統計的仮説検定で p 値だけでなく効果量も見ましょうねと言われる背景について

統計的仮説検定を行う際には、単に検定というフレームワークに当てはめて p 値が有意水準を下回るかどうかをみるだけでは、本来評価したいことが適切に評価できていないことがあります。
"意味のある"評価のためには、効果量や検出力もあわせて検討する必要があります。そのあたりの話をシミュレーションを交えて確認していきたいと思います。
import numpy as np
import pandas as pd
from plotnine import *
import rpy2
from scipy import stats
%load_ext rpy2.ipythonp 値だけを見てはいけないのか
例えば対応のない 2 群の平均値差の検定では、次のロジックで「差がないとはいえない」ことを論証します。
「差がない(差が 0 である)」という帰無仮説をたてる
帰無仮説のもとで検定統計量を計算する
帰無仮説のもとで検定統計量がその値をとる確率(=p値)を計算する
p 値が有意水準を下回れば、「帰無仮説のもとで非常に珍しいことがおこった」と解釈するのではなく、帰無仮説自体が間違っていると解釈し、対立仮説を採択する。
上記のように、p 値は検定において、帰無仮説が正しいと仮定したときに手元のデータから求まる検定統計量がその値となる確率のことを指します。
ここで、対応のない 2 群の差の検定 における t 値は次の式で計算されます。$${s_p^2}$$ はプールした分散、$${n_1, n_2}$$ は各群のサンプルサイズ、$${M_1, M_2}$$ は各群の標本平均を表します。
$$
t = \frac{M_1 - M_2}{\sqrt(s_p^2(\frac{1}{n_1} + \frac{1}{n_2}))}
$$
この式で注目すべきは分母の $${n_1, n_2}$$ です。t 値の計算式にサンプルサイズが入っているため、t 値はサンプルサイズの影響を受けることになります。サンプルサイズが大きくなるほど分母が小さくなるため t 値は大きくなるような関係性が見られます。
他の変数の影響を無視すると, t 値(の絶対値)が大きくなるほど p 値は小さくなるため、サンプルサイズが大きくなるほど p 値 は小さくなりやすくなる関係性にあることがわかります。
効果のある差の判断基準
サンプルサイズに影響を受ける値は効果を表すとみなすことはできません。効果のある差、すなわち意味のある差とみなせるかどうかは p 値ではなく効果量(effect size)で判断します。
効果量はいくつか種類がありますが、例えば対応のない 2 群における Cohen の d については次のように表されます。標本平均の差をプールした標準偏差を用いて標準化した値となっています。
$$
d=\frac{M_1-M_2}{s_p}
$$
2 群の差の検定であれば、効果があるかないか、意味があるかどうか、というのは平均値差を見てそれが大きいか小さいか判断するのは自然です。ただし、扱うデータの単位にこの値は依存してしまうので、比較ができるように標準化をしているわけですね。
[1] によれば、効果量には2つの群の間にどの程度の違いをがあるかを表す d族の効果量と、2 つの変数間の関係の大きさを表す r 族の効果量というグルーピングがあり検定で調べたいことに応じて適切な効果量を選択する必要があります。
d 族の標本効果量を求めるには、R の effsize パッケージを利用すると信頼区間を含めて得られます。正規分布を仮定した平均値に基づく効果量は `cohen.d()` 関数で、ノンパラメトリックで中央値に基づく効果量は `cliff.delta()` 関数が用意されています。pwr パッケージでは、比率の差の検定やカイ二乗検定、相関係数の検定における効果量をえられます。
適切なサンプルサイズの求め方
サンプルサイズが多すぎると小さすぎる差を検出してしまう、ということとなると「効果のある差」を検出するためにはどのくらいのサンプルサイズが適切なのでしょうか。
当然「効果のある差」をどの程度とするかに応じて必要なサンプルサイズは変わため、効果量は事前に決める必要があります。
加えて、サンプルサイズの設計においては検定力も決める必要があります。検定力(検出力)は第二種の過誤を$${\beta}$$としたときに $${1 - \beta}$$ で表され、「帰無仮説が誤りであるときに、正しく帰無仮説を棄却できる確率」となります。
2 群の差の検定でいえば、実際に差があるときに、差がないという帰無仮説を正しく棄却できるかどうかということで、どの程度の信頼性を持って有意差を検出できるかどうかを意味しているようなイメージとなります。

青い線は帰無仮説による分布、オレンジ線は対立仮説による分布。
効果量、検定力、有意水準の 3 つが決まれば、例えば対応のない 2 群の差の検定であれば次のようにして適切なサンプルサイズを得られます。
%%R
power.t.test(
power = .8, # 検定力
delta = 0.2, # 標準化効果量
sig.level = .05, # 有意水準
type = "two.sample", # 対応なしの2群
alternative = "two.sided" # 両側検定
)
"""
Two-sample t test power calculation
n = 526.3334
delta = 0.2
sd = 1
sig.level = 0.05
power = 0.9
alternative = two.sided
NOTE: n is number in *each* group
"""サンプルサイズを増やしていくと検定力が上がっていきます。例えば 0.2 の効果量を有意水準 0.05 で検出するときの検定力はサンプルサイズに応じて次の様に変化します。サンプルサイズ 10 ではたったの 6% しか検出できないので検定の結果の信頼度は非常に低いですが、1000 用意することができれば 99.4% で差があるときに有意差を検出することができます。基本的に信頼性の足る結果を得られるという点ではサンプルサイズが多いことは望ましいですね。(サンプルサイズを集めるのにお金がかかる場合は、必要十分なサンプルサイズとするのが一番です)
%%R
for (n in c(10, 10^2, 10^3, 10^4, 10^5)){
res <- power.t.test(
n = n,
delta = 0.2,
sig.level = .05,
type = "two.sample"
)
print(res$power)
}
"""
[1] 0.0622645
[1] 0.2902664
[1] 0.9939638
[1] 1
[1] 1
"""一方で、検定力を固定してサンプルサイズを増やすと、効果量が小さくなっていく関係性にあります。100,000 サンプルあれば 0.0039 の効果量であっても 80% で有意差が検出されてしまいます。実質意味のないような小さな差でもサンプルサイズが多いと有意差が出てしまうことは、ここからも確認できます。
for (n in c(10^2, 10^3, 10^4, 10^5, 10^6)){
res <- power.t.test(
n = n,
power = .8,
# delta = 0.2,
sig.level = .05,
type = "two.sample"
)
print(res$delta)
}
"""
[1] 0.39814
[1] 0.1253509
[1] 0.03963977
[1] 0.01252579
[1] 0.003947401
"""きちんとサンプルサイズ設計をしてデータ収集する、という実験の手続きを踏める場合はよいですが、すでに入手されているデータに対して検定を行うような場合にはこちらは注意が必要です。
シミュレーション
最後にシミュレーションをして p 値がサンプルサイズに影響を受けることを確認してみましょう。
差はあるがごく小さな差である場合
実質意味がないとみなすような極小さな差についても、サンプルサイズを増やすと有意差が検出されてしまうことを確認してみます。
ここでは実質意味のない 2 群の差の量は 0.01 と設定します。標準偏差 1 の正規分布からのサンプリングですので効果量自体も 0.01 に近しい値となります。
サンプル数は 100 で、サンプルサイズを 10 -> 1,000,000 まで変えたときの p 値を見てみます。
def simulate_ttest1(sample_size):
ts, ps, diffs = [], [], []
for i in range(100):
g1 = np.random.normal(loc=0, scale=1, size=sample_size)
g2 = np.random.normal(loc=0.01, scale=1, size=sample_size)
t, p = scipy.stats.ttest_ind(g1, g2)
diff = g1.mean() - g2.mean()
ts.append(t)
ps.append(p)
diffs.append(diff)
return ts, ps, diffs
ns = [10, 10**2, 10**3, 10**4, 10**5, 10**6, 10**7]
res = pd.DataFrame()
for n in tqdm(ns):
ts, ps, diffs = simulate_ttest1(n)
tmp = pd.DataFrame({
"sample_size": n,
"t": ts,
"p": ps,
"diff": diffs
})
res = pd.concat([res, tmp])(
ggplot(data=res)
+ geom_boxplot(aes(x="factor(sample_size)", y="p", fill="factor(sample_size)"), alpha=.6)
+ geom_hline(yintercept=0.05, color="r")
+ theme_minimal()
+ theme(figure_size=(7, 4), legend_position="none")
)
サンプルサイズが大きくなるほど p 値が小さくなっていく様子が見て取れます。だいたいサンプルサイズ 10000 くらいまでは分散が大きいですが、100000 を超えたあたりからは安定して 0.05 を下回るような形に落ち着いているように見えます。
効果量 0.01, 検出力 0.9, 有意水準 0.05 におけるサンプルサイズは 156978.6 となるため違和感のない結果です。効果量 0.01 という差が意味のない差だったとしても、これくらいのサンプルサイズを持って計算してしまうと 90% で有意差として検出されてしまうことになります。
%%R
power.t.test(
power = .8,
delta = 0.01,
sig.level = .05,
type = "two.sample"
)
"""
Two-sample t test power calculation
n = 156978.6
delta = 0.01
sd = 1
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* group
"""母集団に差がない場合
一応完全に同一の母集団でサンプルサイズを増やした場合も確認しておきます。もしこのときにもサンプルサイズを増やして有意差が出やすくなるのであれば、もう検定という手法自体が意味をなさなくなってしまいます…
def simulate_ttest2(sample_size):
ts, ps, diffs = [], [], []
for i in range(100):
g1 = np.random.normal(loc=0, scale=1, size=sample_size)
g2 = np.random.normal(loc=0, scale=1, size=sample_size)
t, p = scipy.stats.ttest_ind(g1, g2)
diff = g1.mean() - g2.mean()
ts.append(t)
ps.append(p)
diffs.append(diff)
return ts, ps, diffs
ns = [10, 10**2, 10**3, 10**4, 10**5, 10**6, 10**7]
res = pd.DataFrame()
for n in tqdm(ns):
ts, ps, diffs = simulate_ttest2(n)
tmp = pd.DataFrame({
"sample_size": n,
"t": ts,
"p": ps,
"diff": diffs
})
res = pd.concat([res, tmp])
こちらについては一定数増やしていっても p 値のとりうる値について傾向の変化は見られない結果となりました。
なお、サンプリングに伴い発生する誤差で生じた差について見てみると次のようになります。
(
ggplot(data=res)
+ geom_boxplot(aes(x="factor(sample_size)", y="diff", fill="factor(sample_size)"), alpha=.6)
+ theme_minimal()
+ theme(figure_size=(7, 4))
)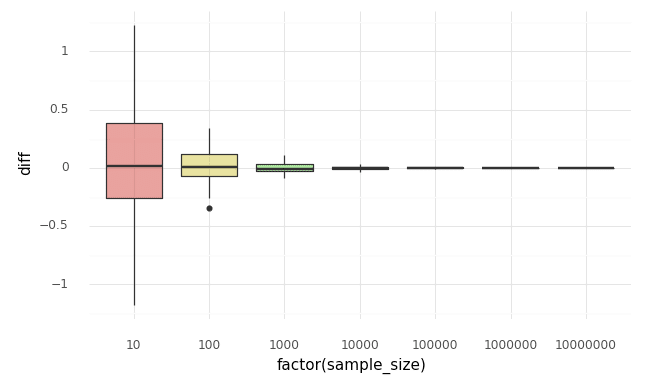
サンプルサイズが大きくなるほど、大数の法則で母集団の平均値の値(0 - 0 = 0)に収束していくことが見て取れます。0 に収束していくのでサンプルサイズを大きくしても有意差が検出されやすくなることがないわけですね。
おわりに
実際に検定を行うシーンでは、2 群の母集団が完璧に一致していることは考えづらいと思います、多少でも母集団に差があるのであれば、シミュレーション結果のようにサンプルサイズが大きすぎることで(意味がない差であるにも関わらず)有意差が出やすいことになるため、ビッグデータを扱っている際に、実験計画をせずに得られたデータで検定を行う際には効果量への意識が大事になる…ということを自分の中で確認することができました。
※ まあそもそも意味のない差であった場合には、検定をしよう、という発想にならない気がしますが…
Reference
[1] 大久保街亜, 岡田謙介. 伝えるための心理統計, 2012
[2] 豊田秀樹. 検定力分析入門―Rで学ぶ最新データ解析―, 2009
[3] 統計WEB 31-4. 検出力
最後まで目を通していただきありがとうございました。もし内容に誤りを見つけていただいた場合はご指摘いただけますと幸いです🙇♂️
この記事が気に入ったらサポートをしてみませんか?