
「Makuake」で開始したプロジェクトの応援購入総額を時系列予測する

こんにちは。マクアケ開発本部MLチームに業務委託として参画している大脇です。この記事では Makuake データ Lab と株式会社サイバーエージェントの研究開発組織 AI Lab が共同で取り組んだ応援購入総額シミュレーションについて、私が苦悩したことを中心にお話しします。応援購入総額シミュレーションについてはプレスリリースも掲載されていますので、興味を持ってくださった方は合わせてご覧ください。
「Makuake」における応援購入総額の推移を予測したい
なぜ応援購入総額を予測するのか?
現在既に多くの企業で需要予測が行われていますが、在庫の適正化が目的であるケースが多いです。工業製品を製造する工場や商品を販売する小売店など、様々な現場で過不足のない適正な在庫を保つために需要予測結果に基づいた判断が行われています。
一方、「Makuake」は応援購入された後に商品 (プロジェクトのリターン) を用意する仕組みのため、在庫適正化を目的とした需要予測よりも、下記を目的とした応援購入総額予測の方が望まれていました。
プロジェクト実施中に応援購入総額がどのくらいで着地するのか予測する
プロジェクトを実施する実行者への様々な支援がどのくらい効果をもたらすのかを推定する
「Makuake」の応援購入総額予測モデルはこれらの目的のために開発されました。
応援購入総額予測で目指すもの
応援購入総額予測のブループリントはマクアケのデータ戦略部による手描きの絵でした。

簡単に言うと、現在 (プロジェクト開始後数日経過時点) からプロジェクト終了日までの応援購入総額の推移を分位点回帰するというものです。プロジェクト終了時の応援購入総額が90%の確率で120万円、80%の確率で130万円…60%の確率で150万円を超えるというように、不確実性を考慮して予測するというものです。参考として応援購入総額予測の結果サンプルもお見せします。(事情により金額や日付をマスクしています。)

開発の過程で分位点を10% - 25% - 50% - 75% - 90%に変更しています。直感的に分かりやすいように、50%の確率で25%点と75%点の間 (赤い範囲) に着地し、80%の確率で10%点と90%点の間 (黄色い範囲) に着地するという表現で説明しています。
さらに、CFML (反実仮想機械学習) などの因果推論の手法を用いてプロジェクトに関する様々な施策の効果を推定できるようにすることで、プロジェクトのプランニングに利用するというのが応援購入総額予測のゴールです。例として、とある施策を行った際の効果推定の例をあげておきます。

[notes]
分位点回帰とは、真値が確率qで下回る値、逆に言うと(1 - q)で上回る値を予測するというものです。例えば、25%点 (25th percentile) の場合、真値が25%の確率で25%点の値を下回るという意味になります。ちなみに、50%の確率で真値が25%点と75%点の間をとり、80%の確率で10%点と90%点の間をとるという意味になります。このような区間は予測区間と呼ばれています。
よくある平均を予測する場合はMSE (Mean Squared Error) で最適化するのに対し、分位点回帰の場合はQuantile Loss (Pinball Loss) で最適化します。それほど難しくないので、興味がある方は調べてみてください。
「Makuake」独自の予測モデルを作る
時系列予測手法はたくさんある
まずは時系列予測のアプローチの中で巷でよく知られているものをあげてみます。
ARIMAやSARIMAなどの統計的な自己回帰系のモデル
自己回帰系モデルに対し、データに欠損がある場合でも使用できるなどの利点がある状態空間モデル
一般化加法モデルを採用したことによる高い解釈可能性や気軽に使えるライブラリが提供されているのが魅力のMeta社のProphetやLinkedIn社のGreykite
Tabular (テーブル形式のデータ) しか扱えないため、時系列予測ではラグ特徴量やターゲットエンコーディングなどの特徴量エンジニアリング手法を駆使する必要があるが、みんな大好きなGBDT (勾配ブースティング決定木)
TabularではなくTimeSeries (時系列データ) まま扱うことができるLSTMやTransformerベースのNN (ニューラルネットワーク)
メジャーな時系列予測のアプローチを大別するとこんな感じだと思います。それぞれ優れている点や劣っている点、優劣ではない特徴があるため、時系列予測の問題に取り組んだことがある方はどの手法を採用するか悩んだ経験があると思います。
時系列予測問題としての「Makuake」における応援購入総額予測の特徴
次にどの時系列予測手法を採用するか決めるに当たって洗い出した「Makuake」における応援購入総額予測問題の特徴をあげてみます。
各プロジェクトは開始日と終了日が予め決まっており、小売店の商品のように長期間販売され続けるものではない
前日までの応援購入総額の実績だけでなくプロジェクトに関する様々なメタデータが使える
単日の応援購入額ではなく累積の応援購入総額に興味がある
不確実性を考慮して分位点回帰したい
最終的には様々な効果推定に利用するために、様々な情報をモデルに入力できるようにしていきたい
開始日と終了日が決まっていること、累積値を分位点回帰することなど、時系列予測問題としては一癖ある問題だと思います。
今回選んだ時系列予測手法
結論を言うと、TransformerベースのNNのモデルを採用しました。時系列予測で採用されるNNのアーキテクチャは様々ですが、下記のようなアーキテクチャは多く見られます。
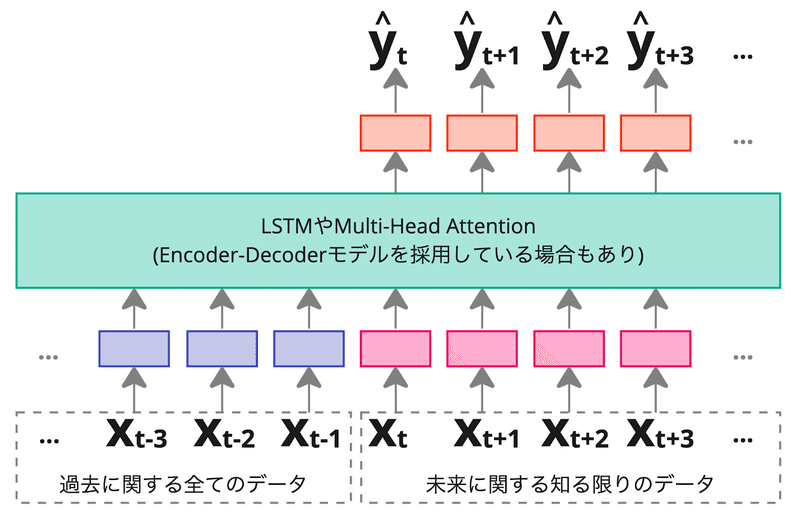
当然TimeSeriesのまま扱うことが可能で、過去については渡せる全てのデータを、未来についても現時点で知る限りのデータを入力できるようなアーキテクチャが多いです。GBDTのようにTimeSeriesからTabularに変換する過程で日別の情報が失われるようなことはありません。最終的に様々な効果推定に活用したいという狙いがあるため、過去にどのような状態だったのか、未来はどのような状態なのかを日別に表現できるデータ形式を扱える利点は大きいと判断しました。
また、モデルのアーキテクチャを自由にカスタマイズできるという利点もあります。我々も有名な時系列予測のアーキテクチャをベースにしつつ出力部分にカスタマイズを施しています。詳細は次の「より良い予測を行うための挑戦」で説明します。
ちなみに、最近でもA decoder-only foundation model for time-series forecastingなどのTransformerを使った時系列予測手法が提案されており、時系列予測のアプローチとしてもTransformerが普及しているように思います。とは言え、Are Transformers Effective for Time Series Forecasting?で指摘されているように、必ずしもTransformerベースのモデルが優れているわけではなく、問題によっては単純な線形モデルの方が良いこともあります。扱うデータの特徴やトレーニングに使えるデータ量などに応じて最適な手法が異なるので問題に応じた判断が必要です。
より良い予測を行うための挑戦
自然な予測を行うことの難しさ
実際に「Makuake」のプロジェクトの応援購入総額を予測してみると、人間の目から見て不自然な予測を行ってしまうケースがあることが分かりました。中でも最も気になった問題は下記の2つです。
A. ある日の予測値よりもその翌日の予測値が小さくなる
B. 前日の実績値よりも小さい予測値が存在する
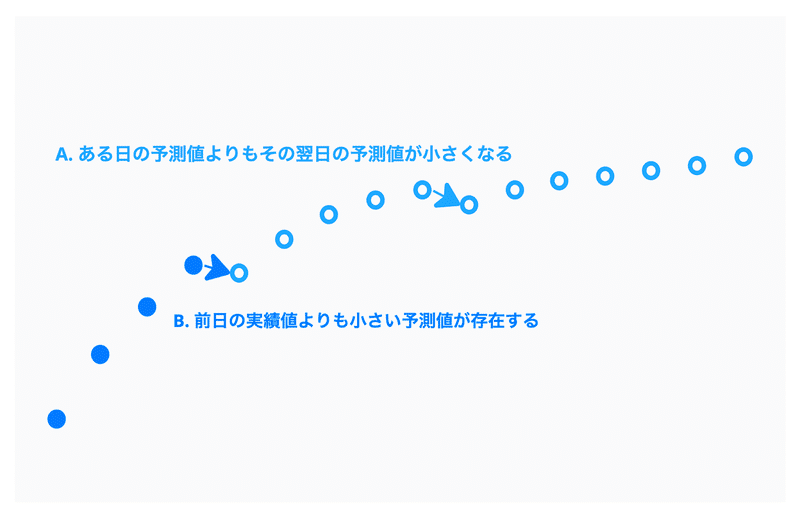
どちらも累積の応援購入総額の予測としては不自然に見えてしまい、見る人によっては予測結果を信用できなくなることさえあります。前日の応援購入総額の実績値から減ることなくプロジェクト終了日まで単調増加するような結果が望ましいです。
[notes]
ちなみにこの問題は単日の予測を行った後に累積を計算するというステップを踏むと問題にならないことが多いです。トレーニングデータのターゲットは全て0以上なので単日の予測値が負数になることは稀で、数日の予測値が負数になったとしても累積を計算する前に負数を0に置換するだけで、大抵の場合ほぼ自然な予測結果になります。
ただし、この方法が使えるのは平均を予測する場合だけで、分位点回帰の場合は不可能です。単日の分位点を足しても累積の分位点にならないというのが理由です。累積値を分位点回帰するというレアケースゆえの問題なので、前例を探して解決策を求めるのは望みが薄いと判断しました。折角なので私なりに考えた解決策を紹介させていただきます。
予測値が単調増加するように制約を課す
ある日の予測値よりもその翌日の予測値が小さくなる問題を解消するために、時間の流れにしたがって予測値が単調増加するような制約を課すことにしました。具体的には、下記の2つのステップを行うカスタムレイヤーをモデルの出力部分に追加しました。
出力値全て (当日から終了日まで) が必ず0より大きくなるような変換を行う
1の変換を施した各出力値それぞれに前日までの全ての出力値を加える (Aの問題が解消)
話を簡単にするために1件のTimeSeriesに対するモデルの出力を変換する過程を考えてみます。モデルの出力$${\boldsymbol{\hat{y}}}$$は下式のように表すことができます。
$$
\boldsymbol{\hat{y}} = \begin{bmatrix}
\hat{y}_{t} & \hat{y}_{t+1} & \cdots & \hat{y}_{T}
\end{bmatrix}
$$
$${\hat{y}{t}}$$が当日、$${\hat{y}{t+1}}$$が翌日、$${\hat{y}_{T}}$$がプロジェクト終了日に相当するモデルの出力です。今回はこの後に先程のカスタムレイヤーを追加するため、これらは出力される予測値ではなくなります。紛らわしいので、カスタムレイヤーの手前の出力値を$${\boldsymbol{\hat{y}}}$$ではなく$${\boldsymbol{z}}$$と置くことにします。
$$
\boldsymbol{z} = \begin{bmatrix}
z_{t} & z_{t+1} & \cdots & z_{T}
\end{bmatrix}
$$
まずは、あらゆる実数を$${(0, \infty)}$$の値に変換できるsoftplus関数$${s(\cdot)}$$を使い、各出力値が必ず0より大きくなるようにします。softplus関数を知らない方はReLUを滑らか (あらゆる入力で微分可能) にしたものを想像してください。
$$
s(\boldsymbol{z}) = \begin{bmatrix}
s(z_{t}) & s(z_{t+1}) & \cdots & s(z_{T})
\end{bmatrix}
$$
次に、softplus関数を適用した各出力値それぞれに前日までの全ての出力値を加えます。PyTorchやTensorFlowで下式のような上三角行列$${\boldsymbol{U}}$$を乗じればよいでしょう。これで単調増加になります。
$$
\begin{align*}
s(\boldsymbol{z})\cdot\boldsymbol{U} &=& \begin{bmatrix}
s(z_{t}) & s(z_{t+1}) & \cdots & s(z_{T})
\end{bmatrix}
\begin{bmatrix}
1 & 1 & \cdots & 1 \\
0 & 1 & \cdots & 1 \\
\vdots & \vdots & \ddots & \vdots \\
0 & 0 & \cdots & 1
\end{bmatrix} \\
&=& \begin{bmatrix}
\sum_{k=t}^{t}{s(z_{k})} & \sum_{k=t}^{t+1}{s(z_{k})} & \cdots & \sum_{k=t}^{T}{s(z_{k})}
\end{bmatrix}
\end{align*}
$$
ちなみに、分位点回帰の場合はモデルの出力の形が (バッチサイズ, 時系列長) ではなく (バッチサイズ, 時系列長, 分位点の数) になるので、上式ではなく左から下三角行列を掛ける形に変更する必要があります。
予測値が前日の実績値よりも大きくなるように制約を課す
前段の予測値が単調増加するように制約を課す過程で全ての予測値は正になっています。そのため、各出力値に前日の実績値$${y_{t-1}}$$を加えることで、必ず前日の実績値よりも大きくなります。
$$
\boldsymbol{\hat{y}} = \begin{bmatrix}
y_{t-1} + \sum_{k=t}^{t}{s(z_{k})} & y_{t-1} + \sum_{k=t}^{t+1}{s(z_{k})} & \cdots & y_{t-1} + \sum_{k=t}^{T}{s(z_{k})}
\end{bmatrix}
$$
ちなみに、NNの場合はターゲットに対してスケーリングを施すことがほとんどなので、上式で加える前日の実績値$${y_{t-1}}$$もスケーリングした後のものを使うようにします。
以上の結果として、冒頭にご覧いただいたイメージの通り自然に増加し続ける予測結果を得ることができます。その上、モデルにこのような制約を課すことでloss (分位点回帰の場合はQuantile Loss) も小さくなる傾向があると思います。
最後に
これまで説明した応援購入総額予測モデルは、既に月に1回の頻度でトレーニングされ、毎朝進行中のプロジェクトの応援購入総額の予測処理が行われています。これらにはVertex AI Pipelinesというワークフローエンジンを使っていますが、このようなMLOpsもマクアケのMLエンジニアの仕事です。その他にもマクアケでは昨今注目されているLLMを含む生成AIにも力を入れています。ご興味のある方はぜひご応募ください!
◉エントリーをご希望の方
◉カジュアル面談をご希望の方
◉マクアケの中の人を知りたい方
この記事がおもしろかった!と思っていただけたら、是非「スキ」&「シェア」をしていただけますと嬉しいです。
この記事が気に入ったらサポートをしてみませんか?