note でエクスポートしたXMLをPythonで読みやすくしたい(その1)

前回、note の記事をエクスポートできるというお話しをしました。
note でエクスポートしたデータはXMLファイルであるためそのままでは読みにくい。なので「もうちょっとばかりよみやすくしたいなぁ」ということも書きました。PythonのチュートリアルにXMLファイルを扱うものがあったので参考にしつつ何かしていこうかと思います。
と言ってもゴールが見えているわけではありません。欲だけは果てしなく高く、『noteエクスポートビューワ』でもできればいいかもしれないけど、まぁ、私のことだから途中で投げ出すやもしれません。ただ、Pythonについては未だ勉強中であるわけで、途中で投げ出したとしても少しでも勉強できれば、それはそれでよきかなとも思います。
さて。
始めましょう。
しかし、いったい何をすればいいのでしょうか。
以前にやったPythonのチュートリアルはこちらです。
このチュートリアルによると、まずはこれをインポートしています。
xml.etree.ElementTree
これにならって「ElementTree」をインポートしましょう。
import xml.etree.ElementTree as etree
これによって、「etree」というシンボルを使ってXMLファイルをアクセスすることができます。
先のチュートリアルでは、次の行で、XMLのデータを読み込んでいます。
tree = etree.fromstring(dinner_recipe)
こうすることで、「tree」の関数やデータを使ってXMLにアクセスすることができます。ただこのコードの引数である「dinner_recip」の型は文字列です。今回はXMLファイルがあるので、できればファイルから直接読み込みたい。それはできるでしょうか。
「ElementTree」で、いったい、何ができるんだろう。
ちなみに、「ElementTree」に関するPythonドキュメントはこちらです。
幸い、このドキュメントの初めの方に次のようなサンプルプログラムがありました。
import xml.etree.ElementTree as ET
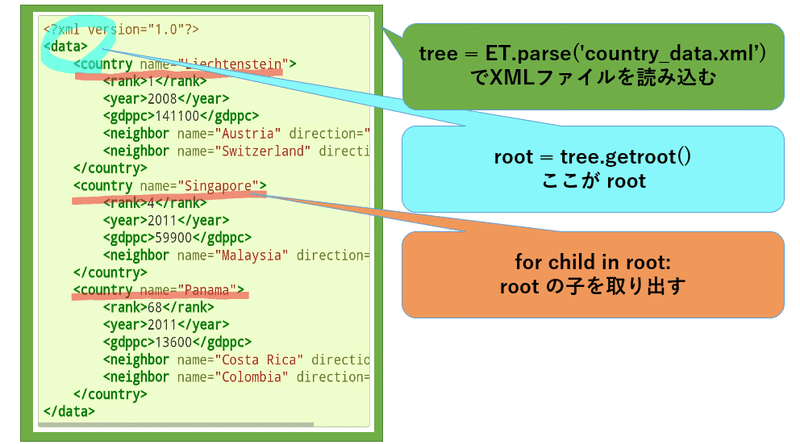
tree = ET.parse('country_data.xml')
root = tree.getroot()これを真似てみます。
インポートのシンボルがここでは「ET」になっています。前のサンプルでは「etree」でした。どちらでもいいんですが、「etree」は、ちょっと、
「xml.etree.ElementTree」の一部とかぶるので「ET」にします。
また、このサンプルコードのXMLファイルのファイル名は「'country_data.xml'」になっています。
note からエクスポートしたファイル名はもちろんこれとは違う。だけど、まずはサンプルコードのXMLデータで試してみます。こちらのXMLの方が単純ですし。このサンプルコードで上手くいったらnoteのエクスポートファイルにチャレンジします。
そこで、次のファイルを用意しておきます。
'country_data.xml'
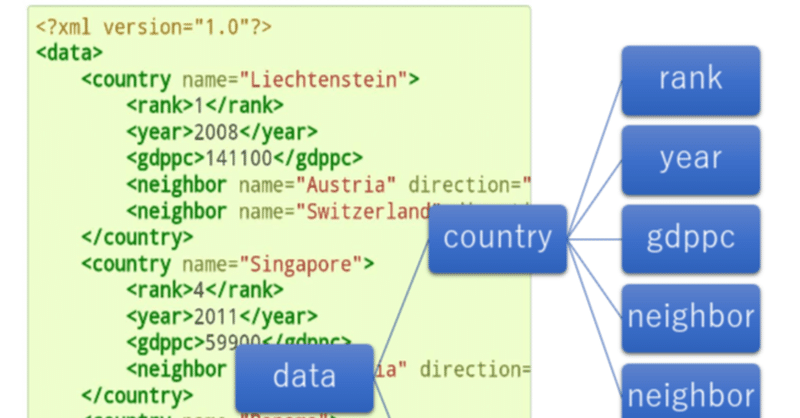
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank>1</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank>4</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank>68</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>Pythonコードは次のファイルへ。
xml_test.py
import xml.etree.ElementTree as ET
tree = ET.parse('country_data.xml')
root = tree.getroot()「xml_test.py」の「test」は暫定的なシンボルです。
コードが出来上がってきたら、もう一度きちんとシンボルを考えましょう。
関数「parse」は「ElementTree」が提供する関数で、XMLの書式を分析します。XMLファイルを分析して木構造でデータを把握できるようにしてくれます。
木構造なのでシンボルは「tree」。
木構造というのは、例えば、上記のXMLファイル
'country_data.xml'
だったらこんな感じになります。
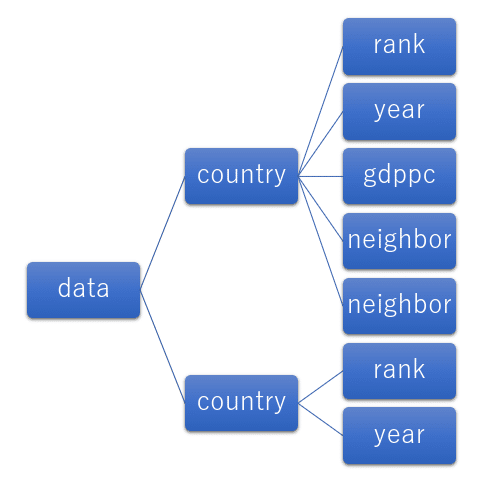
木のように枝葉を広げていくので「木構造」と呼ばれます。
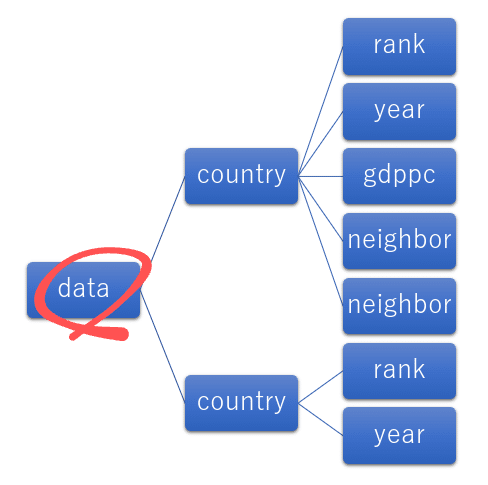
「tree.getroot()」は、その「木構造」の「root(ルート)」を取り出す。
「root」というのは「根」。
ココになります。
そうしてできたコードを実行してみます。
~/python $ python xml_test.py
~/python $
画面に出力するコードを何も書いてません。
なので、何も見えない(笑)。
「root」って、何だろう。
>>> import xml.etree.ElementTree as ET
>>> tree = ET.parse('country_data.xml')
>>> root = tree.getroot()
>>> root
<Element 'data' at 0x7593689940>
>>>型は「Element」なんだね。
「Element」についてのPythonドキュメントはこちら。
tag、text、tail、attribなどの関数でいろいろ参照できるみたいだけど、rootのタグ<data>にはあまり何も記載されていないので、たいしたものは出力されない。
>>> root.tag
'data'
>>> root.text
'\n '
>>> root.attrib
{}
>>>そして「root」の型「Element」はイテレートできる。
してみると・・・。
>>> for child in root:
... print(child.tag, child.attrib)
country {'name': 'Liechtenstein'}
country {'name': 'Singapore'}
country {'name': 'Panama'}
>>>「child」の型は何かというと。
>>> for child in root:
... print(child)
...
<Element 'country' at 0x75936bd2b0>
<Element 'country' at 0x75936bd490>
<Element 'country' at 0x75936bd620>
>>>「child」の型も「Element」。だとすると、これらの「子」もイテレートで抜き出すことができる、ということかな。
再帰呼出ができたりする。
~/python $ cat xml_test.py
import xml.etree.ElementTree as ET
tree = ET.parse('country_data.xml')
root = tree.getroot()
def show_child(el):
for child in el:
print(child)
show_child(child)
show_child(root)
~/python $ ~/python $ python xml_test.py
<Element 'country' at 0x740cc492b0>
<Element 'rank' at 0x740cc49300>
<Element 'year' at 0x740cc49350>
<Element 'gdppc' at 0x740cc493a0>
<Element 'neighbor' at 0x740cc493f0>
<Element 'neighbor' at 0x740cc49440>
<Element 'country' at 0x740cc49490>
<Element 'rank' at 0x740cc494e0>
<Element 'year' at 0x740cc49530>
<Element 'gdppc' at 0x740cc49580>
<Element 'neighbor' at 0x740cc495d0>
<Element 'country' at 0x740cc49620>
<Element 'rank' at 0x740cc49670>
<Element 'year' at 0x740cc496c0>
<Element 'gdppc' at 0x740cc49710>
<Element 'neighbor' at 0x740cc49760>
<Element 'neighbor' at 0x740cc497b0>
~/python $とりあえず、treeの全てをたどることはできたようだ。
第1ステップはここまで。
以上のことを整理するとこんな感じ。
この記事が気に入ったらサポートをしてみませんか?