ERA5の気象データを可視化する①~折れ線グラフ~

先日、屋外の環境を測るために以下のようなものを作成しました。
測定データされたがどのくらい妥当なのかを確認するために、比較対象として「ERA5」という衛星データを取得してみました。
ERA5
ERA5は、ヨーロッパ中期予報センター(ECMWF)によって開発された気象データセットです。ERA5は、大気、地表、海洋に関する広範な気象情報を提供するものです。
ERA5は、高解像度で空間的にも時間的にも詳細な気象データを提供し、大気圏の状態、風、気温、湿度、降水量など、さまざまな情報を含んでいます。
時間毎データを取得する
以下から、各種気象データを取得します。
1940 年から現在までの単一レベルの ERA5 時間別データ
ダウンロードに時間がかかります。
1940 年から現在までの圧力レベルに関する ERA5 時間別データ
垂直方向の圧力レベルごとにデータが格納されています。地表付近のデータを取得する場合は「1000hPa」を選択します。こちらもダウンロードに時間がかかります。
各データを取得するための変数の値は以下が参考になります。
https://confluence.ecmwf.int/display/CKB/ERA5%3A+data+documentation
CDS APIの使用方法
ERA5関連のデータをダウンロードする際、事前にCDS APIの設定を行っておく必要があります。以下のページを参考に設定しておいてください。
データを取得するPythonコード
データ抽出期間の日付とデータ抽出の地名を入力する。
時間毎の気温、相対湿度、気圧、風速、降水量、全天日射量を取得する。
取得した気象データはそれぞれCSVファイルとして出力する。
今回は、2023年1月1〜10月31日の自宅付近の環境データを一時間おきに取得してみます(下記コードでは、データ取得地点を「東京都」に変更してあります)。
import cdsapi
import xarray as xr
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import csv
import os
from datetime import date, datetime, timedelta
from geopy.geocoders import Nominatim
################################################################################
# 設定値
################################################################################
# データ抽出期間
dt1 = datetime(2023, 10, 1, 0, 0, 0)
dt2 = datetime(2023, 10, 7, 0, 0, 0)
# データ抽出地点
address = '東京都'
################################################################################
# データ抽出期間を補正する関数
################################################################################
def correct_dt(shortname, dt1, dt2):
# ディレクトリを作成する
if not os.path.exists('./csv_'+str(shortname)):
os.makedirs('./csv_'+str(shortname))
path = './csv_'+str(shortname)
filelist = []
files = os.listdir(path)
for filename in files:
if os.path.isfile(os.path.join(path, filename)):
filelist.append(filename)
# データ取得開始日時
if len(filelist) == 0:
start = 'ERA5_'+str(format(dt1.year, '04'))+'-'+str(format(dt1.month, '02'))+'-'+str(format(dt1.day, '02'))+'T'+str(format(dt1.hour, '02'))+'_00_00_'+str(shortname)+'.csv'
else:
start = max(filelist)
str_d1 = str(start[5:9])+str(start[10:12])+str(start[13:15])+str(start[16:18])
# データ取得終了日時
if datetime.now() - timedelta(7) > dt2:
end = dt2
else:
end = datetime.now() - timedelta(7)
str_d2 = end.strftime('%Y%m%d%H')
# データ抽出期間を設定
dt1 = datetime(int(str_d1[:4]), int(str_d1[4:6]), int(str_d1[6:8]), int(str_d1[8:]), 0, 0)
dt2 = datetime(int(str_d2[:4]), int(str_d2[4:6]), int(str_d2[6:8]), int(str_d2[8:]), 0, 0)
return (dt1, dt2)
################################################################################
# 地名から緯度、経度を取得する関数
################################################################################
def get_lat_lon(address):
geolocator = Nominatim(user_agent="geo_locator")
location = geolocator.geocode(address)
if location:
return (location.latitude, location.longitude)
else:
return None
################################################################################
# CSVファイルを生成する関数
################################################################################
def gen_csv(shortname, time, value):
with open('./csv_'+str(shortname)+'/ERA5_'+str(time[:10])+'T'+str(time[11:13])+'_00_00_'+str(shortname)+'.csv', mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerow([str(time), str(value)])
################################################################################
# 「ERA5 hourly data on single levels from 1940 to present」からデータを抽出する関数
# https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-single-levels
################################################################################
def reanalysis_era5_single_levels(name, shortname, lon, lat, dt1, dt2):
# データ抽出期間を補正
period = correct_dt(shortname, dt1, dt2)
dt1 = period[0]
dt2 = period[1]
print(f'{shortname}: {dt1} - {dt2} ({lon}, {lat})')
dt = dt1
time = []
value = []
while dt <= dt2:
print(dt)
c.retrieve(
'reanalysis-era5-single-levels',
{
'product_type': 'reanalysis',
'variable': str(name),
'year': str(dt.year),
'month': str(dt.month),
'day': str(dt.day),
'time': str(dt.time()),
'format': 'netcdf'
},
'download.nc')
if lon < 0:
lon = 360 + lon
data_array = xr.open_dataset('download.nc')
data = data_array.sel(longitude=lon, latitude=lat, time=dt, method='nearest')
time.append(dt)
value.append(data[str(shortname)].values)
gen_csv(str(shortname), str(dt), data[str(shortname)].values)
dt += delta
################################################################################
# 「ERA5 hourly data on pressure levels from 1940 to present」からデータを抽出する関数
# https://cds.climate.copernicus.eu/cdsapp#!/dataset/reanalysis-era5-pressure-levels
################################################################################
def reanalysis_era5_pressure_levels(name, shortname, lon, lat, lev, dt1, dt2):
# データ抽出期間を補正
period = correct_dt(shortname, dt1, dt2)
dt1 = period[0]
dt2 = period[1]
print(f'{shortname}: {dt1} - {dt2} ({lon}, {lat})')
dt = dt1
time = []
value = []
while dt <= dt2:
print(dt)
c.retrieve(
'reanalysis-era5-pressure-levels',
{
'product_type': 'reanalysis',
'variable': str(name),
'year': str(dt.year),
'month': str(dt.month),
'day': str(dt.day),
'time': str(dt.time()),
'level': int(lev),
'format': 'netcdf'
},
'download.nc')
if lon < 0:
lon = 360 + lon
data_array = xr.open_dataset('download.nc')
data = data_array.sel(longitude=lon, latitude=lat, time=dt, method='nearest')
time.append(dt)
value.append(data[str(shortname)].values)
gen_csv(str(shortname), str(dt), data[str(shortname)].values)
dt += delta
################################################################################
# 変数
################################################################################
# 緯度、経度
coordinates = get_lat_lon(address)
lat = coordinates[0]
lon = coordinates[1]
# 圧力レベル
lev = 1000
# 時間間隔
delta = timedelta(hours=1)
# CDS API
c = cdsapi.Client()
################################################################################
# 各データをダウンロードしてCSVファイルを生成
################################################################################
#-------------------------------------------------------------------------------
# ERA5 hourly data on pressure levels from 1940 to present
#-------------------------------------------------------------------------------
# 気温 (K)
reanalysis_era5_pressure_levels('temperature', 't', lon, lat, lev, dt1, dt2)
# 相対湿度 (%RH)
reanalysis_era5_pressure_levels('relative_humidity', 'r', lon, lat, lev, dt1, dt2)
#-------------------------------------------------------------------------------
# ERA5 hourly data on single levels from 1940 to present
#-------------------------------------------------------------------------------
# 気圧 (Pa)
reanalysis_era5_single_levels('surface_pressure', 'sp', lon, lat, dt1, dt2)
# 風速 (m/s)
reanalysis_era5_single_levels('10m_u_component_of_wind', 'u10', lon, lat, dt1, dt2)
reanalysis_era5_single_levels('10m_v_component_of_wind', 'v10', lon, lat, dt1, dt2)
# 降水量 (m/h)
reanalysis_era5_single_levels('convective_precipitation', 'cp', lon, lat, dt1, dt2)
# 全天日射量 (J/m2)
reanalysis_era5_single_levels('surface_solar_radiation_downwards', 'ssrd', lon, lat, dt1, dt2)取得したデータを可視化するPythonコード
各データごとに取得したCSVファイルを結合する。
各データごとに結合したCSVファイルから、可視化したい物理量ごとのデータフレームを作成する。
各データフレームを時系列にプロットしたグラフをPNGファイルとして保存する。
import os
import pandas as pd
import csv
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import numpy as np
import math
################################################################################
# CSVファイルを結合する関数
################################################################################
def combine_csv(shortname):
# 生成されたCSVファイルを名前昇順で並び替える
path = './csv_'+str(shortname)
csv_files = [f for f in os.listdir(path) if f.endswith('.csv')]
csv_files.sort()
# データを結合したものをCSVファイルとして出力する
result = []
for file in csv_files[:]:
df = pd.read_csv(os.path.join(path, file))
result.append([df.columns[0], df.columns[1]])
with open(str(shortname)+'.csv', mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerows(result)
################################################################################
# 気温 (degC)
################################################################################
# 元データの「短い名前」
shortname = 't'
# CSVファイルを結合する
combine_csv(shortname)
# 結合したCSVファイルを読み込む
df = pd.read_csv(str(shortname)+'.csv', names=['datetime', 'value'])
df['datetime'] = pd.to_datetime(df['datetime'])
df['value'] = df['value'].astype(float)
datetime = df['datetime']
value = df['value']
# データを編集する
value_adj = []
for i in range(len(datetime)):
value_adj.append(value[i] - 273.15)
df_temperature = pd.concat([datetime, pd.Series(value_adj)], axis=1)
df_temperature.columns = ['datetime', 'temperature']
# グラフを生成する
fig, ax = plt.subplots(figsize=(12, 6))
ax.plot(datetime, value_adj)
plt.ylim(-50, 50)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax.xaxis.set_major_locator(mdates.DayLocator())
plt.xticks(rotation=30)
plt.ylabel('Temperature (degC)')
plt.savefig('temperature.png')
plt.show()
################################################################################
# 相対湿度 (%RH)
################################################################################
# 元データの「短い名前」
shortname = 'r'
# CSVファイルを結合する
combine_csv(shortname)
# 結合したCSVファイルを読み込む
df = pd.read_csv(str(shortname)+'.csv', names=['datetime', 'value'])
df['datetime'] = pd.to_datetime(df['datetime'])
df['value'] = df['value'].astype(float)
datetime = df['datetime']
value = df['value']
# データを編集する
value_adj = []
for i in range(len(datetime)):
value_adj.append(value[i])
df_relative_humidity = pd.concat([datetime, pd.Series(value_adj)], axis=1)
df_relative_humidity.columns = ['datetime', 'relative_humidity']
# グラフを生成する
fig, ax = plt.subplots(figsize=(12, 6))
ax.plot(datetime, value_adj)
plt.ylim(0, 100)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax.xaxis.set_major_locator(mdates.DayLocator())
plt.xticks(rotation=30)
plt.ylabel('Relative Humidity (%RH)')
plt.savefig('relative_humidity.png')
plt.show()
################################################################################
# 気圧 (hPa)
################################################################################
# 元データの「短い名前」
shortname = 'sp'
# CSVファイルを結合する
combine_csv(shortname)
# 結合したCSVファイルを読み込む
df = pd.read_csv(str(shortname)+'.csv', names=['datetime', 'value'])
df['datetime'] = pd.to_datetime(df['datetime'])
df['value'] = df['value'].astype(float)
datetime = df['datetime']
value = df['value']
# データを編集する
value_adj = []
for i in range(len(datetime)):
value_adj.append(value[i] / 100)
df_pressure = pd.concat([datetime, pd.Series(value_adj)], axis=1)
df_pressure.columns = ['datetime', 'pressure']
# グラフを生成する
fig, ax = plt.subplots(figsize=(12, 6))
ax.plot(datetime, value_adj)
plt.ylim(900, 1100)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax.xaxis.set_major_locator(mdates.DayLocator())
plt.xticks(rotation=30)
plt.ylabel('Pressure (hPa)')
plt.savefig('pressure.png')
plt.show()
################################################################################
# 風速 (m/s)
################################################################################
# 元データの「短い名前」
shortname1 = 'u10'
shortname2 = 'v10'
# CSVファイルを結合する
combine_csv(shortname1)
combine_csv(shortname2)
# 結合したCSVファイルを読み込む
df1 = pd.read_csv(str(shortname1)+'.csv', names=['datetime', 'value1'])
df2 = pd.read_csv(str(shortname2)+'.csv', names=['datetime', 'value2'])
df = pd.merge(df1, df2, on='datetime')
df['datetime'] = pd.to_datetime(df['datetime'])
df['value1'] = df['value1'].astype(float)
df['value2'] = df['value2'].astype(float)
datetime = df['datetime']
value1 = df['value1']
value2 = df['value2']
# データを編集する
value_adj = []
for i in range(len(datetime)):
value_adj.append((value1[i]**2 + value1[i]**2)**0.5)
df_wind_speed = pd.concat([datetime, pd.Series(value_adj)], axis=1)
df_wind_speed.columns = ['datetime', 'wind_speed']
# グラフを生成する
fig, ax = plt.subplots(figsize=(12, 6))
ax.plot(datetime, value_adj)
plt.ylim(0, 30)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax.xaxis.set_major_locator(mdates.DayLocator())
plt.xticks(rotation=30)
plt.ylabel('Wind Speed (m/s)')
plt.savefig('wind_speed.png')
plt.show()
################################################################################
# 降水量 (mm/h)
################################################################################
# 元データの「短い名前」
shortname = 'cp'
# CSVファイルを結合する
combine_csv(shortname)
# 結合したCSVファイルを読み込む
df = pd.read_csv(str(shortname)+'.csv', names=['datetime', 'value'])
df['datetime'] = pd.to_datetime(df['datetime'])
df['value'] = df['value'].astype(float)
datetime = df['datetime']
value = df['value']
# データを編集する
value_adj = []
for i in range(len(datetime)):
value_adj.append(value[i] * 1000)
df_precipitation = pd.concat([datetime, pd.Series(value_adj)], axis=1)
df_precipitation.columns = ['datetime', 'precipitation']
# グラフを生成する
fig, ax = plt.subplots(figsize=(12, 6))
ax.plot(datetime, value_adj)
plt.ylim(0, 30)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax.xaxis.set_major_locator(mdates.DayLocator())
plt.xticks(rotation=30)
plt.ylabel('Precipitation (mm/h)')
plt.savefig('precipitation.png')
plt.show()
################################################################################
# 全天日射量 (W/m2)
################################################################################
# 元データの「短い名前」
shortname = 'ssrd'
# CSVファイルを結合する
combine_csv(shortname)
# 結合したCSVファイルを読み込む
df = pd.read_csv(str(shortname)+'.csv', names=['datetime', 'value'])
df['datetime'] = pd.to_datetime(df['datetime'])
df['value'] = df['value'].astype(float)
datetime = df['datetime']
value = df['value']
# データを編集する
value_adj = []
for i in range(len(datetime)):
value_adj.append(value[i]/3600)
df_ghi = pd.concat([datetime, pd.Series(value_adj)], axis=1)
df_ghi.columns = ['datetime', 'ghi']
# グラフを生成する
fig, ax = plt.subplots(figsize=(12, 6))
ax.plot(datetime, value_adj)
plt.ylim(0, 1000)
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
ax.xaxis.set_major_locator(mdates.DayLocator())
plt.xticks(rotation=30)
plt.ylabel('GHI (W/m2)')
plt.savefig('ghi.png')
plt.show()
################################################################################
# 一括表示
################################################################################
# データフレームを統合する
df = df_temperature
#df = pd.merge(df, df_relative_humidity, on='datetime')
df = pd.merge(df, df_pressure, on='datetime')
df = pd.merge(df, df_wind_speed, on='datetime')
df = pd.merge(df, df_precipitation, on='datetime')
df = pd.merge(df, df_ghi, on='datetime')
# グラフを生成する
fig = plt.figure(figsize=(12, 6))
ax1 = fig.subplots()
ax2 = ax1.twinx()
ax1.plot(df['datetime'], df['temperature'], color='r', label='Tmperature (degC)', linewidth=0.5)
ax1.plot(df['datetime'], df['relative_humidity'], color='y', label='Relative Humidity (%RH)', linewidth=0.5)
ax2.plot(df['datetime'], df['pressure'], color='g', label='Pressure (hPa)', linewidth=0.5)
ax1.plot(df['datetime'], df['wind_speed'], color='c', label='Wind Speed (m/s)', linewidth=0.5)
ax1.plot(df['datetime'], df['precipitation'], color='b', label='Precipitation (mm/h)', linewidth=0.5)
ax2.plot(df['datetime'], df['ghi'], color='m', label='GHI (W/m2)', linewidth=0.5)
ax1.set_ylim(0, 100)
ax2.set_ylim(0, 1200)
ax1.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
#ax1.xaxis.set_major_locator(mdates.DayLocator())
#ax1.xaxis.set_major_locator(mdates.WeekdayLocator(byweekday=mdates.SU))
ax1.xaxis.set_major_locator(mdates.MonthLocator())
fig.autofmt_xdate(rotation=30)
ax1.set_ylabel('Tmperature, Relative Humidity, Wind Speed, Precipitation')
ax2.set_ylabel('Pressure, GHI')
lines_1, labels_1 = ax1.get_legend_handles_labels()
lines_2, labels_2 = ax2.get_legend_handles_labels()
lines = lines_1 + lines_2
labels = labels_1 + labels_2
ax1.legend(lines, labels, loc='upper center', bbox_to_anchor=(0.5, 1.15), ncol=3)
plt.savefig('total.png')
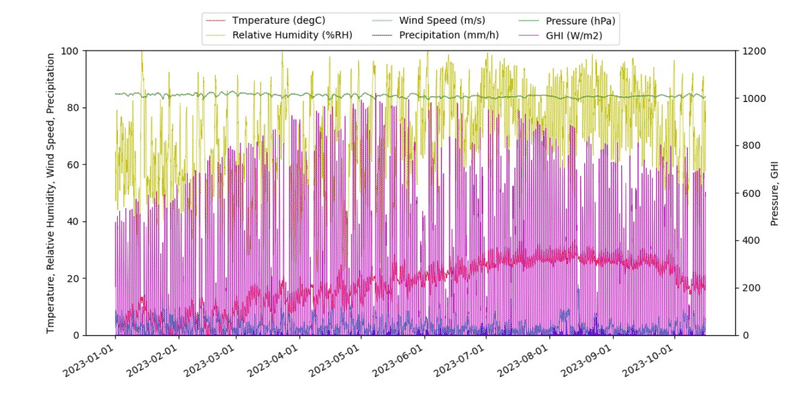
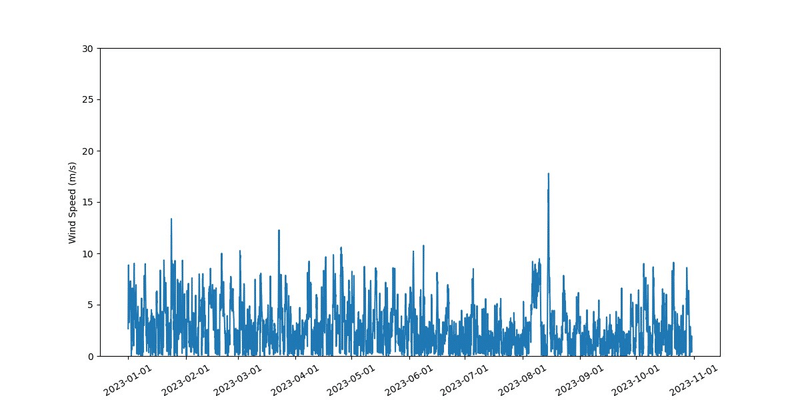
plt.show()生成されたグラフ
以下のようなグラフが得られました。
気温 (degC)

相対湿度 (%RH)

気圧 (hPa)

風速 (m/s)
降水量 (mm/h)

全天日射量 (W/m2)

一括表示

まとめ
とにかくダウンロードに時間がかかるデメリットはあるものの、日時と地名を指定するだけで、市販のセンサでは測定の大変な、風速、降水量、日射量についても取得することができました。これらのデータから、体感温度や日射時間など、様々な指標に加工することもできそうですね。
他にもいろいろなデータを取得することができますので、よろしければ試してみてください。
この記事が気に入ったらサポートをしてみませんか?