
類似事例を使って要約モデルの性能を向上させる

こんにちは。メディア研究開発センター(M研)の田口です。
今回は、自然言語処理のトップ会議であるACL2022で採択された “Training Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data”の内容と、その手法を日本語の見出し生成タスクで実験した結果を紹介したいと思います。
訓練データは思っている以上に価値がある?
”Training Data is More Valuable than You Think(訓練データは思っている以上に価値がある)”という若干釣りっぽいタイトルが気になりましたが、社内の論文読み会で取り上げました(M研では毎週論文読み会を行っています)。
この論文の提案手法は非常にシンプルで、記事のタイトルのとおり「類似事例を使っている」だけです。どう使うのかというと、訓練もしくは推論時に入力の末尾に類似事例を結合しているだけです。英語の要約タスクでは、
入力:本文
出力:要約
という形式でモデルを学習します。一方、この論文では下記のような入力フォーマットを用います。
入力:本文+本文と類似する事例の要約1+…+本文と類似する事例の要約N
出力:要約
これだけでは分かりづらいと思うので、日本語の見出し生成を例にして説明します。この場合、入力が記事本文、出力は見出しになります。「類似する事例の要約」というのは、「本文が似ている他の記事の見出し」になります。
下記の例では、記事本文と類似する記事の見出し3本を本文末尾に結合しています。わかりやすいように本文および見出しの間には<SEP>を挿入しています。
入力(記事本文+類似する記事の見出し3本):
3月26日に開業する北海道新幹線H5系車両が1日、新青森-新函館北斗の全区間を通して走った。日中に全区間を走るのは初めて。(中略)次に全区
間を通して昼間に走るのが見られるのは、開業直前の3月22~25日の予定。<SEP>北海道新幹線、走行試験で時速260キロ達成<SEP>北海道新幹線、来年3月26日に開業 1日13往復運行<SEP>北海道新幹線が開業 一番列車は満席、見物客から拍手も
出力(見出し):
北海道新幹線、日中初の「晴れ姿」 全区間を通して走行
なんとなくイメージはつかめたでしょうか?
類似事例の検索は、Elasticsearchなどので事前に訓練データのインデックスを作成しておき、本文と類似している事例の正解ラベル(要約)を入力の文字列に結合します。しかし、このやり方では訓練データAに類似する事例の正解ラベルは訓練データAの正解ラベル自身になってしまいます(クエリである本文の文字列が完全に一致するため)。
そこで、元論文では図1のようなパイプラインで処理します。訓練データに類似事例の正解ラベルを付与する際には「Filter」という処理を挟んでいます。これは単純に、自身の正解ラベルは除き、それ以外の類似事例を使っているだけです。

元論文の要約タスクの実験では、入力文600単語+類似する要約5つを結合しています。これがこの論文の手法であるREINA(REtrieving from the traINing datA)です。これにより、5種類の要約タスクでROUGE(モデルの出力と正解要約の単語の被覆率)スコアが向上したと報告しています。
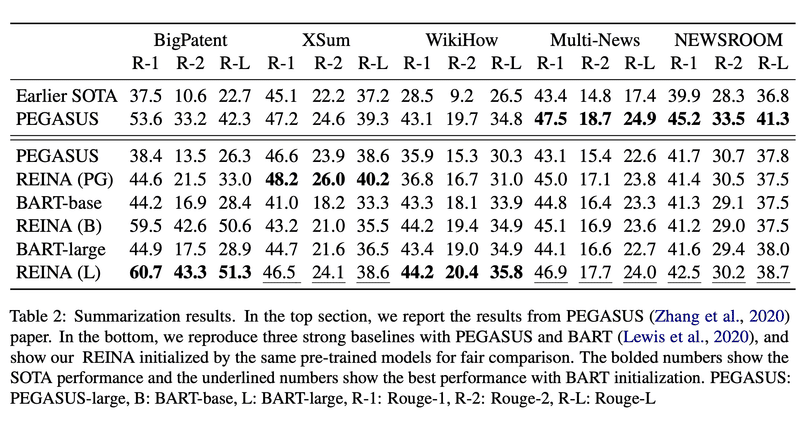
表にあるPEGASUSやBARTはどちらもSeq2Seq型の事前学習済み言語モデルになります。PEGASUSは要約に特化した事前学習モデルで、BARTはトークンのマスクや文の並び替えなどのタスクを解かせて訓練した事前学習モデルです。どちらのモデルも最近の要約タスクでよく用いられるモデルです。
大半のデータセットではREINAが性能向上に寄与している一方、NEWSROOMタスクではPEGASUおよびBART-largeはむしろ性能が低下しています。論文中には、それに対するエラー分析は特にありませんでした。個人的には、NEWSROOMタスクは40近くのメディアの記事が扱われているため、類似事例を検索した際に文字列が似ている他メディアの要約が検索されてしまい、それが入力となることで結果としてROUGEが下がっているのではないかと考えています。
REINAを日本語見出し生成タスクで実験してみる
論文読み会で紹介した際には「シンプルだけど本当に効果があるのだろうか?」という印象でした。また、著者が公開している実装を見ても「入力文600単語+類似する要約5つを結合」の部分はスペース区切りで結合されているだけで、「SEPなどの特殊トークンを挟まないと、どこからが類似事例の要約かわからないのでは?」と不思議に感じました。というわけで、今回のテックブログのネタとして実際に日本語の見出し生成タスクで実験してみました。
データセットについて
今回の実験では、JAMUL2020とJNCというデータセットを利用します。データセットの詳細は下記リンクを参照してください。
JAMUL 2020は2014年5月から2019年6月までに朝日新聞社が展開する要約サービス ANDES で配信された 30,656 件のデータから構成されます。それぞれの記事に対して最大で5種類の見出し・要約が付与されています。
JNCは、10年間(2007年~2016年)分の記事のリード3文(記事の最初から最大3文)と、朝日新聞紙面に掲載された見出しのペア1,828,231件を収録したコーパスです。
JAMUL2020は記事本文と朝日新聞デジタル向けにつけられた見出しを使用し、JNCは全データの一部を使って実験を行いました。本当は約180万記事すべてを使いたかったのですが、実験にかかる時間を考慮して今回は意図的にデータのサイズを落としています。
各データごとの記事の掲載年月はこのようになっています。
JAMUL2020
訓練データ:2014年5月〜2018年3月
開発データ:2018年4〜10月
テストデータ:2018年11月〜2019年6月
JNC
訓練データ:2015年7月〜2016年10月
開発データ:2016年11月
テストデータ:2016年12月
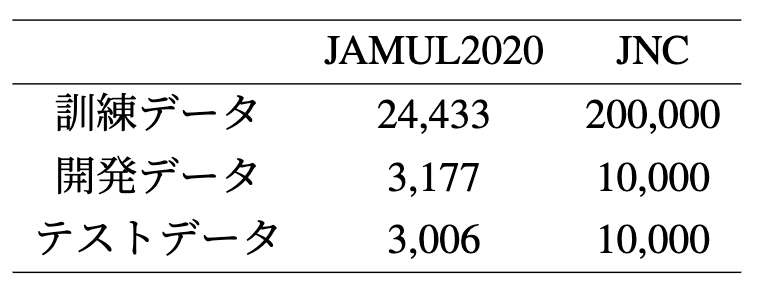
各データごとの訓練、開発、テストデータのデータ数は下記のとおりです。JAMUL2020は生成系のタスクとしては比較的小さいため、JNCではより大きいデータサイズにしています。これは英語の要約タスクでよく用いられるXSUMデータと同じくらいのサイズです。
モデルについて
データについてはこのくらいにして、次はモデルについてです。京大が公開している日本語版BARTはfairseqを利用するため、今回はHuggingfaceのTransformersを使って実験するので日本語版T5を利用しました。元論文では英語版のPEGASUSやBARTが利用されており、REINA自体は入力を加工しているだけなのでT5でも問題ないと判断しました。
学習・デコード時のパラメータ
T5モデルおよびREINAのどちらも共通のハイパーパラメータで学習しています。バッチサイズは64、エポック数は5(JNCでは3)で、それ以外はtransformersの要約モデルのfine-tuningコードのデフォルトパラメータを使用しました。また、テストデータのデコード時には以下のパラメータを使用しました。
{
"num_beams": 5, # ビーム幅
"no_repeat_ngram_size": 2, # 連続する2単語を繰り返し出現させない
"max_length": 64, # 生成する系列の最大トークン長
}
評価方法
要約タスクで一般的なROUGEスコアで評価しています。ROUGEスコアについて詳しく知りたい方はこちらの記事を参照してください。
また、今回はモデルの評価を行うにあたって、3つの乱数シードを用いてモデルを訓練・評価しています。実験結果には、3つのモデルのテストデータ上での結果を平均化したものを記載しています。
REINAについて
実験を行うにあたり、JAMUL2020、JNCそれぞれの訓練データをElasticsearchを使ってインデックスを作成しました。Analyzerにはkuromojiを使用しました。類似事例の検索は各訓練データ内で行い、元論文と同様に自身の正解ラベルは除き、それ以外の類似事例の見出しを付与しました。
元論文では、「入力文600単語+類似する要約5つ」という形式を取っています。この「類似する要約5つ」という設定の根拠は論文中で特に言及されていませんでした。そこで今回は、類似する見出しを1、3、5つ付与する形式で実験してみます。実験結果の表にはそれぞれREINA-1、REINA-3、REINA-5と記しています。
入力文の結合方法
入力文と類似事例の見出しを結合する際に、T5トークナイザーに登録されている特殊トークン(<extra_id_0>)を挿入して実験も行いましたが、スペース区切りのものと比較してROUGE-1で0.1ポイント程度落ちる結果になりました。そこで、今回は元論文に従ってスペース区切りで結合する形式の実験結果のみ表にまとめています。
実験結果
実験結果は以下のとおりです。元論文ほどのスコアの向上は見られないものの、JAMUL2020およびJNCのどちらでも性能が向上しました。
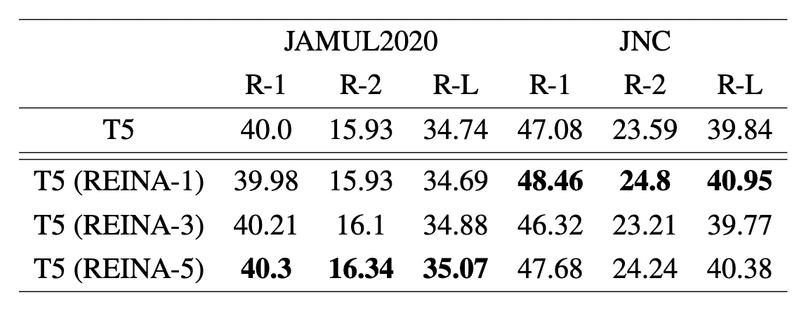
JAMUL2020では事例数が1のときに、JNCでは事例数3のときにそれぞれベースラインを下回りました。これに関する詳細なエラー分析はできていませんが、
JAMUL2020の場合は朝日新聞デジタル用の見出しのため決まった文字数の見出しが多い
JNCは紙面の見出しのため紙面の制約上似た記事であっても見出しの長さにばらつきがある
この辺が原因かもしれません。元論文でもNEWSROOMのデータで一部モデルの性能が劣化していましたが、「いかに本来の正解に近いスタイルや長さの見出しを検索してこれるか」次第でパフォーマンスにも差が出そうです。今回はElasticsearchで単純に検索しているだけなので、より良い事例を探すにはリランキングなどの処理が必要そうですね。
余談
REINAの論文を読んだ際、「あれ、似たような論文昔読んだことあるぞ」と思いました。類似事例の検索、入力文と結合、リランキングといった話は4年前にACLで発表された”Retrieve, Rerank and Rewrite: Soft Template Based Neural Summarization”(以下、Re3 Sum)でも同様のことを提案していました。
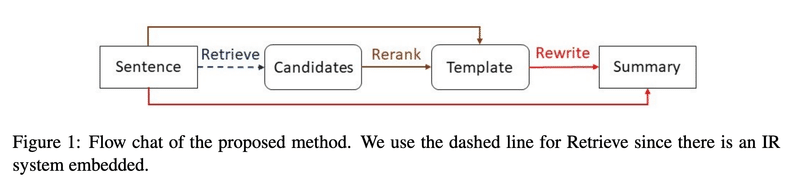
本論文では単純に検索エンジンから類似事例を取り出すだけではなく、
「本文+類似事例の要約」からROUGEスコアを予測し、それにもとづいてリランキング
単純な検索およびリランキングの効果の検証
を行っています。REINA論文との差分としては、
REINAは事前学習モデルを使っており、Re3 SumではBi-LSTMを使用
REINAではデフォルトの事例数が5つで、Re3 Sumでは事例数は1つのみ
REINAでは要約以外にも機械翻訳や質問応答で実験しているが、Re3 Sumでは英語の短文要約の実験のみ
くらいでしょうか。ちなみに、こちらの論文はREINA論文では引用されていませんでした。
おわりに
今回はACL2022で発表されたREINAという手法について紹介し、日本語見出し生成タスクでの実験を行いました。論文がデフォルトで採用している「類似事例5つ」という形式は、データセットによってはかえって結果が悪化することがあるため、類似事例の数自体が一つの重要なハイパーパラメータになりそうです。
また、今回のブログでは単純にROUGEスコアの報告のみになりましたが、付与する事例を変えたときにモデルがどのような挙動をするのかについてはまた別途検証したいと思います。
(メディア研究開発センター・田口雄哉)