割り算だけじゃもったいない。ベータ分布も描いてみよう。

こんにちは。コグラフ株式会社データアナリティクス事業部の塩見です。
コインを投げて、表が7回、裏が3回出たとすると、表が出る確率は0.7と計算できますね。しかし、このように割り算で求めた確率の値だけでは、失われてしまう情報があるのです。割り算だけではなく、表が出る確率の分布を描いて、もっと豊かな情報を手に入れましょう。
この記事のコードはGoogle ColaboratoryのPythonで動きますので、ぜひお試しください。
ベータ分布とは
わかりやすい言葉で説明しますと、ベータ分布は「コイン投げにおける表が出る確率の予測分布」という解釈ができます。
表が出る確率$${\theta}$$が不明であるコインを何回か投げて、表がm回、裏がn回出たとします。このとき「表が出る確率$${\theta}$$の予測値」は、パラメータが (a, b) = (m+1, n+1) であるベータ分布に従うと考えることができます。
高校数学の美しい物語 ベータ分布の意味 より
正確に説明しますと、コイン投げの問題を尤度が二項分布であるとして統計モデリングしています。その二項分布と共役の関係にある分布がベータ分布です。
コインを投げる前
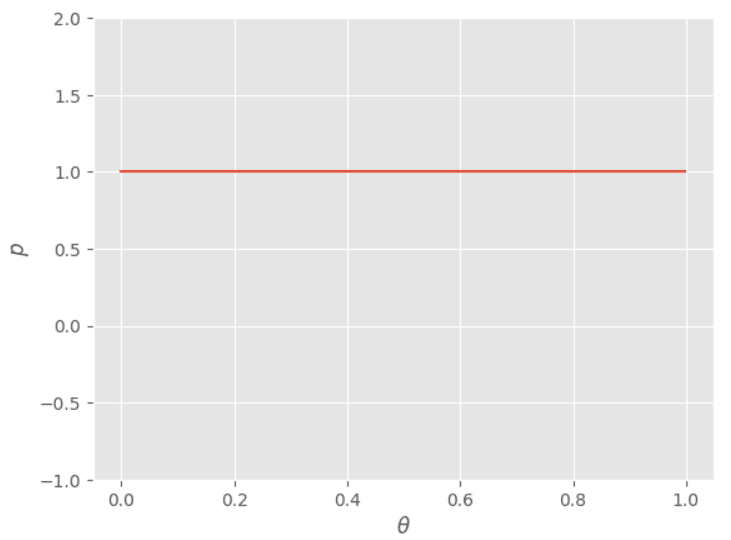
まだ一回もコインを投げていないので、表がm=0回、裏がn=0回出たと考えましょう。このとき「表が出る確率$${\theta}$$の予測値」はパラメータが (a, b) = (m+1, n+1)=(1, 1) であるベータ分布に従います。このベータ分布を描画するPythonコードと、その出力を示します。
import numpy as np
from scipy.stats import beta
import matplotlib.pyplot as plt
plt.style.use('ggplot')
m = 0 #表が出た回数
n = 0 #裏が出た回数
theta = np.arange(0, 1, 0.001)
p = beta.pdf(theta, m+1, n+1)
plt.plot(theta, p)
plt.xlabel(r'$\theta$')
plt.ylabel(r'$p$')
plt.ylim(-1, 2) #y軸の範囲がうまく自動調整されないので指定しました。
plt.show()np.arangeで0から1まで0.001刻みのnumpy配列を作成しています。beta.pdfはscipyが提供する関数で、ベータ分布の確率密度関数 (Probability Density Function) を求めてくれます。こうして求めたthetaとpをmatplotlibで可視化しました。
コインを10回投げた
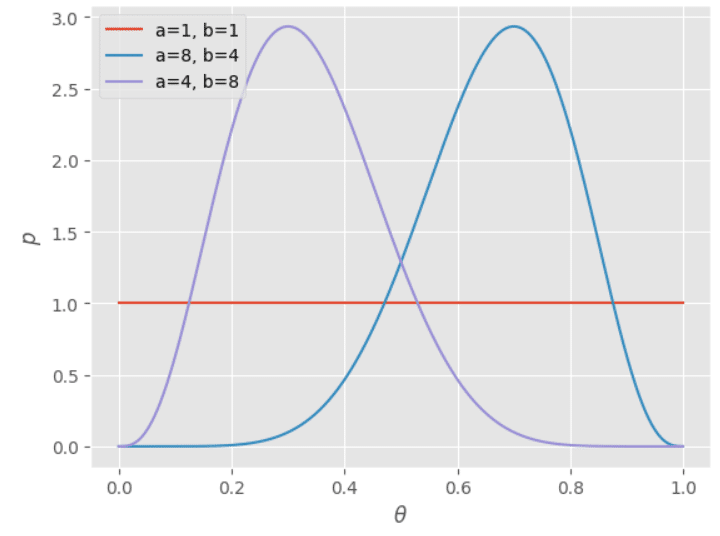
表がm=7回、裏がn=3回出たとします。このとき「表が出る確率$${\theta}$$の予測値」は、パラメータが (a, b) = (m+1, n+1)=(8, 4) であるベータ分布に従います。上記Pythonコードの変数m, nの値を書き換えます。
import numpy as np
from scipy.stats import beta
import matplotlib.pyplot as plt
plt.style.use('ggplot')
m = 7 #表が出た回数
n = 3 #裏が出た回数
theta = np.arange(0, 1, 0.001)
p = beta.pdf(theta, m+1, n+1)
plt.plot(theta, p)
plt.xlabel(r'$\theta$')
plt.ylabel(r'$p$')
#plt.ylim(-1, 2) #y軸の範囲は自動調整にまかせます
plt.show()
これが「表が出る確率$${\theta}$$の予測値」の分布です。$${\theta=0.7}$$を頂点としてその周りにもなだらかに$${\theta}$$が分布していますから、$${\theta}$$は0.7以外の値になる可能性もあるということがわかりますね。割り算で求めた、表が出る確率は0.7という一つの数字よりも豊かな情報が得られることがわかると思います。
コインを100回投げた
表がm=70回、裏がn=30回出たと考えましょう。このとき「表が出る確率$${\theta}$$の予測値」はパラメータが (a, b) = (m+1, n+1)=(71, 31) であるベータ分布に従います。Pythonコードの変数m, nの値を書き換えましょう。
import numpy as np
from scipy.stats import beta
import matplotlib.pyplot as plt
plt.style.use('ggplot')
m = 70 #表が出た回数
n = 30 #裏が出た回数
theta = np.arange(0, 1, 0.001)
p = beta.pdf(theta, m+1, n+1)
plt.plot(theta, p)
plt.xlabel(r'$\theta$')
plt.ylabel(r'$p$')
#plt.ylim(-1, 2) #y軸の範囲は自動調整にまかせます
plt.show()
「表が出る確率$${\theta}$$の予測値」の範囲がせまく、するどい分布になりました。つまり試行回数を増やすと予測が正確になるということです。私たちの直感とも一致していますね。
ここまで、コイン投げにおける表が出る確率の予測分布について説明してきましたが、これを実際の問題に応用してみましょう。
A/Bテストに応用する
3種類のウェブ広告A、B、Cのうち、一番クリック率が高い広告を選びたいので、A/Bテストをおこないました。
まずは40回ずつ広告表示
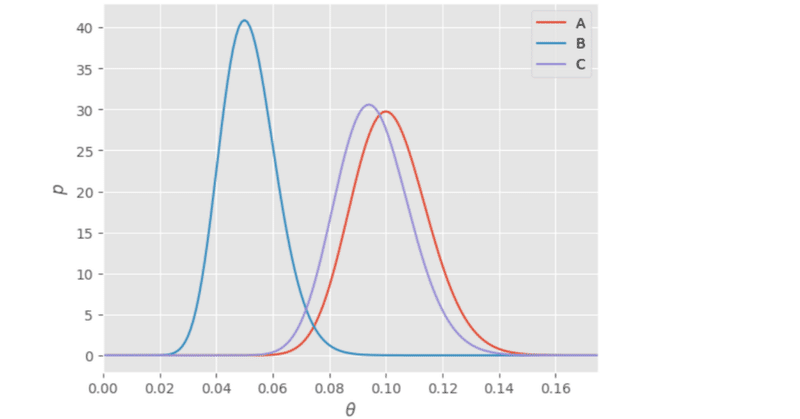
ウェブサイトの訪問者に対して、3種類の広告をランダムに出し分けました。A、B、Cそれぞれを40回ずつ表示したところ、クリックされた回数は以下の通りでした。
広告A 2回
広告B 3回
広告C 4回
クリックされた回数をm、クリックされなかった回数をnとすると、「クリック率$${\theta}$$の予測値」はパラメータが (a, b) = (m+1, n+1)であるベータ分布に従います。$${\theta}$$の分布を描いてみましょう。
import numpy as np
from scipy.stats import beta
import matplotlib.pyplot as plt
plt.style.use('ggplot')
theta = np.arange(0, 1, 0.001)
m = 2 #クリックされた回数
n = 38 #クリックされなかった回数
p = beta.pdf(theta, m+1, n+1)
plt.plot(theta, p, label='A')
m = 3 #クリックされた回数
n = 37 #クリックされなかった回数
p = beta.pdf(theta, m+1, n+1)
plt.plot(theta, p, label='B')
m = 4 #クリックされた回数
n = 36 #クリックされなかった回数
p = beta.pdf(theta, m+1, n+1)
plt.plot(theta, p, label='C')
plt.xlabel(r'$\theta$')
plt.ylabel(r'$p$')
plt.xlim(0, 0.3)
#plt.ylim(-1, 2) #y軸の範囲は自動調整にまかせます
plt.legend()
plt.show()
クリック率の予測の分布をみると、広告Cが一番右側に偏っています。しかし分布には重なっている部分が多く、順番は簡単に入れ替わってしまうでしょう。どの広告が一番クリック率が高いのか、これではまだはっきりしません。
データをもっと追加
データが少ないとはっきりしないので、テストを継続してデータを追加しました。A、B、Cそれぞれを500回ずつ表示したところ、クリックされた回数は以下の通りでした。
広告A 50回
広告B 25回
広告C 47回
import numpy as np
from scipy.stats import beta
import matplotlib.pyplot as plt
plt.style.use('ggplot')
theta = np.arange(0, 1, 0.001)
m = 50 #クリックされた回数
n = 450 #クリックされなかった回数
p = beta.pdf(theta, m+1, n+1)
plt.plot(theta, p, label='A')
m = 25 #クリックされた回数
n = 475 #クリックされなかった回数
p = beta.pdf(theta, m+1, n+1)
plt.plot(theta, p, label='B')
m = 47 #クリックされた回数
n = 453 #クリックされなかった回数
p = beta.pdf(theta, m+1, n+1)
plt.plot(theta, p, label='C')
plt.xlabel(r'$\theta$')
plt.ylabel(r'$p$')
plt.xlim(0, 0.175)
#plt.ylim(-1, 2) #y軸の範囲は自動調整にまかせます
plt.legend()
plt.show()
この結果をみると、広告Bのクリック率が際立って低い値に分布していますので、Bは候補から外してもよさそうです。一方で、広告AとCの違いはあまり顕著ではありません。この後はAとCだけでテストを継続するとよいでしょう。もしくは、大きな違いがないのならAとCのどちらを選んでも変わらない、テストは終了と判断するのもよいでしょう。納得できるまでテストを続けて、好きなところで終了してください。
ベータ分布を描くとうれしいこと
割り算で求める確率の値よりも豊かな情報が得られ、すばやい判断、慎重な判断の材料となります。
簡単なので、すぐに理解して使うことができます。
簡単なので、結果を人に説明しやすいです。
統計的仮説検定にまつわる難しさがありません。
データ分析に興味のある方募集中!
コグラフ株式会社データアナリティクス事業部ではPythonやSQLの研修を行った後、実務に着手します。
研修内容の充実はもちろん、経験者に相談できる環境が備わっています。
このようにコグラフの研修には、実務を想定し着実にスキルアップを目指す環境があります。
興味がある方は、下記リンクよりお問い合わせください。

X(Twitter)もやってます!
コグラフデータ事業部ではX(Twitter)でも情報を発信しています。
データ分析に興味がある、データアナリストになりたい人など、ぜひフォローお願いします!
📢Wantedly新掲載!
— アラリコ@コグラフ株式会社 | データ事業部 (@CographData) July 14, 2023
「データに興味がある」
「データに携わる仕事がしたい」
そこのあなた!
私たちと一緒にデータ分析しませんか?
IT業界未経験の方も大歓迎です☺️#エンジニア転職 #データ分析 #駆け出しエンジニアと繋がりたいhttps://t.co/S9o7VSjGRt
この記事が気に入ったらサポートをしてみませんか?