
Web広告がどのくらい検索量に貢献しているのかPythonを使って重回帰分析に挑戦してみた

挑戦してみた動機
販促施策の全体最適を実現するために各広告の間接的な効果として検索流入へ与える貢献度を可視化したいとずっと思っていました。専門会社に会社に発注を検討するもコストが高く発注できず。また、自分の知識がなさすぎて発注や納品データの検収ができないという課題感もあったため、いっそのこと自分でスキルを習得して実現できないかと試みることにしました。
ちなみに私は、文系出身でプログラミング経験なし、データサイエンス経験なしのド素人です。
参考にした教材
オンライン学習の「Udemy」というサービスの次のコースを受講しました。(基本的にここに書かれている内容は、ここで学んだことをそのまま応用しています。)
【キカガク流】人工知能・機械学習 脱ブラックボックス講座 - 初級編 -
【キカガク流】人工知能・機械学習 脱ブラックボックス講座 - 中級編 -
日本マイクロソフト・Preferred NetworksのAI人材育成トレーナーに任命された株式会社キカガクの代表が講師で、一度専門書で挫折してしまった人をターゲットとしているということもあり人工知能の仕組みや機械学習で必要な数学との結びつきが非常にわかりやすかったです。
ゴール設定とモデル作成手順
下記を変数とした重回帰モデルの作成
- 目的変数(出力変数)を「サービス名での検索流入数」
- 説明変数(入力変数)を「各種広告施策から発生したセッション」
「サービス名での検索流入数」とは、例えば、「メルカリ」とか「ユニクロ」とか具体的なサービス名称での検索でサイトに流入してきた数がどれくらいかという意味です。
ディスプレイ広告とか記事とか様々な広告施策でサイトへの流入を作るのですが、お客さんはすぐに購入するわけではなく、そのサービスについて調べて検討をして最終的に購入することが多いはずです。
そのため、広告で作ったセッションが検索での流入にどれだけ影響いていたのかを可視化することで、各種広告施策の予算配分などが最適化できるのではないかと考え、今回の分析・モデル化を実現してみたいと思いました。
今回の記事では、コースで学習した数学や各コードの意味などはほとんど記載していません。コースで得た知識をもとに実務データを使って自身の業務にどう活かせそうかを試すために分析・モデル作成のアプローチの流れをまとめてみたという内容になります。
(全く知識がない状態からコースで学んだことを元に見様見真似でやってみただけなので、正しいのか全く自信がありません!笑)
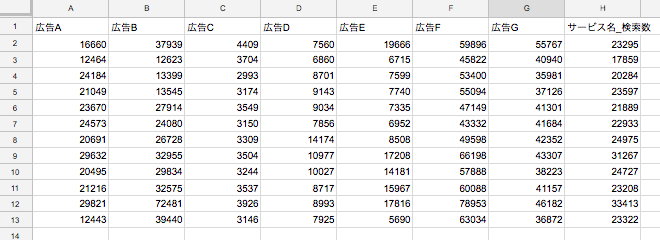
用意したデータ
かなりサンプルが少ないデータですが、直近1年間の月別の広告施策のセッションデータとサービス名での検索流入数をダミーデータとして用意しました。
モデル作成の手順
まずはじめにモデル作成までの全体の流れについてです。
以下の手順でモデルを作成しました。
1:モデルを決める
2:評価関数を決める
3:評価関数を最小化する
1:モデルを決める
前述の通り重回帰モデルを使います。
こういう数式のやつです。
y=a+b1x1+b2x2+b3x3+…+bnxn
2:評価関数を決める
実測値と予測値の二重誤差を求め、誤差を最小化することを目指します。誤差が小さいということは精度が高いということになります。
3:評価関数を最小化する
数式で表すと下記のようになります。
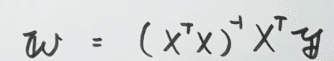
受講してみて文系出身者からすると、かなり難しい数学に取り組んでいるな・・・という印象でしたが、それでもキカガクさんの指導のわかりやすさのおかげでなんとか機械学習に必要な数学のセクションをクリアしました。
ちなみに数学セクションは、テキストでメモが残せないので、このようにノートに手書きで書いて記録しました。

講座では、これらの数式を元にプログラミングをしてモデルを作ることもするのですが、Scikit-learnという最高に便利な機械学習ライブラリを用いることで実際には、数式なしで簡単に重回帰分析をすることができます。
「じゃあ最初から数学はやらなくてもいいのでは・・・」と感じてもしまいますが、裏側の論理を理解していないと何か問題が起きた時に立ち返って解決できないですし、素人としては、実際に一連のプログラミングを経てからライブラリを使うことで、ライブラリのありがたみが身にしみて理解できるので良い経験になりました。
ここからはScikit-learnを使ってのモデル化までを記載します。
pythonによるプログラミングの手順
以下の手順でpythonでモデルを作成し、最後に各広告が検索に与える影響度を示すパラメータ(重み)を確認します。
1. データの読み込み
2. 相関関係の確認→扱う入力変数の決定
3. 入力変数と出力変数の切り分け
4. 訓練データと検証データの分割
5. モデルの学習(パラメータの調整)
6. 検証(予測精度の確認)
7. パラメータ(各入力変数の重み)の値
1. データの読み込み
はじめにpythonでの数値計算を効率的に行うためのnumpyと統計量の可視化などデータ分析に役立つpandasの2つのライブラリをインポートします。
numpyとpandasのインポート
import numpy as np
import pandas as pd
次に用意したcsvデータを読み込みます。
csvデータの読み込み
df = pd.read_csv(' marketing_data.csv')
2. 相関関係の確認→扱う入力変数の決定
各種広告と検索数との相関を相関係数を算出して確認します。
相関係数(corriration)の算出
df.corr()
その結果がこちら
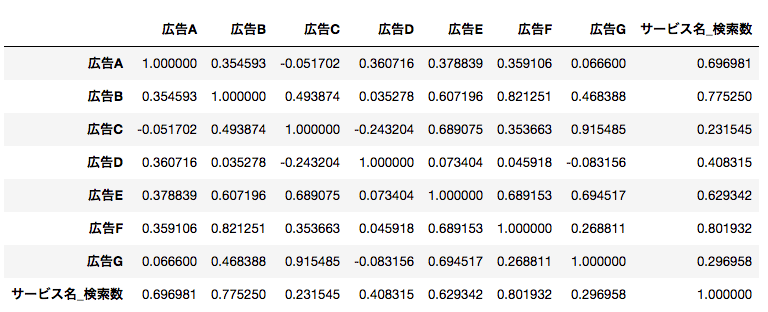
相関係数については、絶対値が
0.7~1.0:強い相関あり
0.4~0.7:相関あり
0.2~0.4:弱い相関あり
0.2以下:相関なし
ということなので今回は「サービス名_検索数」に対して
広告A:強い正の相関あり
広告B:相関あり
広告C:弱い相関あり
広告D:相関あり
広告E:相関あり
広告F:強い相関あり
広告G:弱い相関あり
という結果になりました。今回は「相関あり」、もしくは「強い相関あり」という結果が出たA,B,D,E,Fの5つの広告施策を入力変数にして重回帰モデルを作成することにします。
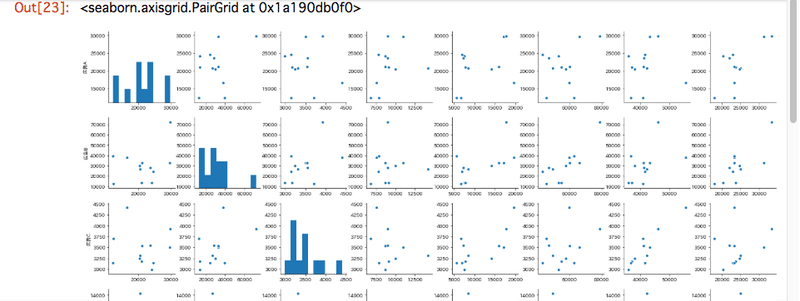
ちなみにpairplot関数を使えばビュジュアライズでき、目視で相関関係も確認できます。
pairplot関数での可視化
sns.pairplot(df)
このように一覧でパッと出てくるのでテンションが上がります!自分って単純だなと思いますが、学習においてワクワクしたり楽しいと感じる瞬間って大事ですよね。
3. 入力変数と出力変数の切り分け
相関係数から今回パラメータに設定することを決めた5つの広告施策に絞ったデータを用意し読み込みます。
データの読み込み
df2 = pd.read_csv('marketing_data_2.csv')
このデータから入力変数と出力変数を切り分けます。
ilocを使い、切り分けを行います。
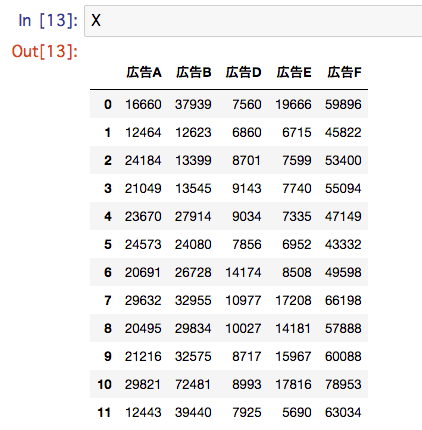
X = df.iloc[:,1:-1]
y = df.iloc[:,-1]
Xとyで切り分けができました。
4. 訓練データ(train)と検証データ(test)の分割
データを訓練用のデータと検証用のデータに分けてモデルを作成します。これはどういう意味があるのかというのがコースの中で受験勉強を例にわかりやすく解説されていました。
例えば、受験勉強用に10年分の過去問を購入したとします。そのとき、10年分で勉強(学習) をし、10年分で実力テスト(検証)を行なった場合、テストの結果(精度)は良くなるかもしれませんが、全ての過去問を一度勉強しているので本番の試験に臨んだ時に新しい問題に対応できる(新しいデータで予測できる)かは心配です。
そこで、前半の5年分(訓練用)で勉強をし、後半の5年分(検証用)で実力テストを行うことで、しっかりと本番にも対応できるように学習しようというのが訓練用データと検証用データに分ける目的になります。つまりこうすることで、より使えるモデルの作成に繋げることができるということなんですね。
ということで、まずデータを訓練用と検証用に分割をします。Scikit-learnにはこの作業もサポートされています。
訓練データ(train)と検証データ(test)の分割
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.4, random_state = 1)
5. モデルの学習(パラメータの調整)
LinearRegression(重回帰分析)をモデルとして使うということを指定し、モデルの学習(パラメータの調整)を行います。
Scikit-learnの中のLinearRegressionを読み込みます。
Scikit-learnの中のLinearRegressionの読み込み
from sklearn.linear_model import LinearRegression
モデルの宣言と学習(パラメータの調整)
model = LinearRegression()
model.fit(X_train, y_train)
6. 検証(予測精度の確認)
予測精度の確認(検証)を決定係数を用いて行います。
決定係数は0~1の間で算出され、1に近いほど予測精度が高いという結果になります。(マイナスになる場合もあるそうです。)
検証(決定係数の計算:訓練データ)
model.score(X_train, y_train)
検証(決定係数の計算:検証データ)
model.score(X_test, y_test)
今回は、
訓練データ:0.95315067595674163
検証データ:0.75743781952894018
と算出されました。
7.パラメータ(各入力変数の重み)の値
最後に作成したモデルのパラメータを確認します。
パラメータの確認
model.coef_
次のように出力されました。
array([ 0.41, 0.04, 0.37, -0.11, 0.23])
左から広告A,B,D,E,Fです。この結果を見ると、広告Aが0.41と最も係数が大きく検索への影響度が大きいと言えそうです。(ただ、Eに関しては負の値になっており、これは入力変数の項目として除外した方が良いということを意味しているのでしょうか?・・・この辺りの知識がまだ不足しているので今後も継続して学習していきたいと考えています。)
最後に
今回は、本当にコースを一度視聴して得た知識をもとに実際の業務データをを使って見様見真似でやってみた。だけです。きっと自分が気づいていないところでいくつもの落とし穴があって自分が実現したいことができていない、そもそもできるものではないのかもしれませんが、今の自分の知識では何がわからないのかもわからない状態なので、これからも実践的な力をつけていけるように頑張っていきたいと思います。
また、今回この講座を学んでデータサイエンスができるようになった訳ではありませんが、実際に手を動かしてモデル作成まで経験をしたことで前提となる基礎知識の習得にはつながったと感じています。
ここで学んだことを糧にさらに文献を読んで知識を深めたり、チャンスがあれば解析業務を外部に発注する際には共通言語として会話ができるように挑戦してみたいと思います。
数学なんてほんと高校以来だなと思いながら楽しく学ぶことができました。高校の時は微分とか一体何が楽しくて学ばなくてはいけないんだと感じていましたが、このように実社会で生きる力になるということをもっと早く知りたかったです(笑)
この記事が気に入ったらサポートをしてみませんか?