
【競馬AI開発#4】馬の過去成績データをスクレイピングで取得

はじめに
この【競馬AI開発】シリーズでは、競馬予想AIを作ることを通して、機械学習・データサイエンスの勉強になるコンテンツの発信や、筆者が行った実験の共有などを行っていきます。
今回の記事は、以下の動画に補足を加えてまとめたものになります。
今回やること
今回はnetkeiba.comから「馬の過去成績データ」をスクレイピングにより集めて、一つのテーブルとして繋げていきます。

https://db.netkeiba.com/horse/2020103575/

この「馬の過去成績テーブル」は、「予測したいレースに出走する馬が、過去にどんな成績を出してきたか」という情報が記録されており、その主にその成績をもとに予測を行うことになるので、精度を出す上で肝となるデータとなります。
イメージとしては、以下のように予測対象レースの各馬に対して「馬の過去成績を集計したもの」を結合していくことで、特徴量(機械学習モデルのインプット列)にします。

動画中の実行環境
・OS: Mac OS 14.2.1
・言語: Python 3.11.4
・エディタ: VSCode 1.87.0
VSCodeやPythonのインストール方法については様々な記事で紹介されているので、適宜参照して設定してください。
また、以下のライブラリを使用しています。
beautifulsoup4==4.12.3
pandas==2.2.1
selenium==4.18.1
tqdm==4.66.1
webdriver_manager==4.0.1筆者のプロフィール
東京大学大学院卒業後、データサイエンティストとしてWEBマーケティング調査会社でWEB上の消費者行動ログ分析などを経験。
現在は、大手IT系事業会社で、転職サイトのレコメンドシステムの開発を行っています。
動画中のソースコード
※転載・再配布はお控えください
※data/html/race/に前回取得したデータをコピーしてください
1. 馬の過去成績テーブル取得の流れ
例えば上の「シュバルツガイスト」の例では、以下のようなコードによって、過去成績テーブルを取得することができます。
from urllib.request import urlopen
import pandas as pd
url = "https://db.netkeiba.com/horse/2020103575/"
html = urlopen(url).read()
pd.read_html(html)[3]出力:

ここで、netkeiba.com上における馬の過去成績ページは"https://db.netkeiba.com/horse/{horse_id}/"という構成のURLになっているので、スクレイピング対象のhorse_id一覧に対して上のコードをfor文で回すことで、目的のデータを得ることができます。
このあたりは、前回の記事で「レース結果テーブル」を取得した時とほぼ同じ流れですね。
したがってまずは、2023年に出走する全てのhorse_idを取得するところから始めます。
2. レース結果テーブルへの列追加
(動画中 5:20〜)
どのようにhorse_idの一覧を取得するかですが、レース結果ページのhtmlに出走する馬のhorse_idが書かれている部分があるので、BeautifulSoupを使ってそこから取得します。
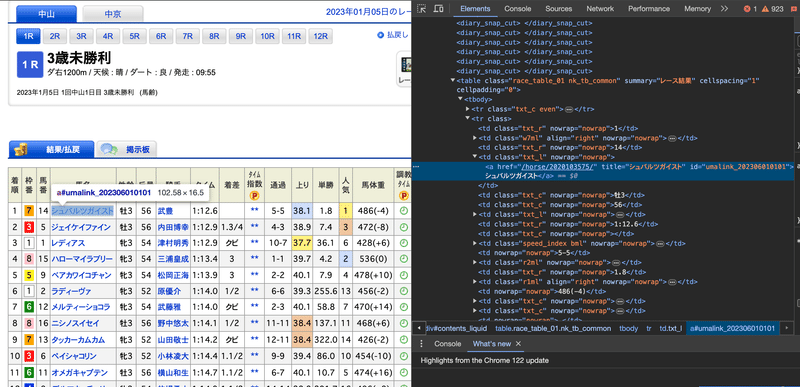
https://db.netkeiba.com/race/202306010101/
前回create_rawdf.pyの中に作成したcreate_results()関数を、以下のように書き換えます。
▼ディレクトリ構成
├── data
│ ├── html
│ │ ├── race
│ │ │ └── {race_id}.bin ・・・スクレイピングしたraceページのhtml
│ │ └── horse
│ │ └── {horse_id}.bin ・・・スクレイピングしたhorseページのhtml
│ └── rawdf
│ ├── results.csv
│ └── horse_results.csv
├── requirements.txt
└── src
├── create_rawdf.py ・・・htmlをDataFrameに変換する関数を定義
├── dev.ipynb ・・・開発用notebook
├── main.ipynb ・・・コードを実行するnotebook
└── scraping.py ・・・スクレイピングする関数を定義▼src/create_rawdf.py
import re
from pathlib import Path
import pandas as pd
from bs4 import BeautifulSoup
from tqdm.notebook import tqdm
DATA_DIR = Path("..", "data")
RAWDF_DIR = DATA_DIR / "rawdf"
def create_results(
html_path_list: list[Path],
save_dir: Path = RAWDF_DIR,
save_filename: str = "results.csv",
) -> pd.DataFrame:
"""
raceページのhtmlを読み込んで、レース結果テーブルに加工する関数。
"""
dfs = {}
for html_path in tqdm(html_path_list):
with open(html_path, "rb") as f:
try:
race_id = html_path.stem
html = (
f.read()
.replace(b"<diary_snap_cut>", b"")
.replace(b"</diary_snap_cut>", b"")
) # (※3)
soup = BeautifulSoup(html, "lxml").find(
"table", class_="race_table_01 nk_tb_common"
)
df = pd.read_html(html)[0]
# horse_id列追加(※1)
horse_id_list = []
a_list = soup.find_all("a", href=re.compile(r"^/horse/"))
for a in a_list:
horse_id = re.findall(r"\d{10}", a["href"])[0]
horse_id_list.append(horse_id)
df["horse_id"] = horse_id_list
# jockey_id列追加(※2)
jockey_id_list = []
a_list = soup.find_all("a", href=re.compile(r"^/jockey/"))
for a in a_list:
jockey_id = re.findall(r"\d{5}", a["href"])[0]
jockey_id_list.append(jockey_id)
df["jockey_id"] = jockey_id_list
# trainer_id列追加(※2)
trainer_id_list = []
a_list = soup.find_all("a", href=re.compile(r"^/trainer/"))
for a in a_list:
trainer_id = re.findall(r"\d{5}", a["href"])[0]
trainer_id_list.append(trainer_id)
df["trainer_id"] = trainer_id_list
# owner_id列追加(※2)
owner_id_list = []
a_list = soup.find_all("a", href=re.compile(r"^/owner/"))
for a in a_list:
owner_id = re.findall(r"\d{6}", a["href"])[0]
owner_id_list.append(owner_id)
df["owner_id"] = owner_id_list
df.index = [race_id] * len(df)
dfs[race_id] = df
except IndexError as e:
print(f"table not found at {race_id}")
continue
concat_df = pd.concat(dfs.values())
concat_df.index.name = "race_id"
concat_df.columns = concat_df.columns.str.replace(" ", "")
save_dir.mkdir(parents=True, exist_ok=True)
concat_df.to_csv(save_dir / save_filename, sep="\t")
return concat_df.reset_index()src/main.ipynbから以下のように実行すると、horse_idが追加されたDataFrameがdata/rawdf/results.csvに保存されます。
results = create_rawdf.create_results(html_path_list=html_paths_race)
動画の補足
create_results()中、(※1)の部分でhorse_id列を追加しています。また、ついでに騎手のid, 調教師のid, 馬主のidも(※2)で追加しています。
また、動画中では解説されていませんが、<diary_snap_cut>というタグがあると、うまく取得できないタグがあるので、(※3)で消しています。
3. 馬の過去成績テーブルの作成
(動画中 28:01〜)
上のresultsテーブルの中にあるhorse_idが、過去成績を取得したい馬idの一覧になります。
horse_id_list = results["horse_id"].unique()前回の記事で「race_id_listに含まれるraceページのhtmlを保存した」のと同じ要領で、「horse_id_listに含まれるhorseページのhtmlを保存する」関数を作成し、実行します。
▼src/scraping.py
import time
from pathlib import Path
from urllib.request import urlopen
from tqdm.notebook import tqdm
DATA_DIR = Path("..", "data")
HTML_RACE_DIR = DATA_DIR / "html" / "race"
HTML_HORSE_DIR = DATA_DIR / "html" / "horse"
def scrape_html_horse(
horse_id_list: list[str], save_dir: Path = HTML_HORSE_DIR, skip: bool = True
) -> list[Path]:
"""
netkeiba.comのhorseページのhtmlをスクレイピングしてsave_dirに保存する関数。
skip=Trueにすると、すでにhtmlが存在する場合はスキップされる。
逆に上書きしたい場合は、skip=Falseにする。
スキップされたhtmlのパスは返り値に含まれない。
"""
updated_html_path_list = []
save_dir.mkdir(parents=True, exist_ok=True)
for horse_id in tqdm(horse_id_list):
filepath = save_dir / f"{horse_id}.bin"
# skipがTrueで、かつファイルがすでに存在する場合は飛ばす
if skip and filepath.is_file():
print(f"skipped: {horse_id}")
else:
url = f"https://db.netkeiba.com/horse/{horse_id}"
html = urlopen(url).read()
time.sleep(1)
with open(filepath, "wb") as f:
f.write(html)
updated_html_path_list.append(filepath)
return updated_html_path_list▼src/main.ipynb
html_paths_horse = scraping.scrape_html_horse(
horse_id_list=horse_id_list, skip=False
)htmlが取得できたら、また前回と同じ要領で、Pandas.DataFrameの形に加工して保存します。
▼src/create_rawdf.py
import re
from pathlib import Path
import pandas as pd
from bs4 import BeautifulSoup
from tqdm.notebook import tqdm
DATA_DIR = Path("..", "data")
RAWDF_DIR = DATA_DIR / "rawdf"
def create_horse_results(
html_path_list: list[Path],
save_dir: Path = RAWDF_DIR,
save_filename: str = "horse_results.csv",
) -> pd.DataFrame:
"""
horseページのhtmlを読み込んで、馬の過去成績テーブルに加工する関数。
"""
dfs = {}
for html_path in tqdm(html_path_list):
with open(html_path, "rb") as f:
try:
horse_id = html_path.stem
html = f.read()
df = pd.read_html(html)[3]
# 受賞歴がある馬の場合、3番目に受賞歴テーブルが来るため、4番目のデータを取得する
if df.columns[0] == "受賞歴": # (※1)
df = pd.read_html(html)[4]
# 新馬の競走馬レビューが付いた場合、次のhtmlへ飛ばす
elif df.columns[0] == 0:
continue
df.index = [horse_id] * len(df)
dfs[horse_id] = df
except IndexError as e:
print(f"table not found at {horse_id}")
continue
concat_df = pd.concat(dfs.values())
concat_df.index.name = "horse_id"
concat_df.columns = concat_df.columns.str.replace(" ", "")
save_dir.mkdir(parents=True, exist_ok=True)
concat_df.to_csv(save_dir / save_filename, sep="\t")
return concat_df.reset_index()▼src/main.ipynb
# 馬の過去成績テーブルの作成
horse_results = create_rawdf.create_horse_results(html_paths_horse)これで、data/rawdf/horse_results.csvに以下のような馬の過去成績テーブルが保存されます。

動画の補足
各horseページのテーブルを
df = pd.read_html(html)[3]で読み込んだ際に、ページによってはここに受賞歴のテーブルが入っていたり、新馬の競走馬レビューが入っていたりします。
そのため、(※1)ではそのような場合の回避処理を加えています。
まとめ
ここまでで、2023年に開催された全レースの「レース結果テーブル」と、そこに出走する全ての馬の「馬の過去成績テーブル」をPandas.DataFrameの形で取得することができました。
次回は、このデータを前処理して機械学習モデルにインプットできる形にしていきます。
ここから先は

【定期マガジン】競馬AI研究所
「競馬予想AIを1から作る」ことを通して、機械学習・データサイエンスの勉強になるコンテンツの発信や、筆者が行った実験の共有などを行っていき…
この記事が気に入ったらサポートをしてみませんか?