
【EMO】次世代AIアバターが人間すぎる!音声を理解してしゃべる生成AIの最新技術

👋皆さんこんにちは!
『アリババグループ インテリジェントコンピューティング研究所』が発表したAudio2Videoの最新技術『EMO: Emote Portrait Alive』についてご紹介します!
まだ研究論文とデモが発表された段階ですが、AIアバター界にもSoraのような大きな衝撃を与えそうな技術だと感じましたので、サービスとして実装されるのが楽しみです!
今回は研究論文の要約を元にEMOがどのような技術かを簡単にまとめましたのでぜひ最後まで読んで頂けると幸いです!(研究論文の全文を確認したい方はこちらから)
『EMO: Emote Portrait Alive』とは
概要
EMOは、音声信号から表情豊かなポートレートビデオを生成する最新のフレームワークです。従来の3Dモデルや顔のランドマークを必要とせず、単一の参照画像と音声データ(話す声や歌声など)を入力するだけで、自然で表情豊かなアバタービデオを作成できます。
是非下記のEMOのデモページで個別のサンプル動画を閲覧できます。日本語の音声にもしっかりリップシンクが対応しているところにも注目です!
現在触れるデモは無いですが、Githubにソースコード置き場が用意されているので、将来的にコードが公開されるものと思われます。
どこがすごい?
EMOは、たった一枚の画像と音声から高度な表現力とリアリズムを実現する点で、既存の手法を大きく上回っています。特に、話し声だけでなく、さまざまなスタイルの歌声ビデオを生成できる能力は特筆すべき点です。さらに、中間的な3Dモデルや顔のランドマークを必要としない直接的な音声からビデオへの合成アプローチにより、シームレスなフレーム遷移と一貫したアイデンティティの保存を実現しています。
技術や手法のキモは?
EMOの核心技術は、音声データと顔の動きとの間のダイナミックで微妙な関係を捉えることに焦点を当てた、直接的な音声からビデオへの合成アプローチにあります。このアプローチにより、高度に表現力があり、生き生きとしたアニメーションを生成することができます。
手法の解説
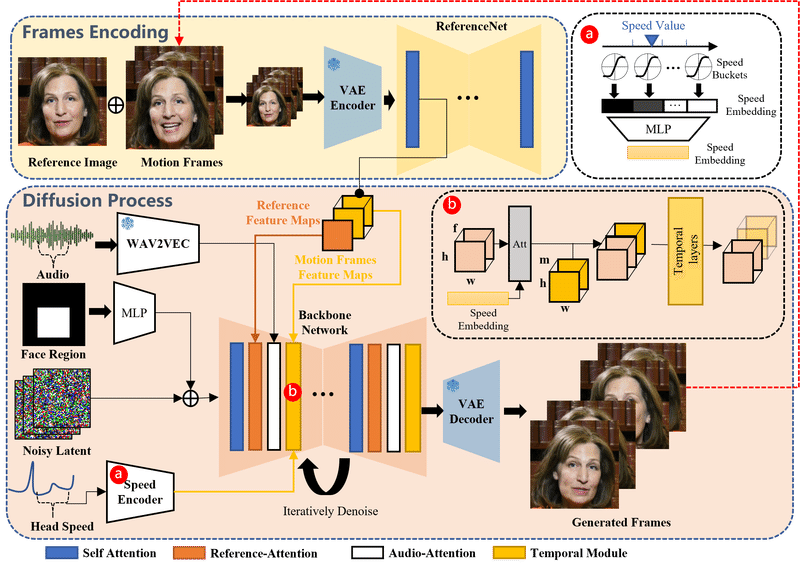
フレームエンコーディング(初期段階)
この段階では、参照画像(人物の静止画像)と動きのフレーム(動きのある画像)から特徴を抽出します。このために、「ReferenceNet」と呼ばれるシステムを使用しています。簡単に言えば、参照画像を見て、その人物がどのように見えるか(顔の特徴など)を学習し、そのデータを次の段階へと渡します。拡散プロセス(Diffusion Process)段階
この段階では、まず音声から特徴を抽出します。音声を分析して、話している人の声の高さや強さなどを理解し、これをビデオに変換するためのデータとして使用します。次に、この音声データと初期段階からの画像データを組み合わせて、表情や頭の動きを含む動画を生成します。このプロセスでは、音声と参照画像の両方に注目しながら、人物が自然に話しているかのような動きを作り出すために、「Reference-Attention」と「Audio-Attention」という二つの注目機構を使用しています。
話している声の高さや強さを理解してアニメーションに反映しているのはデモ動画でも見て取れます。アクセントが強くなる部分では眉を顰めたり、大きく頭を動かしたりしています。
従来の課題の解決
EMOが解決しようとしている主な課題は、従来の技術が人間の表現の全範囲を捉えきれていないこと、および個々の顔のスタイルのユニークさを表現できないことにあります。これらの課題に対して、EMOは表現力豊かでリアリスティックなビデオ生成を実現する新しいアプローチを提供しています。
従来のAIアバターでも一枚絵からしゃべる動画を生成できていましたが微妙に顔が違ったり、部分的に崩れたりといったこともありましたが、EMOの場合はちゃんと似た顔かつ、一貫性のある動画ができていることが分かります。
EMOの活用例
オンライン教育
EMOを用いて、教師の表情や声色を忠実に再現した講義ビデオを作成することで、より効果的なオンライン学習環境を実現できます。バーチャルコミュニケーション
EMOで生成したアバタービデオを用いることで、より自然で感情豊かなオンラインコミュニケーションを実現できます。エンターテイメント
EMOで生成した歌声ビデオを用いることで、バーチャルアーティストやボーカロイドの表現力を大きく拡張できます。
ゲームのキャラクターが言語設定によって適切なリップシンクをするようになるなど、高いレベルの没入感を生み出します。
まとめ
これまでも少ない素材からアバターを生成するAIサービスはありましたが、ここまで高いレベルで元画像の特徴に忠実かつ、人間らしい動きを再現している技術はEMOが初めてだと思います。
LLMが生成したテキストから音声と画像を生成し、その素材からキャラクターがしゃべりだす…このワークフローをAIエージェントが全自動化する日も近いと思うと、ワクワクすると同時に恐ろしいですね…!
最後まで読んで頂きありがとうございました!
お楽しみいただけましたら是非フォローやスキをしていただけると次の投稿への励みになります!🙇♂️
■AIBridge Labについて
AIBridge Lab(エーアイブリッジ ラボ)では生成AI全般の利用方法に関しての情報を発信しています。同じように生成AIをビジネスや創作に役立てたいという方と積極的に繋がりたいと考えていますので、ぜひフォローやコメントなどを頂けると嬉しいです!
ご依頼等は以下のメールアドレスまでお気軽にお問い合わせください。
ai_business@doerstokyo.jp
AIBridge Lab こば
皆さまの温かいサポートのおかげで、活動を続けることができています。もしよろしければ、引き続き支援をお願いできますと幸いです。より質の高い記事投稿に励みます!