
【Pythonで統計モデル】SEM6:MIMICモデル

はじめに
株式会社GA technologiesの白土です。
Pythonで統計モデル(SEM編)シリーズは構造方程式モデリング(SEM:Structural Equation Modeling)をPythonでどこまで実行できるかを調査・確認しています。
本記事は5本目にあたり、1つの構成概念が観測変数群に影響を与えるMIMICモデルを扱っていきます。z
このシリーズでは今後も各メンバーが学んだことをそれぞれ記事にしていきます。もしご興味のある方がいらっしゃいましたら、AISCマガジンのフォローをお願いします!
シリーズとしてはDSチーム全体での取り組みではありますが、私自身は本格的に統計学の勉強を始めたのも最近であり、SEMに関しても初学者です。
もし誤りや補足、あるいは感想などありましたらいただけると大変助かります!
また、この記事では東京図書から出版されている共分散構造分析[R編]―構造方程式モデリング―で取り上げられていた事例を、Pythonを使って再現していきます。分析用データは東京図書のホームページからダウンロードできますので、興味のある方はぜひ試してみてください。
前回も記載しましたが、書籍の購入に際しては「テックチャージ」の制度を利用しています!
環境
本記事の分析は、OS: MacOS 12.4、Python 3.9.12の環境下で行っています。また、必要なパッケージは以下となります。インストール済みの方は割愛してください。
# packageのインストール
pip install numpy pandas matplotlib japanize_matplotlib
pip install graphviz
pip install factor_analyzer
pip install semopyなおsemopyは構造方程式モデリング(SEM )を行うためのパッケージで、ドキュメントは以下にあります。
本記事ではここから重要な部分をいくつかピックアップしてご紹介します。網羅的な解説はしませんので、適宜、必要に応じてご参照ください。
MIMICモデル
今回はsemopyを用いてMIMICモデルの分析を行います。
MIMICモデルとは「複数の観測変数によって1つの構成概念が規定され、その構成概念が別の観測変数群に影響を与えている」モデルです。
テキストでは他に「多重指標モデル」「PLSモデル」についても説明されており、個人的には違いがわかりにくかったので整理しておきます。
多重指標モデルは「複数の観測変数によって測定されている構成概念が、別の複数の観測変数によって測定されている構成概念に対して影響を与えているモデル」で構成概念間の回帰分析モデルと捉えることもできます。
具体的には例えば以下の記事で扱ったモデルが多重指標モデルです。
PLSモデルは「複数の観測変数によって指標化された構成概念が、別の複数の観測変数の背後に仮定される構成概念に影響を与えているモデル」で、多重指標モデルとの違いは観測変数から構成概念に対して伸びている矢印が存在している点です。
PLSモデルについては、このシリーズでも次回以降に扱う予定ですので、詳細についてはそちらでご覧ください。
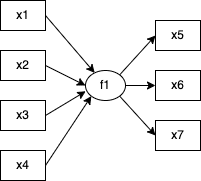
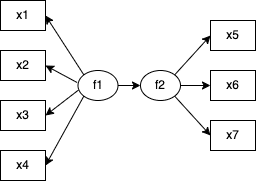
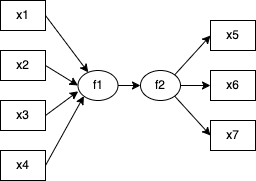
では三つのモデルの違いを理解した上で、次からは実際にsemopyを用いてMIMICモデルの分析を行っていきましょう。
パッケージとデータの読み込み
import pandas as pd
import numpy as np
from factor_analyzer.utils import covariance_to_correlation
import semopyX = pd.read_csv("R_code/dat/seminar.csv", encoding='shift_jis', index_col=0)
# 扱いやすいように列名を変更
X.columns = ['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7']このデータは【Pythonで統計モデル】SEM1:速習・構造方程式モデリングで使用したのと同じもので、あるセミナーに対して「テキスト x1」「プレゼン x2」「ペース x3」「講師対処 x4」「満足度 x5」「理解度 x6」「目的一致 x7」の7項目を5件法で観測したものです。
print(X.head()) x1 x2 x3 x4 x5 x6 x7
佐藤 3 5 4 5 5 5 4
鈴木 4 4 4 5 3 4 2
高橋 4 4 4 4 5 4 1
田中 2 3 2 2 4 2 4
渡辺 1 1 1 1 1 1 1分析の実行
今回想定するのは「テキスト x1」「プレゼン x2」「ペース x3」「講師対処 x4」の4つの観測変数が「充実感 f2」という潜在変数に影響を与え、さらに「充実感 f2」が「満足度 x5」「理解度 x6」「目的一致 x7」という3つの観測変数に影響を与える、というMIMICモデルです。
model1 = """
f2 ~ x1 + x2 + x3 + x4
f2 =~ x5 + x6 + x7
x1 ~~ x2
x1 ~~ x3
x1 ~~ x4
x2 ~~ x3
x2 ~~ x4
x3 ~~ x4
x1 ~~ x1
x2 ~~ x2
x3 ~~ x3
x4 ~~ x4
"""前回の私の記事にも書いたように、semopyでは「外生的な観測変数同士の共変関係」は上記のように明示的に記載する必要があります。
model = semopy.Model(model1)
result = model.fit(data=X, obj='MLW')
ins = semopy.Model.inspect(model, std_est=True)
print(ins)分析結果を表示すると小数点第2位の精度でテキストと一致していることが確認できました。
lval op rval Estimate Est. Std Std. Err z-value p-value
0 f2 ~ x1 0.004436 0.005151 0.112181 0.039545 0.968456
1 f2 ~ x2 0.334990 0.342975 0.150155 2.230964 0.025684
2 f2 ~ x3 0.079220 0.106903 0.100115 0.791282 0.428779
3 f2 ~ x4 0.018380 0.023510 0.109045 0.168559 0.866144
4 x5 ~ f2 1.000000 0.624918 - - -
5 x6 ~ f2 0.618710 0.413396 0.261818 2.363131 0.018121
6 x7 ~ f2 0.426187 0.409261 0.180949 2.355289 0.018508
7 x1 ~~ x2 0.204028 0.220486 0.087232 2.338909 0.01934
8 x1 ~~ x3 0.320887 0.263098 0.116099 2.763916 0.005711
9 x1 ~~ x4 0.253523 0.219298 0.108954 2.326887 0.019971
10 x1 ~~ x1 1.049483 1.000000 0.136631 7.681146 0.0
11 x2 ~~ x3 0.374334 0.348089 0.104824 3.571058 0.000356
12 x2 ~~ x4 0.460670 0.451932 0.102975 4.4736 0.000008
13 x2 ~~ x2 0.815909 1.000000 0.106222 7.681146 0.0
14 x3 ~~ x4 0.212142 0.157900 0.125213 1.694247 0.090218
15 x3 ~~ x3 1.417406 1.000000 0.184531 7.681146 0.0
16 x4 ~~ x4 1.273478 1.000000 0.165793 7.681146 0.0
17 f2 ~~ f2 0.650422 0.835632 0.333057 1.952884 0.050833
18 x7 ~~ x7 0.702697 0.832506 0.11148 6.303365 0.0
19 x5 ~~ x5 1.214765 0.609478 0.346851 3.502264 0.000461
20 x6 ~~ x6 1.445544 0.829104 0.230718 6.265428 0.0簡易的なものですが、以下のコードでパス図を作成することができます。
semopy.semplot(model, "graph.png", std_ests=True, plot_covs=True)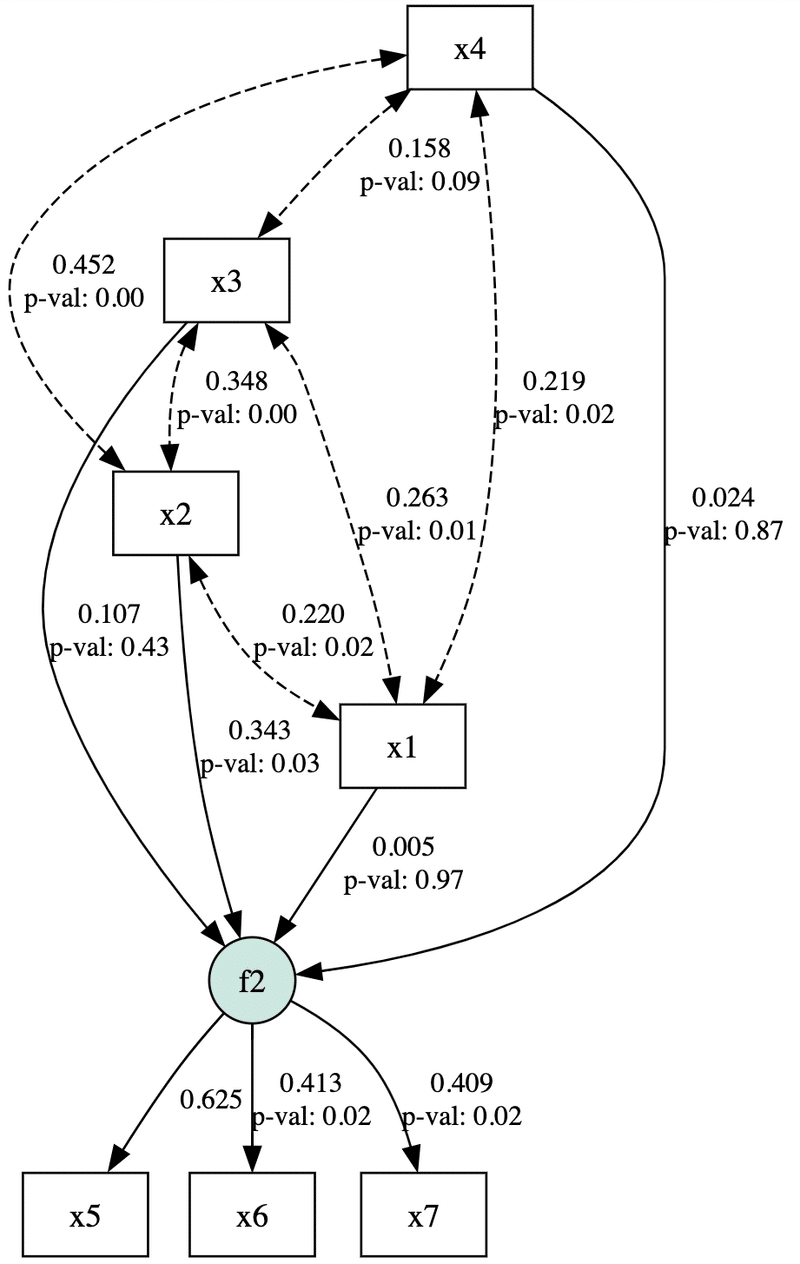
続いてモデルの適合度指標を求めると以下のようになりました。
stats = semopy.calc_stats(model)
print(stats.T) Value
DoF 8.000000
DoF Baseline 21.000000
chi2 9.520761
chi2 p-value 0.300284
chi2 Baseline 92.893678
CFI 0.978847
GFI 0.897509
AGFI 0.730961
NFI 0.897509
TLI 0.944474
RMSEA 0.040308
AIC 39.838631
BIC 95.252324
LogLik 0.080684Rでも同様のモデルを作成して出力した結果の一部を抜粋したものが以下になります。
lavaan 0.6.15 ended normally after 26 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 20
Number of observations 118
Model Test User Model:
Test statistic 9.521
Degrees of freedom 8
P-value (Chi-square) 0.300
Model Test Baseline Model:
Test statistic 37.468
Degrees of freedom 15
P-value 0.001
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.932
Tucker-Lewis Index (TLI) 0.873
Root Mean Square Error of Approximation:
RMSEA 0.040この二つを比較すると作成したモデルの自由度やRMSEAは互いに一致していることがわかります。(SRMRについてはsemopyでは別途自分で計算する必要があります。詳しくはPythonで統計モデル(SEM編)第1回の記事をご覧ください)
一方で適合度指標の中でも、CFIやTLIはsemopyとlavaanとで出力結果に違いがあります。
さらに互いの結果を確認していくと、「独立モデルの自由度」(「DoF Baseline」と「Model Test Baseline Model: Degrees of freedom」)にも違いがあることがわかりました。
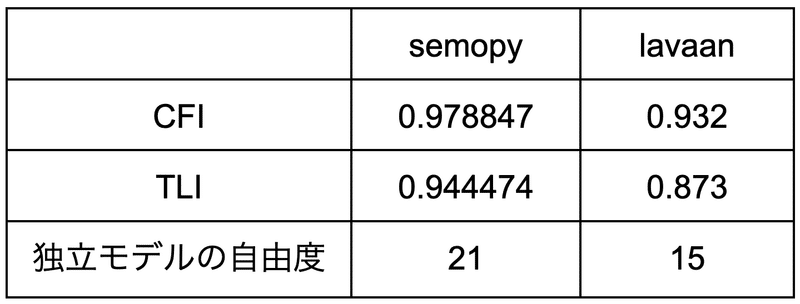
適合度指標のズレについて
このズレについて検討するためにCFI、TLI、独立モデルの確認をします。
CFIとTLIですが、これは分析モデルが独立モデルと比較して「相対的に見てどの程度良いものであったのか」によって評価されるもので、計算に独立モデルの自由度を使用します。
そのため、CFIとTLIのズレは独立モデルの自由度のズレに起因していると考えられます。
次に独立モデルですが、テキストのp193によると以下のように説明されています。
あるデータを分析する場合に、想定しうる中で最も適合の悪いモデルのことを独立モデル、帰無モデル、ベースラインモデルなどと呼びます。
共分散構造分析の場合、全ての観測変数間に一切のパスを引かず、各変数の分散のみを自由推定するモデルを独立モデルと考えることが一般的です。
つまり今回の分析に当てはめると以下のようなモデルだと考えられます。

自由度とは「分散共分散行列の対角要素を含む下三角行列の数」から「推定する母数」を引いた数なので、今回のモデルでは28から上記の図の分散の数7を引いた数、つまり21のように思われます。
この数字はsemopyの独立モデルの自由度と一致しています。
lavaanの15という数字について、どのようなモデルを想定しているのかはわかりませんでした。ですが、この独立モデルの自由度の違いが、CFIやTFIのズレを引き起こしていることは間違いないかと思います。
最後に
今回semopyとlavaanの出力結果に差が生じたことにより、改めてツールをそのまま信じるのではなく、しっかりと調査することの重要性を感じました。
具体的に「どのような定義・計算の違いによって生じるものか?」を特定できると良かったのですが、今回はそこまで調べることはできませんでした。
ただし、仮にsemopyの方が正しい場合でも、より普及しているlavaanの方が適合度指標としての基準が厳しい、という違いなので、クリティカルな問題ではないと感じます。
不明点を残したままとなってしまいましたので、ご存知の方がいましたらご教示いただけますと幸いです。
今後の流れ
今後はPLSモデルや多変量回帰分析について更新していく予定です。
興味のある方は、ぜひAISC Magazineのフォローをお願いします!
この記事が気に入ったらサポートをしてみませんか?