Dictation 採点アプリ開発メモ vol.07

キカガクさんの講義の一環で作る自作アプリに関するメモです。
2020.10.10(土)
前回、講師と相談して教師画像を変えてみることにしました。
一度に色々な要素を変更しすぎて、何が効いているか分からなくなってしまったので、頭の整理をしてから次の作業に取り掛かることにする。
1. いつも勉強している採点結果を教師データ
Labeling は丸のみ
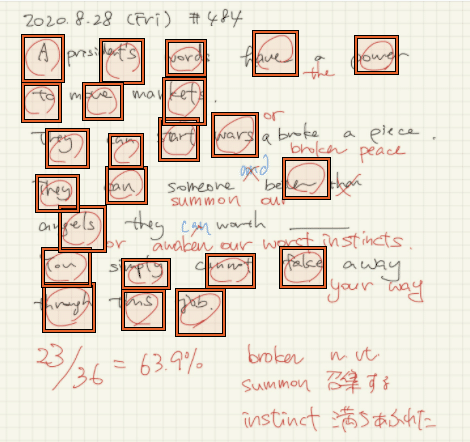
結果はこんな感じ
考察
いきなり全てできる物はできないので少しずつブラッシュアップすることにする。簡単な物で一度通しで作って、それから大きい物にチャレンジする。
また、学習しやすいように赤丸の細いペンから太いペンに変更。採点する時も文字に被せて丸をつけるのではなく、文字の下に丸をつけたらうまくいくのでは?という仮説の元にアプリを作ってみる。
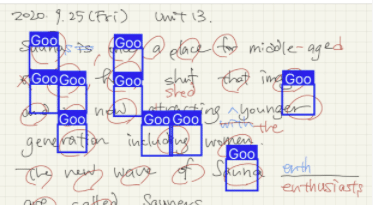
2. 太字の赤丸だけを教師データにする
ラベリングの様子はこんな感じ。50枚。309ラベル。
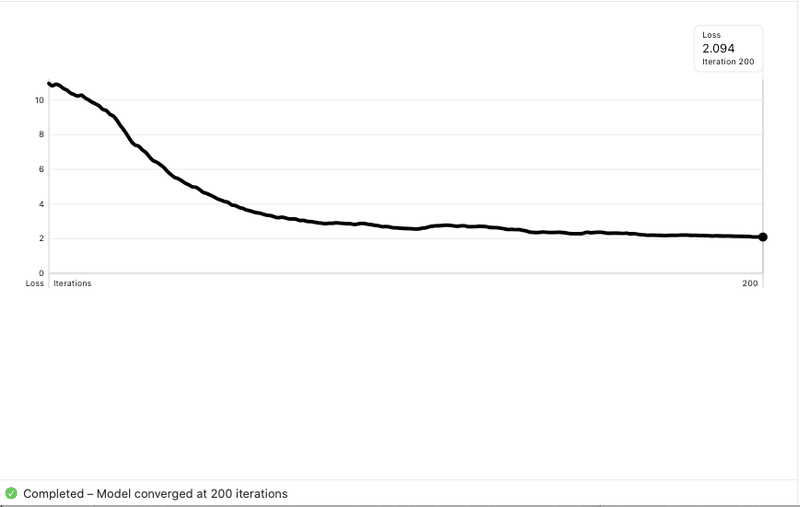
200 iterations。学習時間 45分。
推論結果 IoU値 0.5 で実施。
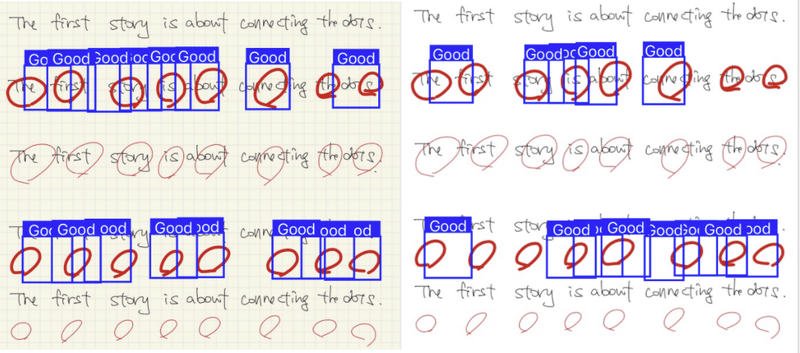
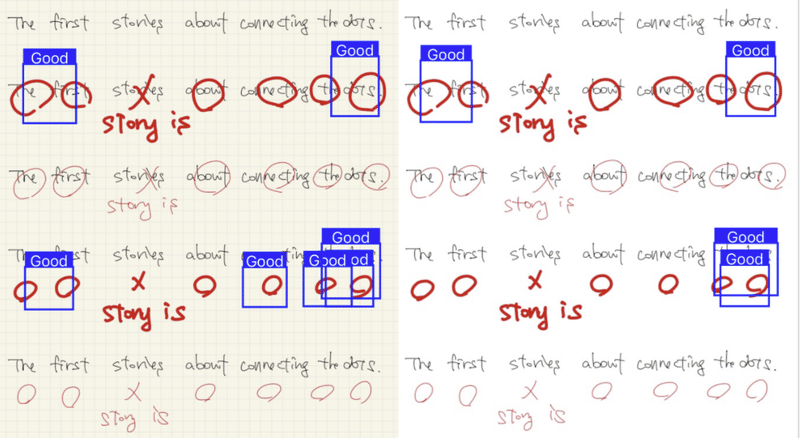
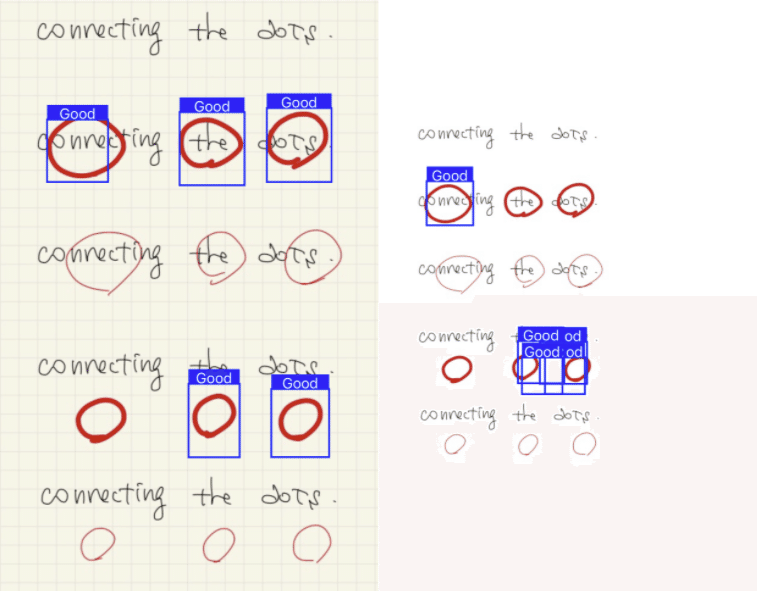
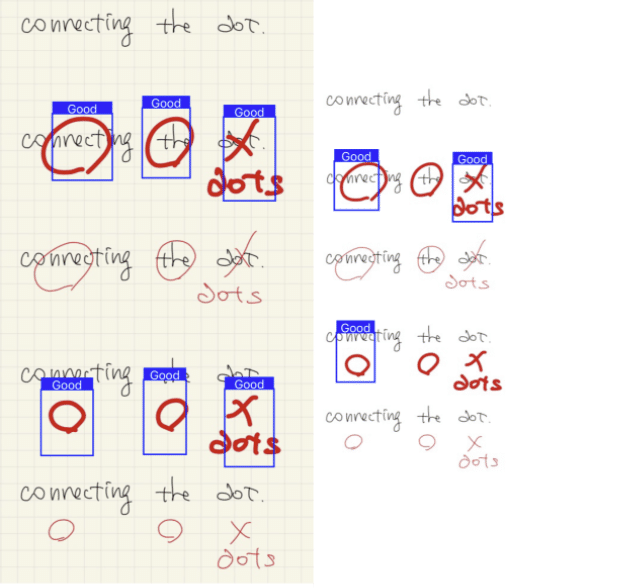
推論結果はグリッドと白紙の2種類で比較してみた。背景をグリッド で学習させたので背景がグリッドの方が認識しているように見える。後半2枚の方が字が大きいせいか認識率が良いように見える。
なお、この時点では赤丸しか学習させていないので、×印も正解として認識している。
考察
丸だけなら認識率は良さそう。グリッドが背景、白色が背景で認識の仕方が若干異なりそう。まだ開発にかけられる時間はあるので、○と×の2種類を認識するモデルを作ってみようと思う。
また、テスト用画像のサイズがグリッドと白色で異なるみたいなので、時間がある時に修正する。
3. 太字の赤丸と×印を教師データにする
ラベリングはこんな感じ。OKとNGでラベリングした。

こちらは2種類あるせいか200 iteration ではあまり認識しない。ので、iteration の数を増やしてみる。その後、画像枚数少ないのでは?等々を感じたので画像枚数を増やし、iteration の数をあげた。
画像 175枚。ラベリング OK 610 / NG 613 、2000 iterations で実施。
学習時間は7時間。寝ている時間に学習させないと仕事ができなくなるくらい時間が必要になってきた。
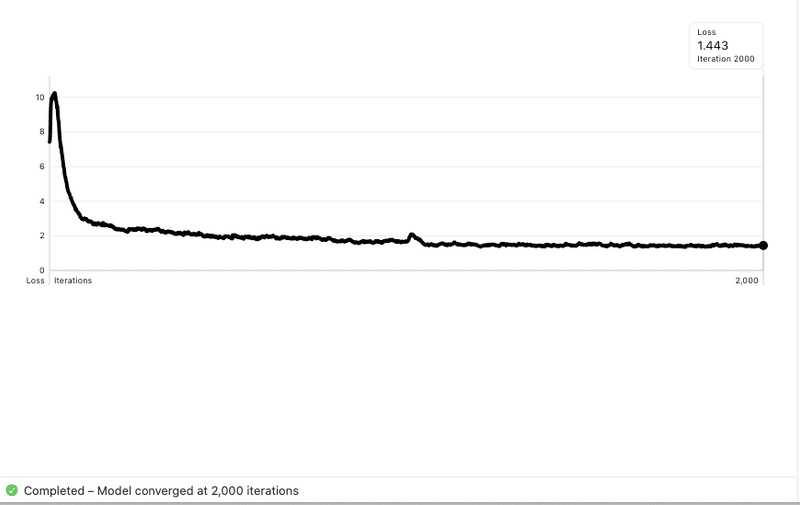
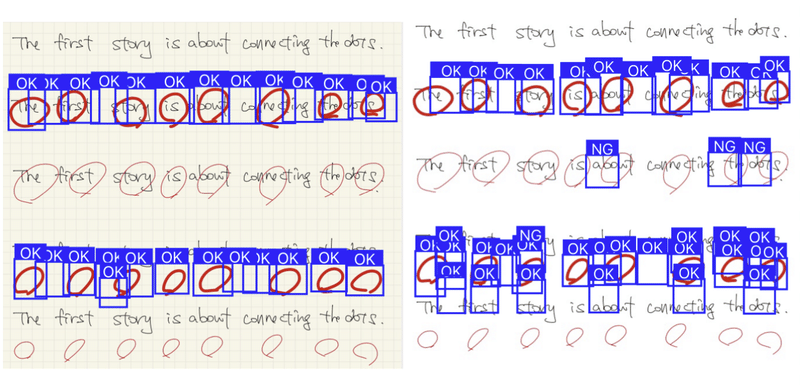
推論結果はこんな感じ
太字の○ / × は何かしらの結果は返している。が、○だけの画像はOKを返すのに、○ / × の混在画像はNGばかりを返してしまう。1, 2枚目。なぜだ。
教師データは白色を背景で学習させたが、背景がグリッドでも概ね認識しそうな雰囲気はある。
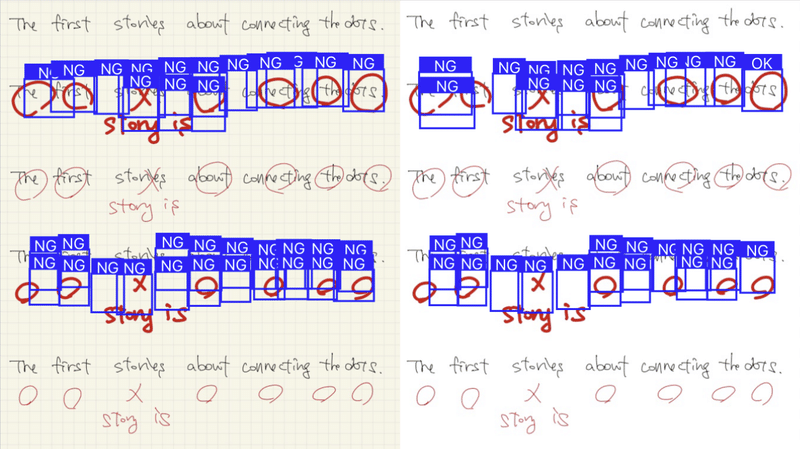
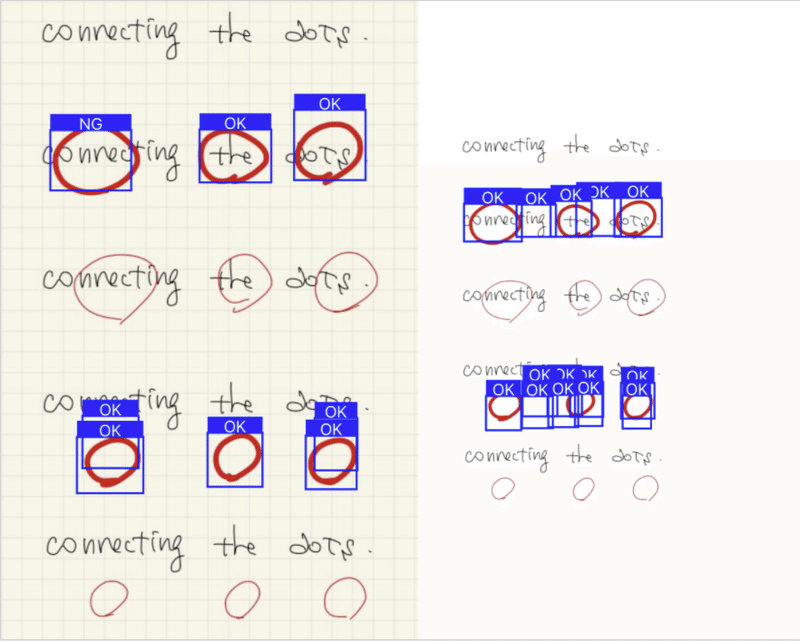
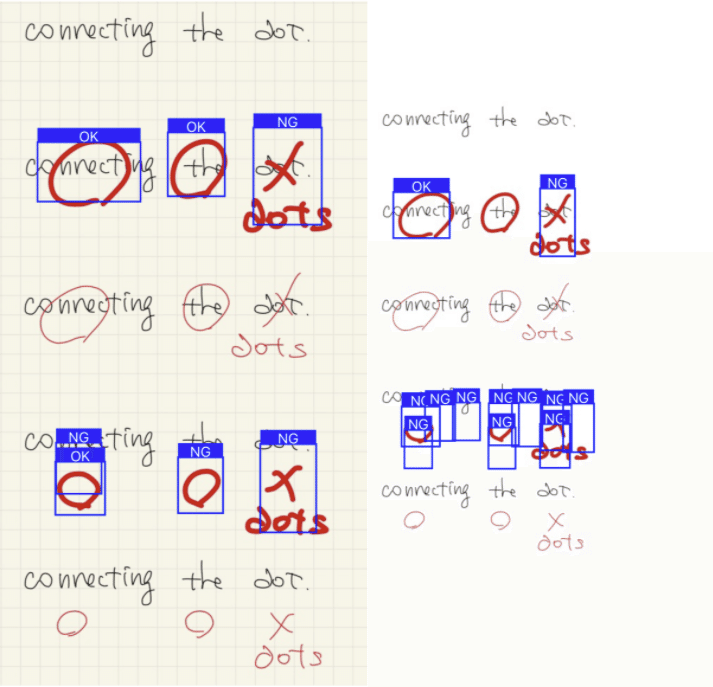
考察
×が一つでもある画像だと、認識率が悪くなっている気がする。そして、背景がグリッドの方が認識率が良い。が、先ほどの考察同様に入力画像の縮尺比が異なるからの可能性があるので統一させて比較する。
アクションアイテム
・テスト用画像(背景グリッド、白色)の画像サイズ、文字サイズを統一させて比較する
・OK / NG の数をカウントして、OK / (OK + NG) = 正解率 を出す
・その後、OK / NG の認識率をあげる方法を見つける
この記事が気に入ったらサポートをしてみませんか?