TableauをPythonで再現!?お手軽分析ライブラリpygwalkerのすすめ

こんにちは。コグラフ株式会社データアナリティクス事業部のワダと申します。
Pythonでデータを可視化する際は主にmatplotlib,seaborn,plotly等が用いられます。それらを使用してコードを書く前に、気軽にデータを可視化して傾向をつかみたい、分析の方針を立てたいと感じる方はいるのではないでしょうか。
今回はドラッグ&ドロップで簡単にデータ分析・可視化を行うことができるPythonライブラリ「pygwalker」の概要と使い方についてご紹介します。
Google Colaboratory上で簡単に実装できるため、ぜひ実際に試してみてください。
pygwakerの概要
pygwalkerとはjupyter notebook上でpandas(polars/Modin)のデータフレームを可視化できるライブラリです。一度GUIを立ち上げてしまえばTableauのようにドラッグ&ドロップで簡単に可視化・分析を行うことができます。
公式ドキュメントリンク
具体的な実装方法
ライブラリ,データの準備
今回はGoogle Colaboratory(Python 3.10.12)上で実装を行います。
pygwalker をpip installし、他に必要なライブラリもインポートします
!pip install pygwalkerimport pandas as pd
import pygwalker as pyg
import seaborn as sns今回はseabornのデータセット機能を用います。呼び出すのはIrisデータセットです。アヤメの形状の特徴(長さ、幅)に関する4列+品種の合計5列で構成される小さなデータセットです。※参考リンク
#アヤメの品種データセット
iris = sns.load_dataset('iris')
#カラム名を日本語に変更
iris.rename(columns={'sepal_length':'がく片の長さ[cm]', 'sepal_width':'がく片の幅[cm]', 'petal_length':'花びらの長さ[cm]', 'petal_width':'花びらの幅[cm]',
'species':'品種'}, inplace=True)
#dfの表示
iris.head()GUIの呼び出し
pyg.walkを実行するとGUIが立ち上がります。
「Data」「Visualization」「Chat」の3つのタブがあり、「Data」はデータ全体のプレビュー、「Visualization」で分析を行います。「Chat」はGPTを用いてチャット形式で分析を行う機能ですが、今回は割愛します。
gwalker = pyg.walk(iris)
データフレームの中身、分布、構成比はここで確認できます。
データ種の変換(質的⇔量的)も可能です。

分析方法
ここから分析の中身に入ります。
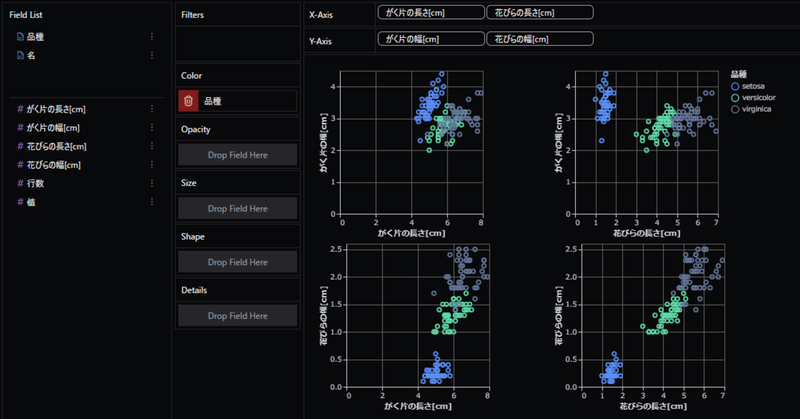
アヤメの種類による各データの分布の違いを見ていきましょう。
①Field listから必要なデータを軸に移動
データフレーム内の各列がField listに表示されています。ここから分析したいものをX-Axis,Y-Axisにドラッグ&ドロップします。今回は全ての列の組み合わせを可視化したいので、すべての列を各軸に持っていきます。
今回は量的データ×量的データの組み合わせなので、散布図を選択してみます。
※この時ツールバー内「Aggregation」のチェックを外しておきましょう


②シェルフへの反映
アヤメの種類に関する列をField listの隣にあるシェルフ欄に移動させます。
今回はColor欄に反映させます。

散布図を見ると、花の全体的な大きさはsetosa<versicolor<virginicaの順番になっている傾向ができます。特に花びらの幅、長さで比較すると違いがはっきり確認できます。
別タブでX-Axis:「花びらの長さ」、Y-Axis:「花びらの幅」に設定したグラフを作成してみましょう。

花びらの幅と長さに着目すると、setosaは他2種と比べ花びらのサイズが明確に小さいことがわかります。長さが1㎝程違うので、肉眼で実物を比べても見分けがつくのではないでしょうか。またversicolorよりもvirginiaが花びらのサイズが大きい傾向にありますが、一部分布に重なりが確認できます。
今回は簡易なデータセット例ですが、全体の傾向把握→個別のカラムの組み合わせに着目した可視化までの流れをご紹介しました。
その他の機能
ページ上部のツールバーから様々な機能を使用することができます。
エクスポート機能が充実しており、作ったグラフの画像出力は勿論、グラフに用いたカラムのCSVやデータフレーム出力にも対応しています。
ですからpandas等での詳細な分析にスムーズにつなげることが可能です。
またグラフの構成をコードで出力でき、一旦GUIを終了しても作成過程を再現することができます。
グラフ操作関係
Undo/Redo
各操作の戻る/やり直しAggregation
データの集計方法を合計/平均/カウント等から選択Mark Type
グラフの種類を12種類から選択。デフォルトで自動的に最適な種類を選択してくれます。Stack Mode
元の値のまま積み上げ、正規化、標準化Transpose
行列の入れ替えSort Order
値に応じたグラフの昇順/降順の並び替えAxies Resizing
軸の調整(グラフ数等に応じた再調整)Layout Mode
グラフサイズの変更Coordinate System
汎用データ/地理的データの切り替え
エクスポート/設定その他
Debugging
Export
png,svg形式の選択が可能Export as csv
使用しているカラムのCSVが出力されるConfig
色やフォーマット設定の変更export_code
作ったグラフの構成をpythonコードで出力。GUIを終了しても続きから再開が可能。Save
GUI上でグラフ構成を保存。ローカル環境での使用を推奨
(Google Colaboratory上ではエラー)export_dataframe
使用しているカラムのデータフレームを出力
(Google Colaboratory上ではエラー)limit
表示する値のフィルタリング機能Open Painter
特定の値を強調するために色分けが可能kanaries docs
公式ドキュメントへのリンク
pygwalkerの利点
特にご紹介したい点は以下4つです。
コーディングなしで簡単に分析・可視化できる
簡単に複数のグラフを書くことができ、スピードと手軽さにおいてmatplotlib等より優位です。無料
同じような分析のできるBIツールtableauは有料のソフトウェアです。Tableau Publicという無料版もありますが、保存したVizは公開されるので、分析内容を非公開にしておきたい場合は利用できません。一方pygwalkerは無料で利用できます。デスクトップアプリなどのインストールも不要なのでその点においても非常に手軽です。他ライブラリ等との連携
jupyter notebook上で動くので、他のPythonライブラリとスムーズに連携できます。グラフを作って方針を立てた後pandasでの集計、matplotlibでより詳細なグラフを記述する等、幅広い応用ができます。
公式ドキュメントではStreamlitと連携してWebアプリケーションとして公開する例が紹介されています。グラフ構成をコードに残せる
コード形式で出力できるので、分析の途中からすぐに再開ができます。また元のデータフレームと合わせれば他のjupyter notebookでもグラフ構成を再現できるため、様々な環境下で分析を行うことができます。
デメリット
グラフのカスタマイズ性が低い(Tableauと比べ)
グラフ内への値ラベルの追加や100%棒グラフの選択等、Tableauと比べると細かい調整まではできません。詳細の記述にこだわる場合は、matplotib等での描写に切り替える必要があるでしょう。データフレーム同士の接続は非対応
pygwalkerのGUIは単一のデータフレームにしか対応しておらず、複数のデータフレームを分析したい場合は結合済のものをGUIに渡す必要があります。ドリルダウンに非対応
データの階層(日付等)の作成にも非対応です。時系列データを分析する際には軸にどのデータを配置するか、少し工夫が必要です。
まとめ
今回はpygwalkerの基本的な使い方、機能、利点等についてご紹介しました。
pythonでデータ分析を行う際、最初のデータ全体の傾向把握や分析の方針立てに大いに活用できるのではないでしょうか?皆さんもぜひ使ってみてください。
データ分析に興味のある方募集中!
コグラフ株式会社データアナリティクス事業部ではPythonやSQLの研修を行った後、実務に着手します。
研修内容の充実はもちろん、経験者に相談できる環境が備わっています。
このようにコグラフの研修には、実務を想定し着実にスキルアップを目指す環境があります。
興味がある方は、下記リンクよりお問い合わせください。

X(Twitter)もやってます!
コグラフデータ事業部ではX(Twitter)でも情報を発信しています。
データ分析に興味がある、データアナリストになりたい人など、ぜひフォローお願いします!
📢Wantedly新掲載!
— アラリコ@コグラフ株式会社 | データ事業部 (@CographData) July 14, 2023
「データに興味がある」
「データに携わる仕事がしたい」
そこのあなた!
私たちと一緒にデータ分析しませんか?
IT業界未経験の方も大歓迎です☺️#エンジニア転職 #データ分析 #駆け出しエンジニアと繋がりたいhttps://t.co/S9o7VSjGRt
この記事が気に入ったらサポートをしてみませんか?