画像生成AIについて(2)

1.「テキストエンコーダ」と「画像生成器」について
前回「画像生成AI」のしくみについて説明しておりましたが、今回はその仕組みの中で出てきた「テキストエンコーダ」と「画像生成器」について説明したいと思います。
2.「テキストエンコーダ」とは
テキストエンコーダとは、「テキストをモデルが処理しやすい形に変換する」という役割をするものであり、具体的には入力テキスト(クエリ)をベクトルに変換する際に、このベクトルに「クエリを画像で表現するとしたら、どんな画像になるか」を※UーNETで使う潜在的なテキスト埋め込みにマッピングします。
※UーNET
⇒画像のセグメンテーション(物体がどこにあるか)を推定するためのネットワーク
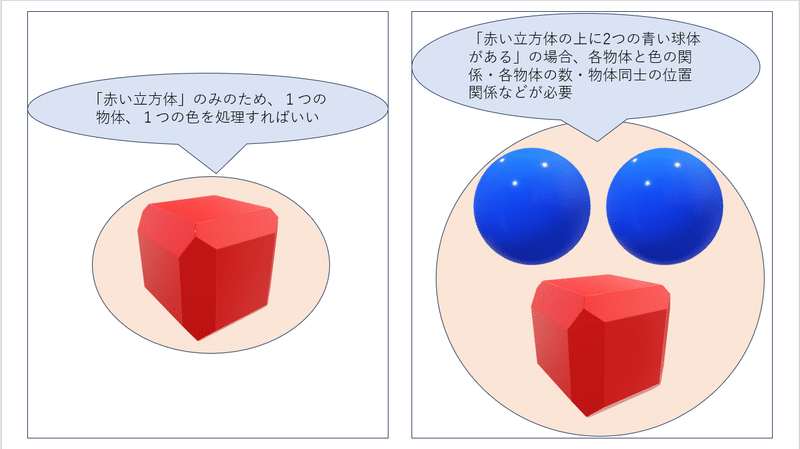
たとえば、「立方赤い体」というクエリであれば、それを理解して画像に表現することはあまり難しくないと思います。しかし、もう少し複雑な「赤い立方体の上に2つの青い球体がある」というクエリだった場合、正確な画像を生成するためには、各物体と色の関係・各物体の数・物体同士の位置関係などの要素を理解する必要があります。ここの理解が不正確だと、仮に画像生成器がどれほどきれいな画像を生成できたとしても、色や数や位置の関係があべこべな画像が生成されてしまいます。
3.「画像生成器」
画像生成器とは、「テキストエンコーダから渡される入力テキストの意味にあった画像を生成する」という役割をするものであり、ディープラーニングと呼ばれる機械学習の手法が取り込まれていることが一般的です。画像生成器のモデリングには何種類か方法があり、一部について紹介したいと思います。
①VAE(変分オートエンコーダ)
VAE(Variational Auto Encoder、変分オートエンコーダ)とは、訓練データを利用した画像生成器の仕組みで、訓練データと類似するデータの生成を可能にします。
VAEの特徴としては、潜在変数として確率分布に組み込めることが挙げられます。
一般的なオートエンコーダでは、入力テキストを画像に変える前段階における潜在変数の構造については、明らかにできません。
VAEでは確率分布という明瞭な構造があるため、よりテキストから創造されるイメージが妥当性の高いものとして表示されます。
②GAN(敵対的生成ネットワーク)
GAN(Generative Adversarial Networks)とは、生成したデータを本物と繰り返し比較・判定することで、より自然なイメージを生成する仕組みです。本物と比較・判定することで、テキストで示される特徴を定量化することも可能です。
この特徴を活かすと、実際には存在しないものも自動的に生成でき、データの信憑性とクリエイティブ、テキストの独自性を兼ね備えた画像として表示できるようになります。
③DALL・E
ChatGPTを発表したことで一躍知名度が急上昇したOpenAI社が発表した画像生成モデルが、DALL・Eです。
情報量が多い画像を離散変分オートエンコーダで1/192まで圧縮し、元々の品質と同じ情報量の画像としてデコーダで復元します。復元された画像と、最初に入力されたテキストデータの対応関係を学習し、適切な構成になるように画像を調整して完成させます。
この学習の工程にはTransGANと同じくTransformerが用いられています。
その他にも、「StyleGAN/StyleGAN2」など様々なものがありますので興味のある方は調べてみてください。
4.まとめ
テキストエンコーダ」と「画像生成器」について、簡単にですが説明させていただきました。
どちらの処理も膨大なデータを自ら学習、分析する必要があるため、自分で調べているうちに実際に我々が画像生成AIを使えるようになるにはそれなりにコストがかかっているということがわかりました。
5.参考
この記事が気に入ったらサポートをしてみませんか?