
Orca : GPT-4の推論過程を模倣し、ChatGPTに匹敵する性能を有する13BのOSS言語モデル

Orca: Progressive Learning from Complex Explanation Traces of GPT-4というMicrosoft Researchが発表した論文の一部を紹介します。
従来のinstruction-tuned model (Vicuna-13Bなど)とは異なり、GPT-4のような大規模言語モデルのステップバイステップの推論過程を学習させることで、軽量なモデルながらChatGPT (3.5)に匹敵する精度を実現したモデルとのことです。
要約( by ChatGPT)
Microsoft Researchが開発した13億パラメータのモデルOrcaは、GPT-4からの豊富な信号、説明のトレース、ステップバイステップの思考過程を利用して、大規模基盤モデル(LFMs)の推論過程を模倣するように学習します。Orcaは従来の最先端のinstruction-tuned model (Vicuna-13Bなど)を上回り、SAT、LSAT、GRE、GMATなどの専門的な学術試験で競争力のあるパフォーマンスを示します。この研究は、ステップバイステップの説明から学習することが、モデルの能力とスキルを改善するための有望な方向性であることを示しています。モデルの重みの差分は、今後LLaMAのリリースポリシーに従って公開されますhttps://aka.ms/orca-lm。
概要
最近の研究では、模倣学習を利用して大規模な基盤モデル(LFMs)が生成する出力を参考に、小さなモデルの性能を向上させることに焦点が当てられています。これらのモデルの品質に影響を及ぼす要因は多く、浅いLFMの出力から得られる限定的な模倣信号、小規模な同質のトレーニングデータ、そして特に厳格な評価の欠如により、小さなモデルがLFMsのスタイルを模倣することはあっても、その推論プロセスを学ぶことが少ないため、小さなモデルの能力が過大評価されることが挙げられます。
これらの課題に対処するために、我々はOrcaという130億パラメータのモデルを開発し、LFMsの推論プロセスを模倣するように学習します。Orcaは、GPT-4からの豊富な信号を学び、説明のトレース、段階的な思考プロセス、およびChatGPTからの教師の支援によって案内されるその他の複雑な指示を含みます。この段階的な学習を促進するために、我々は大規模で多様な模倣データにアクセスし、慎重なサンプリングと選択を行います。
Orcaは、Vicuna-13Bなどの従来の最先端の指示調整モデルを大幅に上回り、BigBench Hard (BBH)などの複雑なゼロショット推論ベンチマークで100%以上、AGIEvalでは42%の向上を示します。さらに、OrcaはBBHベンチマークでChatGPTと同等の性能を達成し、SAT、LSAT、GRE、GMATなどの専門的および学術的な試験で競合性能を示します(最適化されたシステムメッセージとのギャップは4ポイント)。ただし、GPT-4には及びません。私たちの研究は、人間またはより高度なAIモデルによって生成される段階的な説明から学ぶことが、モデルの能力とスキルを向上させるための有望な方向であることを示しています。
Introduction
13億パラメータのinstruction-tuned modelであるVicuna [9](ベースとしてLLAMA-13B [10]を使用)は、OpenLLM3やChatArena4のリーダーボードでのパフォーマンスなどから、そのファミリーの中で最も優れたモデルの一つと広く認識されています。
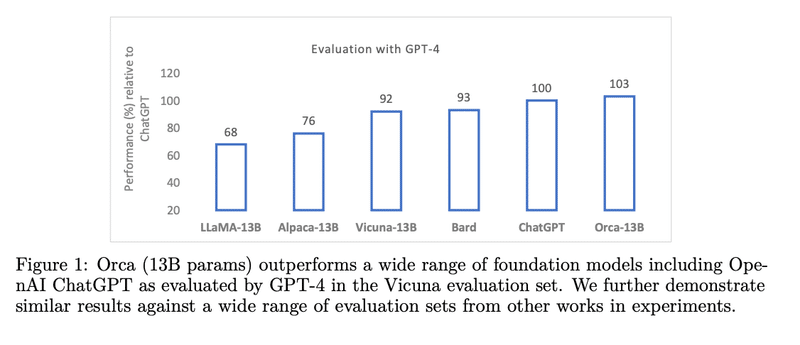
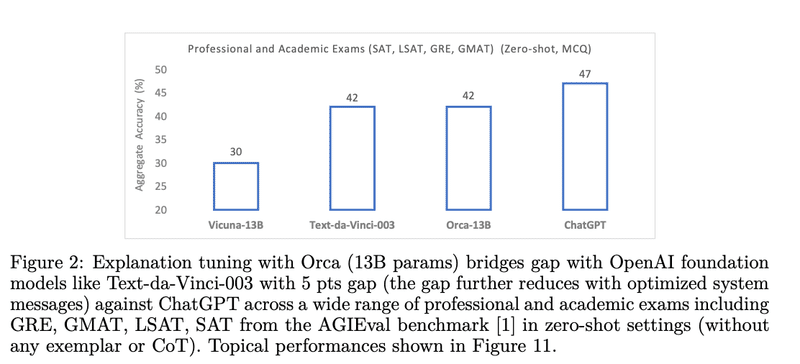
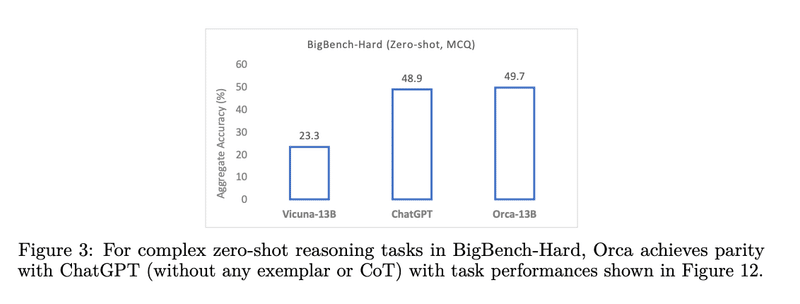
図1に示すように、GPT-4を判断基準として使用するという広く使用されている評価方法では、VicunaはChatGPTの品質を92%保持していると示唆されています。しかし、人間のラベルに対する推論ベンチマークでより厳密な評価を行うと、Vicunaは専門的な学術試験でChatGPTの品質を64%しか保持していないことがわかります(図2参照)、そしてBigBench-hard [11]のような複雑なベンチマークではChatGPTの品質を48%しか保持していません(図3参照)5。
この不一致は、小さなLLMとの既存の評価プロトコルの限界を強調するだけでなく、推論と理解能力におけるその顕著な遅れを明らかにしています。本質的に、これらのモデルは雄弁かもしれませんが、必ずしも堅牢な推論スキルを持っているわけではないかもしれません。本研究では、これらのギャップの背後にあるいくつかの理由を議論し、それらに対処するための戦略を提案します。
従来の方法の問題点
タスクの多様性が限られている:Self-Instructプロセスは、LFMに新しい指示を生成させるための初期のプロンプトを使用します。しかし、生成されたクエリは多様性と複雑さに制限がある可能性があります。
タスクの多様性とデータのスケーリング:ShareGPTの人間が寄与した会話は貴重なデータ源ですが、制限もあります。これらは創造的なコンテンツ生成と情報探求のクエリを他のタスクよりも優先する傾向があります。したがって、このような自然な会話で訓練されたモデルは、スタイルを捉えることができますが、LFMの推論プロセスは捉えられません。
限定的な模倣信号:既存の方法は、教師モデルによって生成された⟨クエリ、応答⟩のペアから学習する模倣学習に依存しています。しかし、これは教師の推論プロセスを追跡するための信号が限定的であることを意味します。
評価:小規模モデルのLFMに対する指示チューニングの先行研究は、評価プロトコルが大幅に制限されています。これらはしばしば、GPT-4による自動評価に依存しています。しかし、このアプローチにはいくつかの欠点があります。たとえば、テストセットのサイズが小さい(Vicunaでは80の指示、WizardLMでは218の指示)、GPT-4が判断者としてのバイアスがあるなどです。
この研究の主要な貢献:
説明チューニング:私たちは、教師が応答を生成する際の推論プロセスを説明するGPT-4からの詳細な応答を、⟨クエリ、応答⟩のペアに追加します。これにより、学習者に追加の学習信号が提供されます。私たちは、システム指示(例えば、「5歳の子供に説明するように」とか、「ステップバイステップで考えて、あなたの応答を正当化してください」など)を利用して、このような説明を引き出します。これは、通常の指示チューニングとは対照的で、通常の指示チューニングは、プロンプトとLFMの応答のみを学習に使用し、LFMの「思考」プロセスを模倣する機会をほとんど提供しません。
タスクと指示のスケーリング:私たちは、Flan 2022 Collection [19]を利用します。これは、タスクと指示の広範な公開コレクションを提供します。特に、私たちは、高品質のテンプレート、高度なフォーマットパターン、データ拡張を補完したFLANv2を使用します。FLANには数千万の指示が含まれていますが、私たちは、タスクコレクションから選択的にサンプリングして、タスクの多様なミックスを形成し、それをさらにサブサンプリングして複雑なプロンプトを生成します。これらのプロンプトは、ChatGPTやGPT-4のようなLFMにクエリを送るために使用され、豊かで多様な訓練セットを作成します。私たちは500万のChatGPT応答を収集し、そのうち100万をさらにサンプリングしてGPT-4の応答を取得します。私たちは、ChatGPTが教師アシスタントとしてどのように進行学習に役立つかを示します。
評価:私たちは、Orcaの生成能力、推論能力、理解能力を、以下の範囲の設定で評価します:(i) Vicuna、WizardLM、そして素晴らしいプロンプトコレクションからの既存の評価セットでのGPT-4による自動評価。(ii) Big-Bench Hard [4]やTruthfulQA [20]などの学術的なベンチマーク。(iii) AGIEval [1]からのSAT、LSAT、GRE、GMATなどのプロフェッショナルおよびアカデミックな試験。(iv) ToxiGen [21]を用いた安全性評価で、異なるマイノリティグループに対する有害な言語生成とヘイトスピーチ検出をテストします。
最後に、OpenAI LFMsのChatGPTとGPT-4、そして指示調整された小型モデルであるVicunaと比較して、Orcaの生成能力と推論能力をケーススタディで示します。
この記事が気に入ったらサポートをしてみませんか?