YouTube検索のカスタムツールを作成してLangGraphで利用する
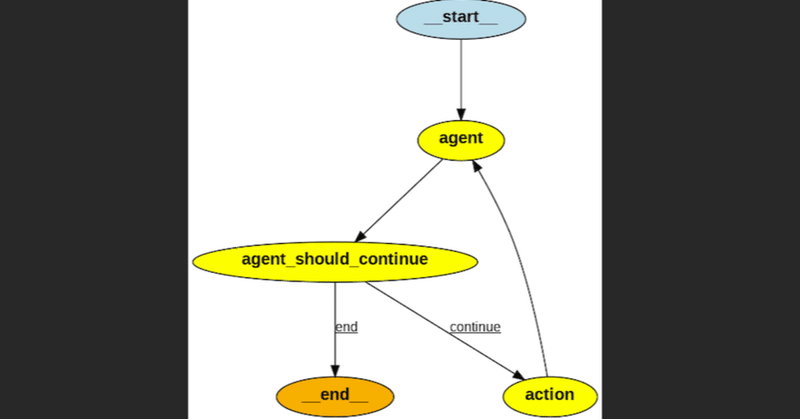
はじめにLangChainは、大規模言語モデル(LLM)を利用したアプリケーション開発を容易にするフレームワークです。一方、LangGraphはLangChainを基にした新たなライブラリで、複数の計算ステップやアクター間で情報を循環させることを可能にし、より複雑なアプリケーションの構築をサポートします。本記事では、LangGraphにYouTube検索のカスタムツールを組み合わせることで、動画検索が可能にしました。これにより、Web上のテキストメディアだけでなく、動画情報も