
レンタルサーバでWebアプリ作り:ChatGPTでテケテケ表示

ロリポップレンタルサーバではできることが限られていたので、ホスティングサービスを使ってWebアプリを公開するまでの道のりを記録します。
データ分析を仕事としているのでパソコンやITのことは多少は詳しいですが、インフラまわりは全くの素人です。そんな人が見て参考になる情報をまとめていきたいと思います。
背景
前回、1~10のカウント表示をテケテケ表示させることを行いました。
前回記事:https://note.com/cryptoscore/n/nd05fbe7a1780
このテケテケ技を使って、ChatGPTの回答をテケテケ表示させます!
ゴール=ChatGPTの回答をテケテケ表示させる
フォルダ構成
test_digitalocean/
├ requirements.txt
├ .env
├ Pipfile ※pipが自動作成
├ Pipfile.lock ※pipが自動作成
├ Procfile
├ gunicorn_config.py
├ app.py
├ templates/
│ ┗index.html
各種ファイル内容
requirements.txt
特に前回と変わりません。
Flask
gunicorn
openai
python-dotenv
Flask-SocketIO
eventletpipを忘れずに。
pipenv install -r requirements.txt
pipenv lock
.env
こちらも、特に変更ありません。
OPENAI_API_KEY='sk-*******'
FLASK_SECRET_KEY='HLd-*******'
Procfile
こちらは、起動プログラムを元に戻した(app:app)感じです。
web: gunicorn -k eventlet -w 1 --worker-tmp-dir /dev/shm app:app
gunicorn_config.py
こちらも不変です。
bind = "0.0.0.0:5000"
workers = 1
worker_class = 'eventlet' # eventletワーカークラスを使用index.html
質問を入力するインプットボックスと、質問を投げるボタンを配置します。
Socketを立ち上げておいて、ボタンが押されたらpythonに質問を投げつけます。
<!DOCTYPE html>
<html>
<head>
<title>Text Submission Example</title>
<script type="text/javascript" src="//cdnjs.cloudflare.com/ajax/libs/socket.io/4.0.0/socket.io.js"></script>
<script type="text/javascript">
document.addEventListener('DOMContentLoaded', function() {
var socketUrl;
var options = {
transports: ['websocket'] // WebSocketのみを使用
};
if (location.protocol === 'https:') {
socketUrl = 'https://' + document.domain; // HTTPSの設定
} else {
socketUrl = 'http://' + document.domain + ':5000'; // ローカル環境の設定(HTTP、ポート5000)
}
var socket = io.connect(socketUrl, options);
socket.on('count_response', function(msg) {
var logElement = document.getElementById('gptanswer');
logElement.textContent = msg.res_txt;
});
document.getElementById('startButton').addEventListener('click', function() {
var text = document.getElementById('textInput').value;
socket.emit('on_start_gptquestion', {q: text});
});
});
</script>
</head>
<body>
<input type="text" id="textInput" placeholder="Enter question to GPT">
<button id="startButton">Submit</button>
<div id="gptanswer"></div>
</body>
</html>
app.py
on_start_gptquestion でHTMLから質問を受け取り、 start_gptquestion でGPTに質問しています。
テケテケ表示については、OpenAI-APIの公式ドキュメントをまんま流用しています。stream = True で質問を投げつけ、chunkで拾います。
ポイントは、`socketio.sleep(0.1)`です。これがないとテケテケ表示してくれません。処理が追いつかないのかな。最初、 time.sleep(0.1) としてしまってテケテケ表示してくれませんでしたが、 socketio.sleep(0.1) にしたら無事テケテケしてくれました。
from flask import Flask, render_template, request, jsonify
from flask_socketio import SocketIO
from openai import OpenAI
from dotenv import load_dotenv
import os
import uuid
# 環境変数を読み込む
load_dotenv()
client = OpenAI()
app = Flask(__name__)
app.config['SECRET_KEY'] = os.getenv('FLASK_SECRET_KEY') #環境変数から設定
socketio = SocketIO(app)
@app.route('/')
def index():
return render_template('index.html')
def start_gptquestion(text):
stream = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": text},
],
stream=True,
)
msg = ""
for chunk in stream:
if chunk.choices[0].delta.content is not None:
msg += chunk.choices[0].delta.content
print(msg)
socketio.emit('count_response', {'res_txt': msg})
socketio.sleep(0.1)
@socketio.on('on_start_gptquestion')
def on_start_gptquestion(message):
q = str(message['q'])
socketio.start_background_task(start_gptquestion, q)
if __name__ == '__main__':
socketio.run(app)実演
上記のプログラムをGitHubに上げ、DigitalOceanが自動的に更新されたら、実演してみましょう。
以下のようにテケテケ表示されれば成功です!
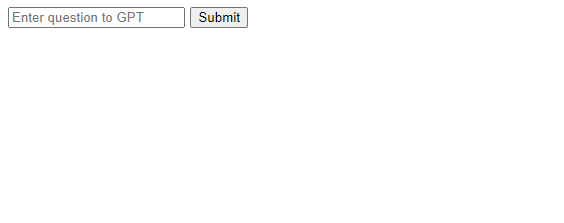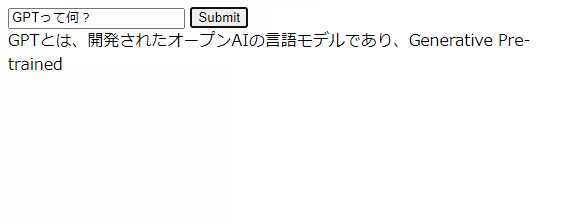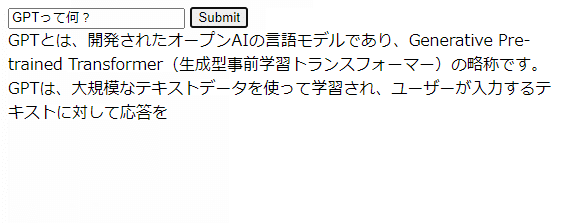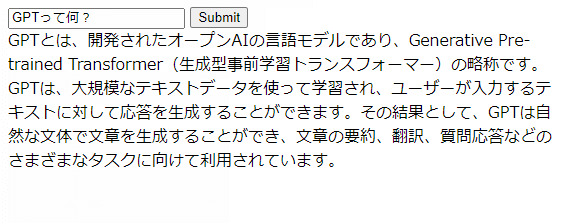
ゴール2 = もっと早く表示させる
上記の内容だと、1チャンクごとに0.1秒ウェイトがかかっているので表示が遅くなります。
そこで、threadを使って非同期でstreamに結果を積んで、0.1秒ごとにそのstreamを表示させるようにします。
app.pyの修正
修正はapp.pyだけです。
token_queueというdeque型(list型みたいなもの)をグローバル変数で用意し、非同期でtoken_queueにGPTの回答をためていき、0.1秒ごとにそれを表示させます。
from flask import Flask, render_template, request, jsonify
from flask_socketio import SocketIO
from openai import OpenAI
import threading
from collections import deque
from dotenv import load_dotenv
import os
import uuid
# 環境変数を読み込む
load_dotenv()
client = OpenAI()
app = Flask(__name__)
app.config['SECRET_KEY'] = os.getenv('FLASK_SECRET_KEY') #環境変数から設定
socketio = SocketIO(app)
token_queue = deque() #GPTの回答がどしどし入る箱
@app.route('/')
def index():
return render_template('index.html')
def thread_gptquestion(text):
global token_queue
token_queue = deque() #初期化
stream = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": text},
],
stream=True,
)
#token_queueにどしどしためていく(非同期で)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
token_queue.append(chunk.choices[0].delta.content)
token_queue.append('[[end]]') #終了サイン
def start_gptquestion(text):
global token_queue
thread = threading.Thread(target=thread_gptquestion, args=(text,))
thread.start()
msg = ''
while True :
if token_queue :
token = token_queue.popleft()
token = token.replace('\n', '<BR>')
if token == '[[end]]' :
print('-------------end----------------')
break
msg += token
socketio.emit('count_response', {'res_txt': msg})
else :
socketio.sleep(0.1) #キューに何もなくなったところで0.1秒待つ
@socketio.on('on_start_gptquestion')
def on_start_gptquestion(message):
q = str(message['q'])
socketio.start_background_task(start_gptquestion, q)
if __name__ == '__main__':
socketio.run(app)
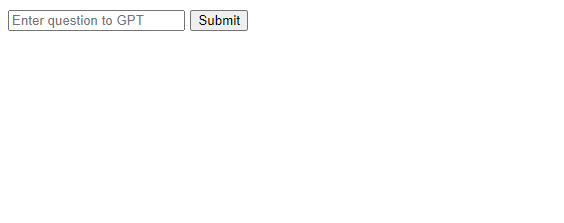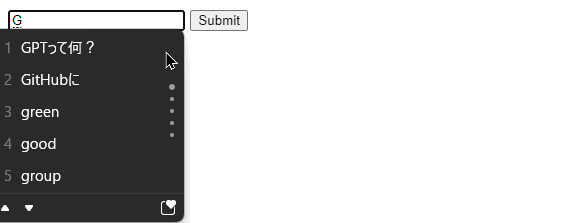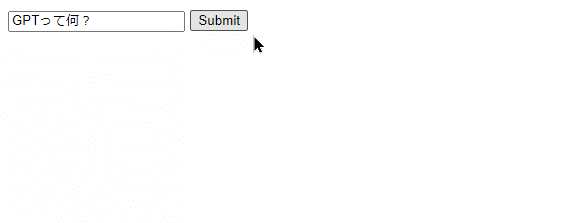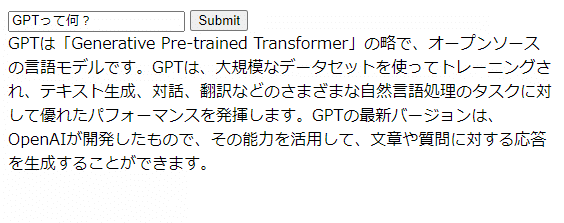
この変更で、以下のように表示が早くなっていれば大成功です!
最後まで見ていただきありがとうございました!
テケテケ表示ができてホッとしてます。できなかったら、DigitalOceanに乗り換えた苦労がすべて水の泡でした。。。
DigitalOceanのアカウント登録
(200ドル分チケット付き)
以下は紹介リンクですが、ここから手続きを進めてもらえると200ドル分の無料チケット(有効期間2ヶ月)がもらえるようですので、ぜひご活用ください。
※ 2023/12/29時点
紹介リンク : https://m.do.co/c/a8b31ed34b75
サポート問い合わせ先
DigitalOceanのサポート問い合わせリンクがなかなか見つからないので、リンクを載せておきます。
https://cloudsupport.digitalocean.com/s/
場所は、トップページの右下にある「Ask a question」に行き、そのページの一番下(欄外っぽいところ)にひっそりと「Support」というリンクがあります(Contact内)。そのページの一番最後に「Contact Support」ボタンがあります。
この記事が気に入ったらサポートをしてみませんか?