
【競馬AI開発#1】レース開催日一覧をスクレイピングで取得する

はじめに
この【競馬AI開発】シリーズでは、競馬予想AIを作ることを通して、機械学習・データサイエンスの勉強になるコンテンツの発信や、筆者が行った実験の共有などを行っていきます。
今回の記事は、以下の動画に補足を加えて簡単にまとめたものになります。
動画中の実行環境
・OS: Mac OS 14.2.1
・言語: Python 3.11.4
・エディタ: VSCode 1.87.0
VSCodeやPythonのインストール方法については様々な記事で紹介されているので、適宜参照して設定してください。
また、以下のライブラリを使用しています。
beautifulsoup4==4.12.3
pandas==2.2.1
tqdm==4.66.1動画中のソースコード
※転載・再配布はお控えください
筆者のプロフィール
東京大学大学院卒業後、データサイエンティストとしてWEBマーケティング調査会社でWEB上の消費者行動ログ分析などを経験。
現在は、大手IT系事業会社で、転職サイトのレコメンドシステムの開発を行っています。
データ取得のステップ
それでは、今回の内容です。
まずは、最初のステップとしてnetkeiba.comから2023年のレース結果のテーブルをスクレイピングにより取得して、Pythonで扱えるようにすることを目標にします。
「レース結果のテーブル」とは何かというと、以下のようなURLにある、過去に行われたレースの結果がまとめられたテーブルのことです。
https://db.netkeiba.com/race/202301010101

このテーブルの取得は、実は以下のようなコードで簡単にできてしまいます。
from urllib.request import urlopen
import pandas as pd
url = "https://db.netkeiba.com/race/202301010101"
html = urlopen(url).read()
pd.read_html(html)[0]
▼補足
もし「No module named 'pandas'」のようなエラーになる場合は、以下のようなコードで'pandas'をインストールする必要があります。
pip install pandasURLをもう一度見てみてると、以下のような「ベースURL + race_id」の構造になっていることがわかります。
https://db.netkeiba.com/race/{race_id}
よって、まずは次のようなステップで2023年のrace_id一覧を取得することを目標にします。
ステップ1:カレンダーのページから開催日一覧を取得
2023年1月であれば、以下のURLから開催日の一覧を取得することができます。
https://race.netkeiba.com/top/calendar.html?year=2023&month=1
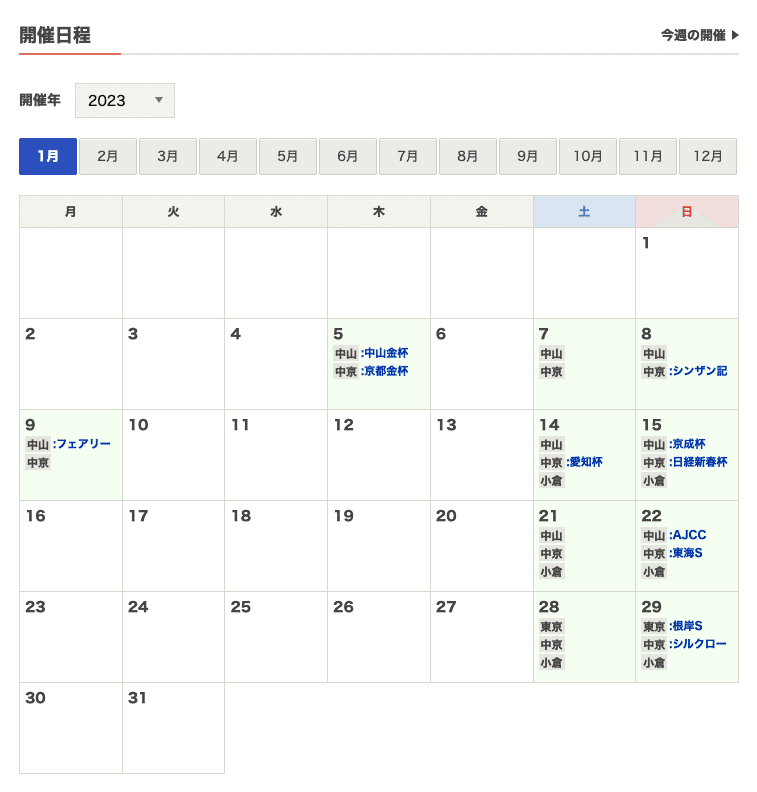
ステップ2:開催ページからレースid一覧を取得
開催日一覧が取得できれば、
URL: https://race.netkeiba.com/top/race_list.html?kaisai_date=20230105
のような「ベースURL + 開催日」で開催ページに辿ることができ、このページからrace_idを取得することができます。

ステップ3:レース結果ページからレース結果テーブル一覧を取得
あとは、先ほどの方法で、レース結果テーブルを取得するだけです。
この記事では、まずは「ステップ1:カレンダーのページから開催日一覧を取得」について扱っていきます。
HTMLとは
先ほどのコードをもう一度掲載します。
from urllib.request import urlopen
import pandas as pd
url = "https://db.netkeiba.com/race/202301010101"
html = urlopen(url).read()ここで取得したものは、ウェブページの構造やコンテンツを記述する「HTML」という言語で書かれたもので、今回であれば「https://db.netkeiba.com/race/202301010101」上に表示されているコンテンツの情報が書かれています。
HTMLは、「ある要素の中に要素2があり、その中にまた要素3があり…」といった入れ子構造になっていることが特徴です。
例えば、以下のような感じです。
<!DOCTYPE html>
<html>
<head>
<title>入れ子構造の例</title>
</head>
<body>
<div>
<h1>これは見出しです</h1>
<p>これは段落です。段落は文をまとめるために使われます。</p>
</div>
</body>
</html>
<html>の中に、<head>と<body>があり、さらに<body>の中には<div>があり…のような入れ子構造になっています。
これらの<html>や<head>など、<>で囲まれたものをタグといいます。
BeautifulSoupの使い方
(動画中8:58あたり〜)
今回であれば、htmlから「開催日」を抽出したいので、ページ全体のhtmlから入れ子構造を頼りに、「開催日が書かれた部分」に絞り込んでいけばよい、というイメージです。
そのためによく使うのが「BeautifulSoup」というライブラリです。次のコードを実行することで、「取得したhtmlをBeautifulSoupで扱って絞り込んでいくぞ!」と宣言できるわけです。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html)準備が整ったので実際に絞り込んでいきます。GoogleChromeでカレンダーページを開き、右クリック->検証を押すと、HTMLの入れ子構造を確認することができます。

入れ子構造を上に辿っていくと、
<table class="Calendar_Table">の中に、
<a href="../top/race_list.html?kaisai_date=20230105" tile="" target="_parent">などが入っていて、「kaisai_date={開催日}」の部分を取得すれば良さそうなので、次のようにしてこの<a>タグに絞り込みます。
a = soup.find("table", class_="Calendar_Table").find("a")
a出力:
<a href="../top/race_list.html?kaisai_date=20230105" target="_parent" tile="">
<div class="RaceKaisaiBox HaveData">
<p><span class="Day">5</span></p>
<p><span class="JyoName">中山</span><span class="JName">中山金杯</span></p>
<p><span class="JyoName">中京</span><span class="JName">京都金杯</span></p>
</div><!-- /. RaceKaisaiBox-->
</a>「.find({tag名}, class_={class名})」で絞り込んでいけるというわけです。
ここから、「href="../top/race_list.html?kaisai_date=20230105"」を抜き出すには、
a["href"]出力:
'../top/race_list.html?kaisai_date=20230105'でいけます。
正規表現とは
(動画中 13:08〜)
次に、この文字列から目的の"20230105"を抜き出す方法ですが、「正規表現」というものを使います。
「正規表現」とは、文字列のパターンを記述するための特殊な文字列のことで、文字列に対して検索・置換・抽出などの操作を行う際に使います。
Pythonでは、reモジュールを使用して正規表現を操作します。
例えば簡単な例だと、以下のようなコードを書くと、「apで始まってeで終わる文字列」を抜き出します。
import re
# 正規表現パターンはr'パターン'と指定する
pattern = r'ap.*e'
# テキスト内のパターンを検索
text = "I have an apple and a banana."
matches = re.findall(pattern, text)
matches出力:
['apple']「.*」は正規表現で「任意の文字列の0回以上の繰り返し」を表すので、「ap.*e」は「apで始まってeで終わる文字列」という意味になっています。
このように、正規表現には特別な記号が用意されており、今回使うのは、「任意の数字」を表す「\d」と「直前文字のn回繰り返し」を表す「{n}」です。
re.findall(r"kaisai_date=(\d{8})", a["href"])出力:
['20230105']re.findall()では、r"kaisai_date=(\d{8})"のように()で括った部分が抽出されます。
結果は、要素が一つのリスト型になっているので、[0]で中身の値を取り出します。(ここ、動画中間違ってカットされていましたmm)
re.findall(r"kaisai_date=(\d{8})", a["href"])[0]出力:
'20230105'あとは、
a = soup.find("table", class_="Calendar_Table").find("a")としていた部分を、
a_list = soup.find("table", class_="Calendar_Table").find_all("a")にすれば、カレンダー中の全ての<a>タグが取り出されるので、
kaisai_date_list = []
for a in a_list:
kaisai_date = re.findall(r"kaisai_date=(\d{8})", a["href"])[0]
kaisai_date_list.append(kaisai_date)とfor文で回せばこのページの開催日一覧の取得は完成です。
kaisai_date_list出力:
['20230105',
'20230107',
'20230108',
'20230109',
'20230114',
'20230115',
'20230121',
'20230122',
'20230128',
'20230129']関数にまとめる
(動画中 16:43〜)
以上が、
URL: https://race.netkeiba.com/top/calendar.html?year=2023&month=1
の開催日一覧を取り出してリストに格納する方法でした。
あとは、「開始月」と「終了月」を指定すれば、間にある全てのカレンダーページに渡って開催日を取得してくれる関数にまとめます。
このあたりは動画でも詳しく解説しているので観てみてください。
import time
from tqdm.notebook import tqdm
def scrape_kaisai_date(from_, to_):
kaisai_date_list = []
for date in tqdm(pd.date_range(from_, to_, freq="MS")):
year = date.year
month = date.month
url = f"https://race.netkeiba.com/top/calendar.html?year={year}&month={month}"
html = urlopen(url).read() # スクレイピング
time.sleep(1) # サーバーに負荷をかけないように1秒待つ
soup = BeautifulSoup(html)
a_list = soup.find("table", class_="Calendar_Table").find_all("a")
for a in a_list:
kaisai_date = re.findall(r"kaisai_date=(\d{8})", a["href"])[0]
kaisai_date_list.append(kaisai_date)
return kaisai_date_list実行:
scrape_kaisai_date(from_="2023-01", to_="2023-12")出力:
['20230105',
'20230107',
'20230108',
'20230109',
'20230114',
'20230115',
'20230121',
'20230122',
'20230128',
'20230129',
'20230204',
'20230205',
'20230211',
'20230212',
'20230218',
'20230219',
'20230225',
'20230226',
'20230304',
'20230305',
'20230311',
'20230312',
'20230318',
'20230319',
'20230325',
...
'20231216',
'20231217',
'20231223',
'20231224',
'20231228']これで、netkeiba.comからレース開催日一覧を取得する関数を完成させることができました。
次回は、開催ページからrace_idの一覧を取得する方法を解説します。
補足
pd.data_range()の仕様
動画中のコードのように、from_とto_に"yyyy-mm"の形で入れると、内部では"yyyy-mm-01"と解釈されます。
from_="2023-01"
to_="2023-12"
pd.data_range(from_, to_, freq="MS")よって、freq="MS"では、2023-01-01から1ヶ月おきに2023-12-01まで取り出されますが、freq="ME"では2023-01-31から1ヶ月おきに2023-11-30までしか取り出されません。(2023-12-31は範囲外なので)
モジュール更新時の挙動
動画中 28:58〜ではscraping.pyにコードをまとめ、notebook上で
import scrapingと読み込む形にしています。
scraping.pyを更新した時、それを反映させるには、一度notebookを再起動する必要があります。(34:10あたりでは、そのため、Restartを押して更新しています)
%autoreloadという機能を使うと、notebookを再起動しなくても更新を反映させることもできるので、後々解説していく予定です。
この記事が気に入ったらサポートをしてみませんか?