(map(int, input().split()))
amari = L - sum(alist)
if amari > 0:
alist.append(amari)
import heapq
heapq.heapify(alist)
ans = 0
while len(alist) > 1:
x = heapq.heappop(alist)
y = heapq.heappop(alist)
ans += x + y
heapq.heappush(alist, x+y)
print(ans)ABC251 D - At Most 3 (Contestant ver.)
x N = 300。W = 1000000。300個の整数から3つ以下の整数を選んで合計することで1000000までの整数全部埋めつくせという問題。閃きだけの問題だったが、閃かなかった。2進数で考えてそこから抜け出せず。100万は2進数20桁で、1bit立っている数字3つで3bit立ってる数字を作れるなぁ。20C3 = 1140。全然だなぁ。残りどうやるんだろう?みたいに考えてそこから出られず。3桁ですませるには何進数か?と考えなければならない。100進数3桁で1000000まで表現できるじゃん。しかもちょうど300!閃きてぇ。lb 2023-05-30
ABC251 E - Takahashi and Animals
o N = 300000。O(N)かな。普通のDPだけど、N-1と0の間を選ぶかどうか?で2回に分けてDPをやった。解説はなんか1回で済んでそうだったけど、まあいいや。lb 2023-05-30
ABC251 F - Two Spanning Trees
o N = 200000(頂点)。M = 200000(辺)。辺を選択して頂点1を根とする木を作るとき、すべての選ばなかった辺の2点が木の祖先と子孫の関係にある木と、すべての選ばなかった辺の2点が木の祖先と子孫の関係にない木を作れという問題。なかなかギョッとする問題だが、絵を描いているうちに閃けた。DFSで木を作ったら選ばれない辺は祖先と子孫の関係になるじゃんと。一方、BFSで木を作ったら選ばれない辺は祖先と子孫の関係にならないじゃんと。SCCのアルゴリズムとか理解しようとしてたときに、なんか辺をたどるときの性質で似たようなことを考えていた記憶があってもしかしてたどり方だけで、この問題解けるのでは?と思えた。おもしろいなぁ。しかし、問題が発生して、なぜかWAが大量に出る。調べているうちに、ぼくのDFSが実はDFSじゃなかったことに気づいた。具体的には、スタックを使っているけど、積むときに子供を幅優先的に確定してしまっていた。DFSは、積むときではなく、取り出すときに確定しなければならないのだった。そして、すでに確定したものがスタックから取れたときは無視する。というわけで、DFSのコード今までよりちょっと複雑になった。いやー勘違いすごい。今まで半年以上競プロやってて気づかなかったし、問題にならなかった。今回、厳密にDFSでなければ解けない問題に出会うことによって、自分のDFSがおかしかったことに気づけた!勉強になる!b 2023-05-30
from collections import deque
N, M = map(int, input().split())
G = [[] for _ in range(N+1)]
for _ in range(M):
u, v = map(int, input().split())
G[u].append(v)
G[v].append(u)
stack = [(0, 1)] # parent, cur
P = [-1]*(N+1)
P[1] = 0
ans = []
while stack:
p, cur = stack.pop()
if P[cur] < 1:
P[cur] = p
if p != 0:
ans.append((p, cur))
for nex in G[cur]:
if P[nex] == -1:
stack.append((cur, nex))
q = deque([])
q.append(1)
used = [False]*(N+1)
used[1] = True
while q:
cur = q.popleft()
for nex in G[cur]:
if not used[nex]:
ans.append((cur, nex))
q.append(nex)
used[nex] = True
for x in ans:
print(*x)ABC250 E - Prefix Equality
o N = Q = 200000(数列サイズとクエリ数)。O(N Log N)かな。N項ループさせて、setの一致判定するので。まあできたのでオッケー。時間制限をどうやって乗り越えるか?という問題だった。lb 2023-05-31
N = int(input())
alist = list(map(int, input().split()))
blist = list(map(int, input().split()))
aset = set()
bset = set()
aset.add(alist[0])
bset.add(blist[0])
i = j = 1
previ = prevj = 0
diff = prev_diff = 0 if alist[0] == blist[0] else 2
res = [[-1, -1] for _ in range(N)]
while True:
while i < N:
if alist[i] not in aset:
aset.add(alist[i])
break
i += 1
while j < N:
if blist[j] not in bset:
bset.add(blist[j])
break
j += 1
if i != N and j != N and alist[i] != blist[j]:
if alist[i] in bset:
diff -= 1
else:
diff += 1
if blist[j] in aset:
diff -= 1
else:
diff += 1
if prev_diff == 0:
for ia in range(previ, i):
res[ia][0] = prevj
res[ia][1] = j-1
if i == N or j == N:
break
previ = i
prevj = j
prev_diff = diff
Q = int(input())
for _ in range(Q):
x, y = map(int, input().split())
if res[x-1][0] <= y-1 <= res[x-1][1]:
print('Yes')
else:
print('No')ABC249 E - RLE
x N = 3000(文字数)。O(N^2) = 9000000。Nより短いパターンを数えるので、Yの長さはNを超えて調べる必要がないため、N^2。解けなかった。普通に考えるとO(N^3)になってしまう。Xをi文字目まで確定したときのYの文字数は最後にn文字連続する場合として遷移すると0からi-1まで全部見なければならない。しかし最大でも5文字(たとえばaが1200文字並んでいればa1200となって5文字)しか増えず、2、3、4、5しかありえないとわかる。よってまとめられる。累積和すればオッケー。N^3で間に合わねーなーとなったときに、3つ目のNは累積和で圧縮できるのでは?と疑うべき。 2023-06-04
N, P = map(int, input().split())
dp = [[0]*(N) for _ in range(N+1)]
dp[0][0] = 1
for i in range(1, N+1): # i-1 -> i 配る
for j in range(N-2): # 配る
if j+2 <= N-1:
dp[i][j+2] += (dp[i-1][j] - (dp[i-10][j] if i>=10 else 0))*(25 if j>0 else 26)
if j+3 <= N-1 and i >= 10:
dp[i][j+3] += (dp[i-10][j] - (dp[i-100][j] if i>=100 else 0))*(25 if j>0 else 26)
if j+4 <= N-1 and i >= 100: # 100-999
dp[i][j+4] += (dp[i-100][j] - (dp[i-1000][j] if i>=1000 else 0))*(25 if j>0 else 26)
if j+5 <= N-1 and i >= 1000:
dp[i][j+5] += (dp[i-1000][j] - (dp[i-10000][j] if i>=10000 else 0))*(25 if j>0 else 26)
for j in range(N):
dp[i][j] = (dp[i][j] + dp[i-1][j]) % P
ans = 0
for j in range(N):
ans = (ans + dp[N][j] - dp[N-1][j]) % P
print(ans)ABC249 F - Ignore Operations
o N = 200000。O(N Log N)かな。ループしながらプライオリティキュー使う。プライオリティキューはポップがLogNらしい。並び替えか。結構難しい感じだが閃いた。t=1でxをyに置き換える処理をすると、リセットされてしまうので、それ以前の数字は無視しなくても無視したことになる。なので後ろから調べていって、t=1のところと全部見終わったところで答えの候補を計算して最大値を求めれば良い。t=1のところを通過したら、その先を調べる時点で、通貨したt=1は無視確定であり、t=2で無視できる数が1つ減ると考える。大きな値にするにはt=2のところで負の数を無視して足さないようにしたい。無視できる数の限界を超えた場合、できるだけ大きくするには負の数を小さい順に無視する必要があり、その管理にプライオリティキューを使えば良い。まあ結構バグって修正時間かかった。 2023-06-04
N, K = map(int, input().split())
Q = [tuple(map(int, input().split())) for _ in range(N)]
Q.reverse()
ans = -10**16
cur = 0
import heapq
pq = [] # 最初K個、t==1のたびにそれも無視するので減らす、マイナスになったら限界なので終了
for t, y in Q:
if t == 2:
if y < 0:
if K == 0:
cur += y
elif len(pq) == K: # K > 0
if -y > pq[0]:
modosu = heapq.heappop(pq)
heapq.heappush(pq, -y)
cur -= modosu
else:
cur += y
else: # len(pq) < K
heapq.heappush(pq, -y)
else: # y >= 0
cur += y
else: # t == 1
ans = max(ans, cur+y)
K -= 1
if len(pq) > K >= 0:
modosu = heapq.heappop(pq)
cur -= modosu
elif K < 0:
break
ans = max(ans, cur)
print(ans)ABC248 E - K-colinear Line
o N = 300。O(N^3)かと思うけど、フルでN^3計算する必要はなさそうというのはわかる感じ。94msで最速に近いコードで出せた。頂点1を通るものを調べながら、そこで見つかった直線上の点は頂点2以降で調べないようにする。lb 2023-06-07
import sys
N, K = map(int, input().split())
from collections import defaultdict
XY = [tuple(map(int, input().split())) for _ in range(N)]
used = [[False]*N for _ in range(N)]
ans = 0
if K == 1:
print('Infinity')
sys.exit()
for i in range(N-1):
xi, yi = XY[i]
lines = defaultdict(list)
vert = []
for j in range(i+1, N):
if used[i][j]:
continue
xj, yj = XY[j]
if xi - xj != 0:
k = (yi-yj) / (xi-xj)
lines[k].append(j)
for other in lines[k]:
used[other][j] = True
else:
vert.append(j)
for other in vert:
used[other][j] = True
for tolist in lines.values():
if len(tolist) >= K-1:
ans += 1
if len(vert) >= K-1:
ans += 1
print(ans)ABC248 F - Keep Connect
o DPというのを見た。これ本番で解けたらいいなぁ。N = 6000(頂点数)。O(N^2)かな。左から順に調べる。常に連結じゃなくても右端でつながれば全体が連結になるので、DPどうやるんだろう?となってしまうが、i番目を見ている段階で、上下の頂点が非連結で2つに分離している状態が許容されるということに気づけばDPに持ち込める。DP前提で、どうやる?と考えよう。連結状態と非連結状態を保持する。連結から連結、連結から非連結、非連結から連結、非連結から非連結への推移でどのようなパターンがあり、何本削除するのか?絵を描いて整理すれば解ける。こういうの解きたい。本当に。b 2023-06-07
N, P = map(int, input().split())
dpcon = [[0]*N for _ in range(N)]
dpdis = [[0]*N for _ in range(N)]
dpcon[0][0] = 1 # 連結
dpdis[0][1] = 1 # 非連結
for i in range(1, N):
for j in range(0, N): # remove j
dpcon[i][j] = (dpcon[i][j] + dpcon[i-1][j] + dpdis[i-1][j]) % P
if j < N-1:
dpcon[i][j+1] = (dpcon[i][j+1] + 3*dpcon[i-1][j]) % P
dpdis[i][j+1] = (dpdis[i][j+1] + dpdis[i-1][j]) % P
if j < N-2:
dpdis[i][j+2] = (dpdis[i][j+2] + 2*dpcon[i-1][j]) % P
print(*[dpcon[N-1][j] for j in range(1, N)])ABC247 E - Max Min
x しゃくとり法でいけることに気づかず。無念。しかもそれを前提にやり始めても実装にかなり苦労した。こういう条件分岐を短時間で整理しきれない。水Diffかぁ。N = 200000。O(N)。こういうの短時間で書ける人どうなってるのかなぁ。なんでしゃくとり法って気づけなかったかっていうと、lを1つずつずらしていって、r確定、その右側全部をカウントするという流れを思い浮かべられなかったから。lの方もギリギリまで進めて左右の掛け算をすると思い込んでしまった。これだけでだいぶ厄介なことになる。lは1つずつ進めればいいのだ…。lb 2023-06-08
N, X, Y = map(int, input().split()) # Y <= X
A = list(map(int, input().split()))
s = t = 0
ans = 0
while s < N:
while s < N and (A[s] < Y or X < A[s]):
s += 1
if s == N:
break
t = s
while t < N and Y <= A[t] <= X:
t += 1
t -= 1
# [s, t] is valid
l = r = s
count = [0, 0] # Y count, X count
while l <= t:
while r <= t:
if A[r] == Y:
count[0] += 1
if A[r] == X:
count[1] += 1
if count[0] > 0 and count[1] > 0:
# [l, r] meet the condition
break
r += 1
else:
break # not found
# [l, r] meet!
ans += t - r + 1
while True:
if A[l] == Y:
count[0] -= 1
if A[l] == X:
count[1] -= 1
l += 1
if count[0] > 0 and count[1] > 0:
ans += t - r + 1
else:
break # l = r+1 or count[0] == 0 or count[1] == 0
r += 1
s = t + 1
print(ans)ABC247 F - Cards
o N = 200000(頂点数)。O(N)。カードの裏も表も1-Nの順列。全点被覆するための辺の選び方のパターン数を数える問題。裏と表の数字を辺でつないでいくとどうなるかというと、ループが複数できることがわかる。1-Nが表裏でちょうど2回出るので。まずこのことに気づく必要がある。なもりグラフを書いてみて、あれひげはないなぁ、同じ数字は必ず2回参照されるのだから。ということで全部サイクルとわかる。では隣り合う辺は必ずどちらかを選ぶようなパターンは何通りあるか?そういうのシンプルに求める方法ありそうだなぁ、とはちょっと悩むけど、まあDPでいいでしょ。b 2023-06-10
M = 998244353
N = int(input())
P = list(map(int, input().split()))
Q = list(map(int, input().split()))
G = [[] for _ in range(N)]
for p, q in zip(P, Q):
if p != q:
G[p-1].append(q-1)
G[q-1].append(p-1)
dp0not = [[0]*N for _ in range(2)] # 1st edge no select, [0] not select [1] select
dp0sel = [[0]*N for _ in range(2)] # 1st edge select
dp0not[0][0] = 1
dp0sel[1][0] = 1
for i in range(1, N):
dp0not[0][i] = dp0not[1][i-1] % M
dp0not[1][i] = (dp0not[1][i-1] + dp0not[0][i-1]) % M
dp0sel[0][i] = dp0sel[1][i-1] % M
dp0sel[1][i] = (dp0sel[1][i-1] + dp0sel[0][i-1]) % M
ans = 1
used = [False]*N
for v in range(N):
if not used[v] and G[v]:
stack = [v]
used[v] = True
count = 0
while stack:
cur = stack.pop()
for nex in G[cur]:
if not used[nex]:
stack.append(nex)
used[nex] = True
count += 1
ans *= (dp0not[1][count] + dp0sel[0][count] + dp0sel[1][count])
ans %= M
print(ans)ABC246 E - Bishop 2
o 制限時間6秒、自分の拡張ダイクストラは、3.5秒くらいになった。まあいいや。マスサイズ = NxN = 1500x1500 = 225万。拡張ダイクストラの頂点数はどうなる?見積もれない。全部.なら4Nくらいになる、それが#によって区切られると増えるけども。って感じ。拡張ダイクストラのエッジ数はマスの数と一致するので225万か。O(E + V Log V)だっけ。20x225万とするとかなり抑えられるからオッケーか。自力でいけたのは良かったが実装重い。解説によると、なんかいい方法があるっぽい。01-bfsというらしい。学習しておくべきだ。lb 2023-06-10
N = int(input())
sx, sy = map(int, input().split())
sx, sy = sx-1, sy-1
ex, ey = map(int, input().split())
ex, ey = ex-1, ey-1
# V頂点[右下方向,左下方向]
V = [[[-1,-1] for _ in range(N)] for _ in range(N)]
grid = [list(input()) for _ in range(N)]
vno = 0
for i in range(N):
for j in range(N):
if grid[i][j] == '.':
if V[i][j][0] == -1:
V[i][j][0] = vno
x, y = i+1, j+1
while x < N and y < N and grid[x][y] == '.':
V[x][y][0] = vno
x, y = x+1, y+1
vno += 1
if V[i][j][1] == -1:
V[i][j][1] = vno
x, y = i+1, j-1
while x < N and y >= 0 and grid[x][y] == '.':
V[x][y][1] = vno
x, y = x+1, y-1
vno += 1
start = vno
INF = 10**10
edges = [[] for _ in range(vno+1)]
for i in range(N):
for j in range(N):
if grid[i][j] == '.':
u, v = V[i][j]
edges[u].append((v, 1))
edges[v].append((u, 1))
u, v = V[sx][sy]
edges[start].append((u, 1))
edges[start].append((v, 1))
costs = [INF]*(vno+1)
costs[start] = 0
import heapq
pq = [(0, start)]
while pq:
cost, cur = heapq.heappop(pq)
if cost > costs[cur]:
continue
for nex, c in edges[cur]:
if cost + c < costs[nex]:
costs[nex] = cost + c
heapq.heappush(pq, (cost + c, nex))
u, v = V[ex][ey]
ans = min(costs[u], costs[v])
print(-1 if ans == INF else ans)ABC246 F - typewriter
o N = 18(タイプライターの数)文字数 = 26。O(2^N)。これは割と余裕持って解けた。18種類に対していくつか選ぶ全パターンを包除原理に従って足したり引いたり。2^18は26万程度なので全部調べても計算に余裕あり。文字列をbit列に変換するのとか慣れたものだ。b 2023-06-10
from itertools import combinations
M = 998244353
N, L = map(int, input().split())
ans = 0
all_ = 2**26 - 1
ORDA = ord('a')
keys = [sum([1<<(ord(c)-ORDA) for c in list(input())]) for _ in range(N)]
for sel in range(1, N+1):
mul = -1 if sel % 2 == 0 else 1
for combi in combinations(range(N), sel):
ist = all_
for i in combi:
ist &= keys[i]
count = bin(ist).count('1')
ans = (ans + mul * pow(count, L, M)) % M
print(ans)ABC245 E - Wrapping Chocolate
x むっず~。C++ならmultisetでできるけど、Pythonでできん(っていうか今まで出会ったことない)パターンだった。C++でやろうかなぁ。というわけでC++でやったら楽すぎてビビった。期待を裏切ってコード短いし、速いし!あれ?ちょっとC++やる気出た?multisetにlower_boundがあるので、どんどん要素を追加していく集合で、ある値以上の最小要素を高速に見つけられる。たぶんO(Log N)。これをPythonでやる構造は標準でたぶんない。フェニック木に2分探索入れて和がある値になるところを見つけなければならないのか。しかもフェニック木使うために座圧しないといけないし。座圧面倒とか言ってたらしょぼいのかもしれんけど。でもこのC++コードは楽だ。C++もっと書いていきたいって思えた。もっとC++書きたい書きたい書きたい!lb 2023-06-12
// C++
#include <bits/stdc++.h>
using namespace std;
#define rep(i,n) for(int i=0;i<n;i++)
#define REP(i,n) for(int i=n-1;i>=0;i--)
int main()
{
using pii = pair<int, int>;
int N, M;
cin >> N >> M;
vector<pii> choco(N), box(M);
rep(i, N) { cin >> choco.at(i).first; }
rep(i, N) { cin >> choco.at(i).second; }
rep(i, M) { cin >> box.at(i).first; }
rep(i, M) { cin >> box.at(i).second; }
multiset<int> widths;
sort(choco.begin(), choco.end());
sort(box.begin(), box.end());
int j = M - 1;
bool ok = true;
REP(i, N) {
auto& [h, w] = choco.at(i);
while (j >= 0 && box.at(j).first >= h) {
widths.insert(box.at(j).second);
j--;
}
auto it = widths.lower_bound(w);
if (it == widths.end()) {
ok = false;
break;
}
else {
widths.erase(it);
}
}
cout << (ok ? "Yes" : "No") << endl;
return 0;
}ABC245 F - Endless Walk
o N = M = 200000。強連結成分分解して末端から遡りながら当てはまらないものを数えて、Nから引く。KahnのDAG判定アルゴリズムを逆からやる感じでやったらACできたけど、最初、逆から辿れる頂点数1の強連結成分は全部当てはまらないと勘違いしててWAx11になってた。その頂点から頂点数2以上の強連結成分につながってるかもしれないの見逃してた。だから逆Kahnなんだと…。lb 2023-06-11
.