つくば市の人口についての分析(全国との比較)

こんにちは。つくばに住む研究者です。
今回は国勢調査をもとに、つくば市の人口事情を全国の市区町村と比較したいと思います。
筆者は少し前に東京からつくば市に移った移住者です。個人的な感覚ですが、つくば市には市外からの移住者が多いように感じています。果たしてそれはどの程度のものなのか、国勢調査の結果をもとに見ていきます。
記事の前半は分析結果を、記事の後半では統計やプログラミングに詳しくない方に向けて詳細手順や補足に触れようと思います。導入についてどこまで細かく書けば良いか試行錯誤の最中ですので、わかりにくい点などについてご指摘いただければ嬉しく思います。
分析
国勢調査のデータについて
今回扱うデータは先にも述べたとおり、国勢調査の結果です。
国勢調査結果はe-statという日本の政府統計ポータルサイトから手に入れることができます。今回は2022年07月22日に公開された西暦2020年の調査結果を使用します。左下に見える'EXCEL'の部分からダウンロードできます。
国勢調査の結果はエクセルのデータで配布されているので、PCにMicrosoft EXCELが入っていればそのまま分析することもできますが、今回はクラウドで利用できるプログラミング環境であるGoogle Colabを利用して分析します。Google ColabはGoogle社が提供するプログラミング環境で、Googleが管理する計算資源を利用してPythonやRなどのデータ分析用のプログラミング言語を無料で手軽に実行することができます。(Colabについての詳細はこちらを参照してください。本項後半でも使い方について簡単な説明します。)
今回あつかう国勢調査の結果には、全国、都道府県、市区町村ごとに様々なデータが整理されています。すべてを載せると長くなりすぎるので、下記にその情報の一部を紹介します。
人口総数
男性の数
女性の数
5年間の人口増減数
5年間の人口増減率
面積
人口密度
平均年齢
日本人数
外国人数
総世帯数
などなど。
つくば市の人口は増えてる?
それでは実際に、つくば市の人口増加率を全国の市区町村と比べてみます。国勢調査データから、全国や県、政令指定市下の区を除いた市区町村の自治体に絞り込みし、総人口と5年間の人口増加率の列を取り出し、増加率の降順(多い順)で並び替えをします。
以下はColabで実行できるPythonのコードです。データに不備の無い全国の1715の市区町村の5年間の人口増加率の上位および下位の自治体はこんな感じになりました。
from google.colab import drive
import pandas as pd
drive.mount('/content/drive')
#ダウンロードした国勢調査データの置き場所
dir_path = '/content/drive/MyDrive/Colab Notebooks/Data/2023_05'
#エクセルの読み込み
df_all = pd.read_excel(dir_path + 'major_results_2020.xlsx')
#分析したい列の取り出し
df_crop = df_all[['都道府県名', '都道府県・市区町村名', '市などの別\n(地域識別コード)','総数','5年間の人口増減率']]
#全国や県レベル、政令指定都市下の区のデータを除外する
df_crop = df_crop[df_crop['市などの別\n(地域識別コード)']!='a']
df_crop = df_crop[df_crop['市などの別\n(地域識別コード)']!=0]
#不完全なデータを除外する
df_crop = df_crop[df_crop['総数']!='-']
df_crop = df_crop[df_crop['5年間の人口増減率']!='-']
#人口増減率で並び替え
df_crop = df_crop[['都道府県名','都道府県・市区町村名','総数','5年間の人口増減率']]
df_crop.sort_values('5年間の人口増減率',axis=0,ascending=False)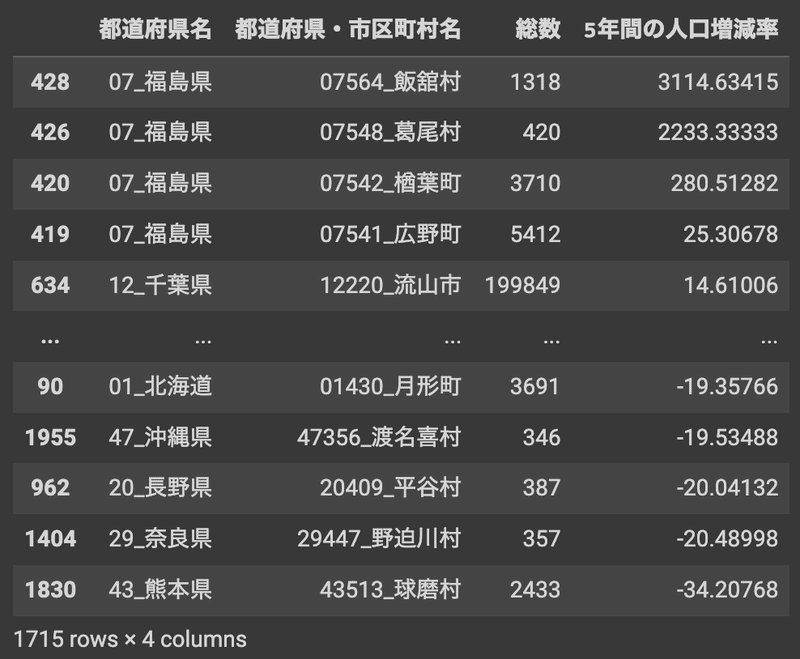
増加率では福島県にある市区町村が突出して多い結果となりました。これらの都市は福島第一原子力発電所の近隣にあり、2011年以降は避難のために多くの住人が町を離れていましたが、現在では段階的に戻っているためと思われます。
人口が10万人を超える都市に絞って見てみましょう。
df_crop_big_cities = df_crop[df_crop['総数'] >= 100000]
df_crop_big_cities.sort_values('5年間の人口増減率',axis=0,ascending=False)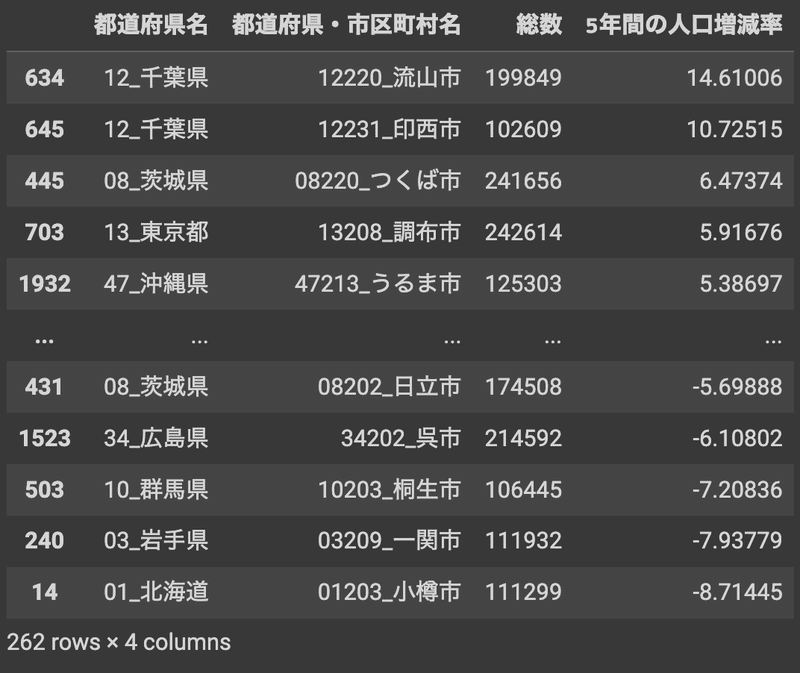
人口が10万人を超える全国262の自治体の中で、千葉県の流山市が5年間で14%を超える増加率となっています。流山市が人気があると最近よく聞きます。我らがつくば市は全国で3位という結果になり、やはり人口増加率が高い市であることがわかりました。
つくば市は子供が多い?
筆者の個人的な感覚では、つくば市は特に子育て世帯が多い街であるように感じています。子供のいる世帯の割合についても調べてみましょう。
国勢調査結果には自治体毎の一般世帯の数と、子供のいる世帯の数についての数も含まれています。子供のいる世帯の数については、"夫婦と子供から成る世帯"、 "男親と子供から成る世帯"、 "女親と子供から成る世帯"の三種類があります。これらの三種類は相互排他であるため、合算すれば子供がいる世帯の全数になり、それを総世帯数で割れば「子供がいる世帯の割合」が計算できそうです。
データに不備の無い全国の1715の市区町村について、子供がいる世帯の割合の上位および下位の自治体はこんな感じになりました。
#興味のある列の取り出し
df_crop = df_all[['都道府県名', '都道府県・市区町村名', '市などの別\n(地域識別コード)','総数',
'総世帯','夫婦と子供\nから成る世帯', '男親と子供\nから成る世帯', '女親と子供\nから成る世帯']]
#全国や県レベルのデータを除去
df_crop = df_crop[df_crop['市などの別\n(地域識別コード)']!='a']
#政令指定都市下の区を除去
df_crop = df_crop[df_crop['市などの別\n(地域識別コード)']!=0]
#不完全なデータの除去
df_crop = df_crop[df_crop['総世帯']!='-']
df_crop = df_crop[df_crop['夫婦と子供\nから成る世帯']!='-']
df_crop = df_crop[df_crop['男親と子供\nから成る世帯']!='-']
df_crop = df_crop[df_crop['女親と子供\nから成る世帯']!='-']
#子供のいる世帯数の列を追加
df_crop['子供のいる世帯数'] = df_crop['夫婦と子供\nから成る世帯']+df_crop['男親と子供\nから成る世帯']+df_crop['女親と子供\nから成る世帯']
#子供のいる世帯の割合の列を追加
df_crop['子供のいる世帯の割合'] = df_crop['子供のいる世帯数']/df_crop['総世帯']
#子供のいる世帯数で並び替え
df_crop = df_crop[['都道府県名','都道府県・市区町村名','総数','総世帯','子供のいる世帯の割合']]
df_crop.sort_values('子供のいる世帯の割合',axis=0,ascending=False)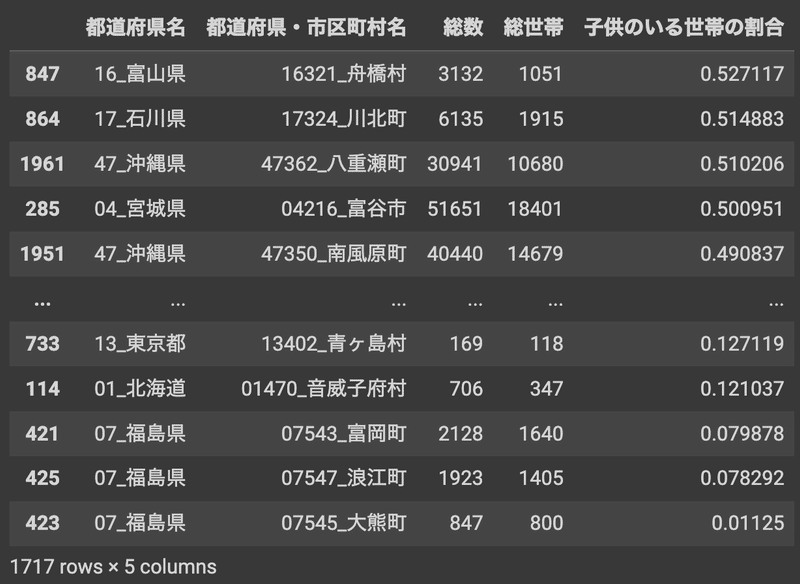
子供のいる世帯の割合が最も高かったのは富山県の船橋村でした。沖縄からは2つの町が上位5位に入っています。一方で子供のいる世帯の割合が最も低いのは福島県にある3つの自治体で、大熊町ではその割合は1%強という結果でした。
こちらも人口が10万人を超える都市に絞って見てみましょう。
df_crop_big_cities = df_crop[df_crop['総数'] >= 100000]
df_crop_big_cities.sort_values('子供のいる世帯の割合',axis=0,ascending=False)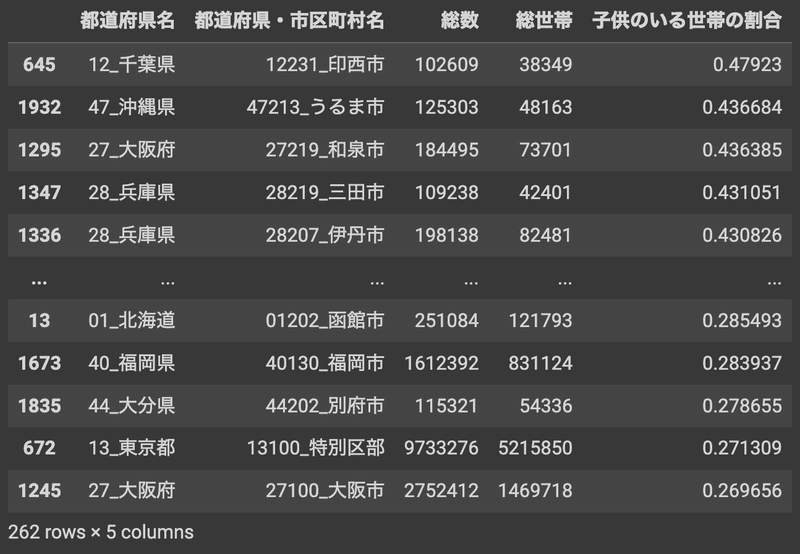
10万人を超える自治体の中で子供のいる世帯の割合が最も高かったのは千葉県の印西市でした。千葉県の印西市は先に調べた5年間での人口増加率も高い自治体でした。印西は最近ではアマゾンやグーグルなどの大手IT企業がデータセンターを建てていることで話題です。一方で割合が低かった自治体には福岡市、東京都の特別区部(東京23区)、大阪市などの大都市が目立ちます。
さて、つくば市の順位も確認してみましょう。
df = df_crop_big_cities.sort_values('子供のいる世帯の割合',axis=0,ascending=False).reset_index()
df[df['都道府県・市区町村名'].str.contains('つくば市')]
つくば市の子供のいる世帯の割合は約31%で、10万人以上が住む262の自治体の中で241位という結果でした。(上記の再左列には240とありますが、0から始まるため+1になります。)
つくば市の子供のいる世帯の割合は、筆者の感覚に反してかなり低い数字となりました。つくば市は特に子育て世帯が多いというわけでは無いようです。もともと筆者は東京での生活が長かったため、相対的に高く感じただけなのでしょうか?それとも「子供が多い」と感じることには、他に何か理由があり、世帯数を見るのは不適切なのでしょうか?
今度は世帯数ではなく、子供の人口の割合を確認してみましょう。国勢調査の結果には、15歳以下の人口構成比も整理されています。10万人以上の市区町村について、15歳以下の人口構成が多い順に15位まで見てみます。
#興味のある列の取り出し
df_crop = df_all[['都道府県名', '都道府県・市区町村名', '市などの別\n(地域識別コード)','総数','15歳未満.1']]
#全国や県レベルのデータを除去
df_crop = df_crop[df_crop['市などの別\n(地域識別コード)']!='a']
#政令指定都市下の区を除去
df_crop = df_crop[df_crop['市などの別\n(地域識別コード)']!=0]
#不完全なデータの除去
df_crop = df_crop[df_crop['総数']!='-']
df_crop = df_crop[df_crop['15歳未満.1']!='-']
#人口10万人以上の自治体について、15歳未満の人口の割合で並び替え
df_crop_big_cities = df_crop[df_crop['総数'] >= 100000]
df_crop_big_cities.sort_values('15歳未満.1',axis=0,ascending=False)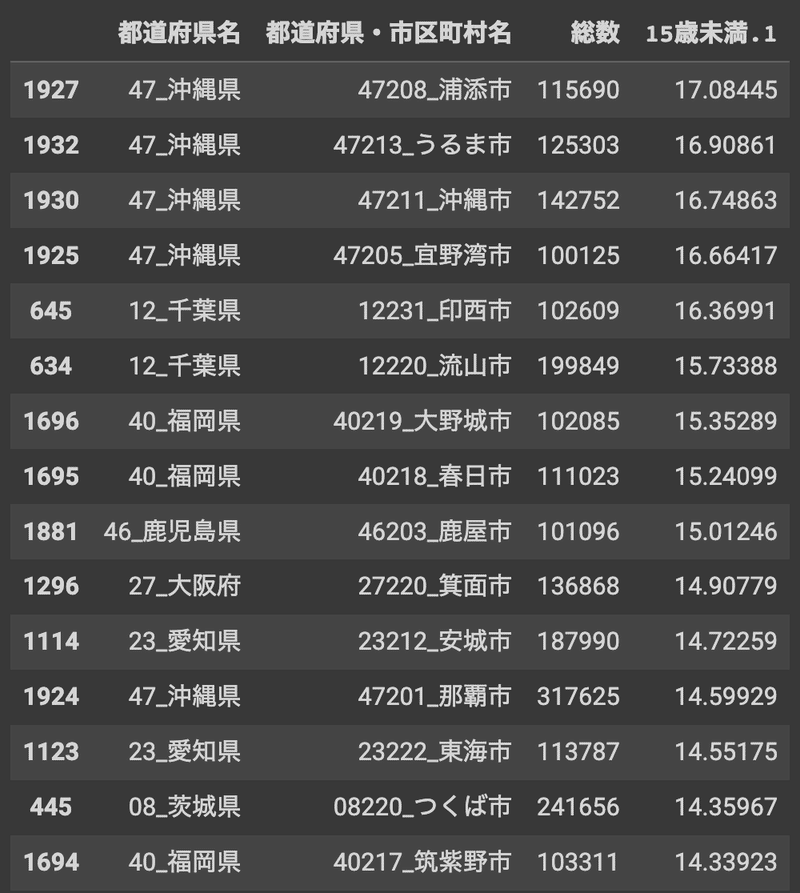
つくば市は14位に入っています。これは少し興味深い結果になりました。
上位5つの自治体のうち4つを沖縄が占めています。人口増加率でも上位だった千葉県印西市や流山市は15歳以下の人口比率でも多いことがわかりました。
つくば市は子供がいる世帯数では大都市と同程度の数字でしたが、子供の人口構成比は14.35%となり人口が10万を超える262の自治体中の中でもかなり高い方であることがわかりました。つくば市は「15歳以下の子供がいる世帯の割合は大都市と同程度であるが、人口のうち子供が占める割合は全国の中でも高い」と言えます。二人以上の子供がいる世帯が若年人口の構成比を押し上げていることが伺えます。
つくば市は支援すべき子供の数が多い一方で子育て世帯はマイノリティです。つくば市の子育て世帯が持つ市政への影響力は他の自治体と比較しても弱い可能性があり、子供の支援に関する政策を実現する上では不利になりそうです。
解説など
ここではプログラミングやデータ分析が未経験の方が、本日紹介した分析を行う際に役立つ情報をまとめたいと思います。
Google Colabの使い方など
Google ColabはGoogle社が提供するクラウドのプログラミング環境で、Googleが管理する計算資源を利用してPythonやRなどのデータ分析用のプログラミング言語を無料で手軽に使うことができます(Colabについての詳細はこちらを参照してください)。
自分の手元のPCでブラウザを開きプログラミングのコードを実行(送信)すると、その計算はGoogleの管理するPCで実行され、その結果を自分の手元のPCで確認することができるので、ブラウザが動くだけのPCとインターネット環境があればどこでも扱えます。分析のために高価なPCを購入する必要がないので非常に便利です。Google Colabの画面はこんな感じです
内側の黒いBOXに式を入れて実行すると、その結果がBOXの下部に表示されます。試しに1+1を入力し、実行(Shift+Enter)しましょう。
1+1の計算結果である'2'が表示されました。
先にも述べたとおりColabはクラウドのプログラミング環境ですので、扱うデータもクラウドに置かなければいけません。Colabを使うアカウントのGoogle Driveに先ほどのEXCEL(.xlsx)ファイルをアップロードします。今回はGoogle Driveの'My Drive'のフォルダの中にある'Colab Notebooks'のフォルダの下に’Data'という名前のフォルダを作り、更にその中にある'2023_05'という名前のフォルダの中にアップロードしました。フォルダのパス(場所)は'MyDrive/Colab Notebooks/Data/2023_05'となります。
Google Colabからアップロードしたファイルを確認します。まずはGoogle DriveにアクセスするためにGoogle Colabのdriveモジュールをインポートし、自分のdriveをマウント(アクセス出来るようにすること)します。具体的には以下のコードを実行すれば自分のColab環境からDriveにアクセスできるようになります。下記のコードを実行すると、アクセスの許可が求められますので内容を確認して問題なければ[OK]を押してください。
from google.colab import drive
drive.mount('/content/drive')先ほどの国勢調査結果のファイルを読み込んでみます。エクセルのデータをPythonで分析するにはPandasというモジュールを使います。エクセルの操作に慣れている方からすると「なんじゃそりゃ」という感じではありますが、慣れると非常に早く、高度なデータ分析が出来るようになります。Pandasでエクセルのデータを読むには、次のようにします。
import pandas as pd
df_all = pd.read_excel('/content/drive/MyDrive/Colab Notebooks/Data/2023_05/major_results_2020.xlsx')これで、df_allという名前のオブジェクトにエクセルのデータが入りました。実際にデータの中身を見てみましょう。データの冒頭の部分を見るには、次のようにします。
df_all.head(3)これはエクセルのデータを読み込んだdf_allという名前のオブジェクトが持つ.headというメソッドを実行しています。その際に'3'という引数を与えることで、「頭から3つ目までのデータを表示する」という操作を実現します。結果は次のようになります。

今回はこの表に対して諸々の計算や表示順序を操作する処理を行いました。
少し長くなりましたので、今回の記事で行った列の抽出や変形などのデータフレーム(df)の細かい操作についての解説は次回以降の記事に回したいと思います。
それでは。
この記事が気に入ったらサポートをしてみませんか?