
MapReduce with Python Example

MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster. (Wikipedia: https://en.wikipedia.org/wiki/MapReduce) Most big data analysts don't write mapReduce and instead writes Hive queries or SparkSQL that sits on top of mapReduce in your Hadoop clusters. But for the purpose of education and understanding the concept of mapReduce, we should try implementing and learning it with a few easy exercises.
So, let's get our hands dirty with mapReduce. We will be counting the number of times a movie is watched by each person with the dataset, movies.tsv. The codes provided here are written in Python, so if you are new to Python, I suggest you to look up the syntax. MapReduce can be written with Java, but for the purpose of simplicity and readability, we're gonna stick with Python. But before we start, we need to install the open-source mapReduce library, MRjob, to carry out mapReduce over a dataset. If you haven't had MRjob installed in your pc, I suggest you use pip3 to install it. Please download the dataset file (movies.tsv) below as well.
pip3 install mrjob
File format of movies.tsv
userId movieId tag timestamp
18 4141 Mark Waters 1240597180
65 208 dark hero 1368150078
...Copy the following code to a file (countMoviesWatched.py) or whatever name you fancy.
#countMoviesWatched.py
#Counting the number of times a movie is watched from movies.tsv
from mrjob.job import MRJob
from mrjob.step import MRStep
class countMovie(MRJob):
def steps(self):
return [
MRStep(mapper=self.mapper_get_movieID,
reducer=self.reducer_count_movieID)
]
def mapper_get_movieID(self, _, line):
(userID, movieID, tag, timestamp) = line.split('\t')
yield movieID, 1
def reducer_count_movieID(self, key, values):
yield key, sum(values)
if __name__ == '__main__':
countMovie.run()When countMovie is run, steps inherits a job from MRJob. The job here contains a mapper and a reducer, so when the MRStep is initialized, it kicks off the mapper (mapper_get_movieID) and then the reducer (reducer_count_movieID) accordingly. mapper_get_movieID maps the movieID (key) to 1 and the reducer reduces and adds up the number of 1s over the correspond key. This will give us the number of times a movie is watched.
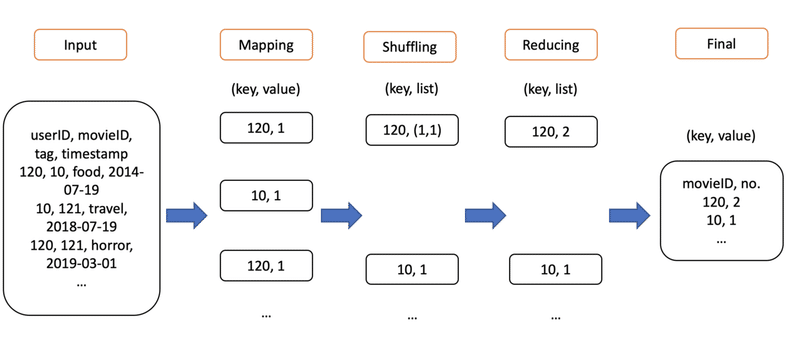
python3 countMoviesWatched.py movies.tsvTry running the command above and you will see something like this.
movieId no. of times a movie is watched
"5009" 3
"5010" 4
"5012" 3
"5013" 14
"5014" 1
"50147" 1
"5016" 3
"5021" 1
"5026" 2
"5027" 1
"5032" 3
"5033" 4
"5034" 4
"5035" 1
....We can try sorting the output to find out the three most watch movies in our dataset with the sort command.
python3 data.py movies.tsv | sort -k 2 -gIt looks like movies with the ID "1197", "318" and "2571" are the three most watched movies.
movieId no. of times a movie is watched
....
"356" 24
"48774" 25
"541" 25
"63082" 25
"916" 25
"2028" 26
"780" 26
"260" 27
"4226" 28
"79132" 28
"58559" 29
"44191" 37
"4878" 37
"2959" 38
"4993" 38
"2571" 41
"318" 41
"1197" 45I hope this tutorial will help you understand the concept of mapReduce. Please check the documentation of MRjob for further information.
The dataset movies.tsv was downloaded from MovieLens. MovieLens is a website that provides free online datasets for machine learning or big data analytics practices.
この記事が気に入ったらサポートをしてみませんか?