続・ドーパミンは本当に報酬予測誤差を表現するか?~ANCCR:因果的連合学習におけるドーパミンの役割~
アイスクリームを食べられると幸せである。また、ヒトはそれを幸せに思い、アイスクリームを食べるためにはどんな手掛かりも見逃さないように進化している。では、私たちは、どのように環境刺激(アイスクリーム屋の到来を告げるベル)と報酬(アイスクリーム)の関係性を学習するのだろうか?
一般的なモデルでは、報酬予測誤差(RPE)を用いた前向きな(将来を見越した)予測が用いられるとされる。脳における実装としては、中脳のドーパミンが得られた報酬と報酬の予測の差である報酬予測誤差を表象することで、古典的条件付けにおいて重要な役割を担うことが示唆されている。このモデルを示唆する代表的な論文を以前紹介した。
本論文は、意義深い結果が得られた際にその原因を因果学習することによって連合学習が起こるという、対立する仮説(ANCCR)を提唱する。この仮説は、報酬が得られた後に手掛かりの記憶を回顧することで、手掛かりと報酬を後ろ向きに対応付けるため、報酬が得られる前に報酬の予測を維持し続ける必要がないという点で決定的に異なる。本論文ではシミュレーションでANCCRが連合学習を説明可能であることを示したのち、それぞれのモデルから異なる活動パターンが予測される中脳ドーパミンのシグナルを計測し、これらの仮説の検証を11個の実験パラダイムを用いて行った。
Jeong, Huijeong, et al. "Mesolimbic dopamine release conveys causal associations." Science 378.6626 (2022): eabq6740.
https://doi.org/10.1126/science.abq6740

Methods
図1では、連合学習を担う既存のTD強化学習モデルと今回提案する因果学習モデルが対比されている。前向きの連合では報酬が手掛かりの後に付随するかが学習されるのに対し、後ろ向きの連合では報酬に手掛かりが先行しているかが学習される(図1A)。よって、手掛かりの後に10%の確率で報酬が与えられるような環境を考えた際に、前向きの連合では手掛かり後の報酬が10%という弱い学習シグナルになるのに対し、後ろ向きの連合では報酬前の手掛かりが100%という強い学習シグナルとなる。

既存の前向きのTD強化学習のモデルでは、動物は前向きの予測を行い、予測に反する報酬が与えられた際に予測の更新が起こるとされる(図1B)。状態やそれを割り当てられた価値に遅延の情報がのり、予測が伝搬する。脳の実装としてはドーパミンが報酬予測誤差をシグナルすると仮定され、それに基づき価値が更新される。
本論文で提案された後ろ向きの因果的学習モデルでは、過去の刺激に基づき後ろ向きに原因が特定され、因果的連合の認知地図が更新される(図1C)。脳の実装としては、ドーパミンが手掛かりが報酬と因果的関係のあり、生存するために覚えておくと有利な原因であるか(ANCCR)を伝搬すると仮定される。

より詳細には、この連合学習は4つのステップからなる(図S2)。まず、刺激の適格度トレースを用いて、報酬に先行する手掛かりの重要性(後ろ向きの連合)が学習される。次に、後ろ向きの連合が手掛かり後の報酬の重要性(前向きの連合)に変換される。そして、前向きの連合と後ろ向きの連合の重み付きの和が閾値を超えるかが計算される。最後に、連合の関係からベイズの法則を用いて因果関係が推測されるという、認知地図の構築が行われる。論文では一貫して前向き連合と後ろ向き連合の対比が行われているが、この手法を見る限り提案手法はそれらを組み合わせた学習則となっており、報酬予測誤差学習の拡張ともいえそうだ。

Results
図2では、TD強化学習モデルで説明できる過去の実験的な知見がANCCRモデルによっても説明できることをシミュレーションによって示している。手掛かりと報酬の連合を学習させると、ANCCRを表現するドーパミンは学習前は報酬に対して応答したのに対し、学習後は手掛かりに応答するようになった。また、報酬を省いた際には負のドーパミン応答が観察された(図2A)。手掛かりAは無報酬を、手掛かりBを報酬と連合させた後に手掛かりA・Bを同時に提示すると報酬を求める行動(リッキング)をとる確率が下がるという行動が再現された(図2D)。報酬時のドーパミンの活動を学習後に抑制すると、報酬を求める行動をとらなくなるという光遺伝学の実験も再現できた(図2G)。

図4では、連合学習におけるドーパミンの応答がTD強化学習におけるRPEよりもANCCRと合致していることを示している。前向きの連合によってのみ、または後ろ向きの連合によってのみドーパミン応答が減少すると考えられる連合学習の実験パラダイムを構築した(図4N)。一度条件付けを学習させた後に報酬の省略を行う(実験4)と、前向き連合ではドーパミン応答が減少するが、後ろ向き連合では報酬が与えられたという条件での刺激の有無は変わらないため、ドーパミン応答は変わらないことが予測される。一方で、刺激とは関係ない報酬を増やす(実験5)と前向き連合ではドーパミン応答は変わらないが、後ろ向き連合では報酬が与えられた際に刺激が与えられた確率が減少しているため、ドーパミン応答は減少すると予測される。実際に、ファイバーフォトメトリーとドーパミンセンサーdLight1.3bを用いて、RPEをシグナルし古典的条件付けに必要といわれているマウスの側坐核(NAcc)のドーパミン放出をイメージングする実験を行った。実験4では、報酬の省略によって行動は急激に変化するが、ドーパミン応答はほぼ変化しないことが分かった(図4J-L)。実験5では、刺激と関連しない報酬を与えることで、刺激に対するドーパミン応答が実験4と比較して有意に減少することが分かった(図4M-P)。

他にもTD強化学習のRPEよりもANCCRと合致していることを示す実験結果として、図3では、予測できない報酬に対するドーパミンの応答を、図5ではトライアルという構造を持たない連合学習のタスクにおけるドーパミン応答を提示している。
図6では、ドーパミン信号の漸進的な逆伝搬が学習中に見られないことを示している。既存モデルと提案モデルの決定的な違いとして、既存モデルでは学習中に報酬のタイミングから手掛かりのタイミングに向けてドーパミン応答が移行していく時間的シフトが予想されるのに対し、提案モデルでは報酬のタイミングでの応答が減少していき、手掛かりのタイミングでの応答が上昇していくという振幅のシフトがみられることが予想されるという違いがある(図6A)。実際に条件付けの実験では、手掛かりに対するドーパミン応答は突然上昇することはなく、学習過程で徐々に上昇していくことが分かった(図6B)。次に、手掛かりAの1.5秒後に手掛かりBが、その1.5秒後に報酬が与えられる連続的条件付けを考える。ここで、RPEモデルでは学習中に手掛かりBへのドーパミン応答が上昇したのち、その応答は下がって逆に手掛かりBへの応答が上昇すると予測されるが、ANCCRモデルではどちらへの応答も上昇し、特に学習終了後の手掛かりBへの応答に差がみられると考えられる(図6C)。実際に実験を行うと、学習初期に2つの手掛かりに対するドーパミン応答に差は見られず、学習後にも手掛かりBへの応答が残存していた(図6D)。
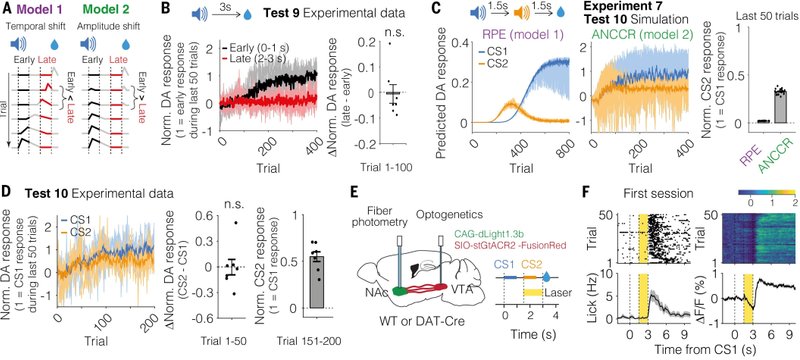
一方で、他の研究グループはドーパミン信号の逆伝搬が学習中に見られたという報告をしている。どちらのグループも腹側線条体のドーパミン放出を観察しているのだが、匂いを手掛かり刺激に使うか、音を刺激に使うかの違いがあり、本論文では音の方が時間解像度が高く正確であると主張している。他方の論文は多角的な対象・手法で記録を行っている点で優れており、どちらが正しいか分からない。
Discussion
本研究では、中脳のドーパミンシグナルは報酬路側誤差シグナルよりも因果的学習のシグナルによって説明できることが示された。さらに同じグループが、別の状況でもANCCRがTD強化学習よりもドーパミンシグナルの活動をよく説明できることを続報として発表している。
ただし、今回は2つのアルゴリズムを対比させるような構図になっているが、一般にRPEの概念とANCCRが相容れないわけではなく、RPEで説明できる実験結果も多数存在する。また、"All models are wrong but some are useful"という言葉があるように、モデルですべての事象を説明することができず、説明度合いは設定したパラメーターやその数に依存する。今回も一見異なるモデルを比較しているようだが、内部では後ろ向き連合と前向き連合の重みづけ和がとられており、結果の解釈には注意が必要である。(前向き連合を含めないでどれほど実験を説明できるかテストするか、フィットしたモデルが前向きと後ろ向きどちらの重みを多く含んでいるかを比較する方が公平な比較なように感じる。)今後他のチームからの独立した研究がどちらのモデルを支持するかによって妥当性が評価されていくのだろう。
また、ANCCRのモデルでは連合学習が連合の因果関係の学習と因果的出来事の間の時間遅れの学習の2つの要素からなると仮定しているが、本研究はどのように時間遅れの学習が行われるかについては示していない。動物は環境内での異なる時間スケールをどのように学習するのか、という謎については最近の活発な研究課題のようで、同じグループや他のグループが異なる角度からアプローチした結果を発表している(研究1、2、3、4)。
ドーパミンシグナルの表象については価値vs報酬予測誤差が主な論点だったが、それとはまったく異なる軸での研究で衝撃を受けた。動物が前向きな連合以外にも後ろ向きの連合を保持し、行動に用いていることは以前から知られていたようだが、それをモデルとして提示し、多数の実験系を用いて徹底的に調べた研究はこれが初だろう。最も調べられているはずのドーパミンですら新しいモデルが提唱されるのは、脳の未開拓っぷりを象徴している。
参考文献
Mesostriatal dopamine is sensitive to specific cue-reward contingencies | bioRxiv
Multi-timescale reinforcement learning in the brain | bioRxiv
Few-shot learning: temporal scaling in behavioral and dopaminergic learning | bioRxiv
Mesolimbic dopamine ramps reflect environmental timescales | bioRxiv
アイスクリームがもたらす幸福感を例にして、人が環境の手掛かりと報酬の関係をどう学習するかを議論する。一般的には、報酬予測誤差(RPE)を用いた学習が行われるが、この研究では因果学習モデル(ANCCR)を提案し、報酬後に手掛かりを回顧することで、報酬の予測を維持せずに学習が可能であることを示している。
サムネイル画像の出典:Mesolimbic dopamine release conveys causal associations | Science