
LLMを活用した、ユーザーの曖昧な課題から対話形式で学習コースを探せるチャットボット開発の道のり

はじめに
こんにちは!グロービスのデジタルプラットフォーム部門データサイエンスチームの機械学習エンジニアの田邊です。
グロービス学び放題では、生成AIを活用した新たな学習支援に向け、様々な試みを進めています。
その一環として「学びナビ(β)」というAI(ChatGPT)との対話形式で学習コースを探すことのできる機能をグロービス学び放題のWeb版限定で公開していますが、今回はその開発からリリースまでの道のりについてご紹介します。

背景にあった課題
「ユーザーが持つ曖昧な学びの課題から、マッチするコースを提案したい」というニーズに対するソリューションとして、メンターとの対話を通じて課題を深掘りし、学習コースを推薦するというプロセスが効果的であるという知見があり、それをサービスの中で実現するためにチャットボットを使えないかという構想がありました。
第一弾の検証においては、全ての対話フローの中で選択肢を用意し、選択肢の組み合わせによって定められたコースを提案するというチャットボットを作り、リリースしましたが、その時には以下のような課題がありました。
選択肢の組み合わせのパターン数に対して、推奨するコースのパターンを十分用意することができていなかった。
ユーザーが持つ課題に当てはまりそうな選択肢を全て網羅して用意することは難しい。
そのため、選択肢式のチャットボットでは運用していくのが難しそうという状況でした。
そのような状況の中、2022年12月にOpenAIがChatGPTをリリース、そして2023年3月にはそのAPIが公開されました。
これらを受け、対話形式でユーザーの意図を解釈するという課題に対する実現可能性がグッと高まった感覚があり、アプローチ第二弾として「ユーザーに課題を自由入力してもらい、その内容に基づいて学習コースを推薦する」という内容で具体的に検討を進めることになりました。
アイデアのプロトタイピング
曖昧な学びの課題というのは、例えば以下のようなものです。
「独立しても困らないスキルを身に付けたい」
「今後のキャリアを考えると基礎スキルに不安を感じる」
「最強になりたい」
多くはユーザー自身の漠然とした成長意欲・危機感といったところから生じていると思われるもので、抽象度が高く、特定の学習コースと対応づけるにはもう少し具体的な情報が必要であるようなものです。
そこで「ChatGPTを、曖昧な学びの課題を解釈させ、より具体的な課題に変換させるためのインターフェースとして活用できないか」という発想のもと、以下のようなアプローチのプロトタイピングを進めました。

これは下記論文のHyDE(Hypothetical Document Embeddings)というアプローチとして提案されている内容と同様の発想で、ユーザーの抽象度の高い入力内容をそのままクエリに使用するのではなく、ChatGPTによるレスポンス(解釈結果)と合わせたものをクエリとして使用し、関連するコースを抽出するというものになります。
デモアプリの開発〜ユーザーインタビュー
プロトタイプの構想がある程度固まったら、デモンストレーションして検証できるよう、以下のようなStreamlitを用いた簡易的なデモ用Webアプリを作りました。

プロトタイプ開発の段階では、コースの抽出には
形態素解析によるトークン作成
Word2Vecによるembedding作成
cosine類似度ベースの抽出
というシンプルなアプローチを試しており、抽出結果に対する改善の余地はあるものの、定性的な精度はそこまで悪くない印象だったので、社内向けにもデモを共有し、フィードバックを得ることにしました。
すると、ちょうど同チームのデータサイエンティストの方が「ユーザーがグロービス学び放題でどのようなコース探しの課題を抱えているか」というテーマの調査に取り組まれていて、その一環でユーザーインタビューを計画されており、せっかくなのでインタビューの中でプロトタイプのデモを行い、価値の検証を行ってみようとご提案いただいて、デモを組み込んだインタビューを数件実施することができました。
その後、インタビューの中でデモをお見せしたユーザーの方からは、以下のようなフィードバックが得られました。
ポジティブなフィードバック
同じコースでも、自分で眺めて見つけた場合と比べて、AIからの推薦があれば見てみようという気になる。
入力、返答、推薦されたコースに一貫性があると、コースを見ようと思う。
改善ポイントに関するフィードバック
なぜこのコースが推薦されたかといった、理由もわかると良い。
推薦されたコースを見るべきかを判断するために、サムネやカテゴリといった情報も一緒にわかると良い。
ネガティブなフィードバック
このようなツールがあれば使ってみたいと思うが、コース一覧のザッピング・検索機能など普段のコースの探し方の代替手段になりそうとまでは言えず、結局慣れている探し方を優先することになりそう。
何を入力したら良いか悩みそうで、入力するにしても短文やキーワードで済ませたいと感じる。
これらのフィードバックを踏まえ、β版リリースに向けた開発を進めていきました。
β版開発〜リリース
大枠としては以下の開発フェーズに沿って、アジャイルに進めていきました。
カスタマージャーニーマップ(ユーザーストーリーマッピング)
インタビューの結果を加味した、機能を利用するユーザーのペルソナを定義し、そのユーザーが機能を利用する過程で、どのように心理状態が移り変わるかをカスタマージャーニーマップとして、行動ステップごとに言語化し、ユーザーストーリーを設定していきます。
その中でプロトタイプにおいて実現できていない箇所を特定し、優先度をつけながら開発タスクとしてマッピングしていきます。こうすることで、ペルソナの課題解決に向けて、各機能を作る動機を明確にすることができます。
この辺りの作業は、UXデザイナーの方に主導してもらいながらプロジェクトメンバー内で議論しながら進めていきました。
対話フローやUIのデザイン
ある程度ユーザーストーリーのマッピングが出来てきたら、対話フローを具体的にデザインしていきます。
とはいっても、既にプロトタイプのフローでもある程度ユーザーストーリーは満たせている状態でもあったため、1から作り直すといったことはせず、そこをベースとして作っていくことにしました。
以下でご紹介しますが、今回対話サーバーの構築にGoogle Cloud Platform(以下GCP)が提供するDialogflow CXというサービスを利用することにしたので、Dialogflow CXの仕様の中で実現できそうな範囲を見極めながらデザインを進めました。
また、対話フローの開発&レビューは、ユーザーストーリーと見比べながら素早く修正を行えるよう、Dialogflowが提供するDialogflow Messengerによるインターフェースを用意し、サービスの開発環境にデプロイしてもらって、実際にプロジェクトメンバー内で触りながら進めていけるようにしました。
また、チャットボットで使用するアイコンやインターフェースのデザインなどもデザイナーの方に主導していただきながら進めていきました。

各機能の開発・ブラッシュアップ
対話フローがある程度固まってきたら各機能の開発またはブラッシュアップ作業を中心に進めました。
細かいものから大きなものまで、多種多様なタスクがありましたが、以下いくつかピックアップしてご紹介します。
リリースまでの開発
リリースまでには様々な領域においてのタスクがありましたが、今回は私が担当していた対話サーバー側の開発を中心に、開発トピックをいくつかピックアップしてご紹介できればと思います。
Dialogflow CXの導入
対話サーバーとしてGCPのサービスのDialogflow CXを使用しています。
主な理由としてはグロービスではデータ基盤の運用をGCP上で行なっており、同じGCP上のサービスだとデータ連携がしやすいからというところになります。
その他にも、
Webhook(Cloud Functions)による外部API連携が可能
入力に対する対話の分岐作成などに活用できるNLUエンジン搭載
BigQueryへのログエクスポート機能
複数の対話フローの環境を作成可能&バージョニング機能
などがあり、対話フローの開発や運用上の負担を削減することができる機能が多くあるのも良い点だと思います。
本記事で紹介しているチャットボットの開発時にはまだリリースされていませんでしたが、最近ではVertex AI Conversationという生成AIとの統合を行うための機能も追加され、生成AIを活用したより高度な対話機能を作ることも可能になってきています。

プロトタイプからの改善1: 入力文とコースとの紐付けの精度改善
ユーザーの入力文に対してはプロトタイプと同様にChatGPTによる解釈結果をまずは生成させるところは変わりませんが、その後のコースを抽出する仕組みの部分を、Word2VecからOpenAIの提供するEmbeddingsの一つである、text-embedding-ada-002 によるembeddingを作成し、ベクトルインデックスを活用する方法に変えました。
ベクトルインデックスの構築には、ここではLlamaIndexを使っています。 特に大きな理由がある訳ではないですが、強いて言えば、今回はベクトルインデックスの構築とクエリ機能のみが必要であった中、開発当時LlamaIndexはLangChainなど他の同系統のツールに比べてベクトルインデックス機能に特化している印象があったというのが主な理由となります。
この変更の結果、コース抽出の精度は定性的にはプロトタイプのものよりもかなり良くなりました。
運用の流れとしては、コース一覧のベクトルインデックスを事前に構築しておき、本番ではユーザーの入力文とChatGPTによる解釈結果を合わせてクエリとして投げられるようなAPIサーバーをデプロイします。
この辺りはVertex AI Pipelinesやモデルのデプロイ&オンライン予測の仕組みを提供するPrediction機能を活用して実現しています。
ベクトルインデックスと対話サーバー間はWebhookによって連携される形になり、全体の概観は以下のようになります。

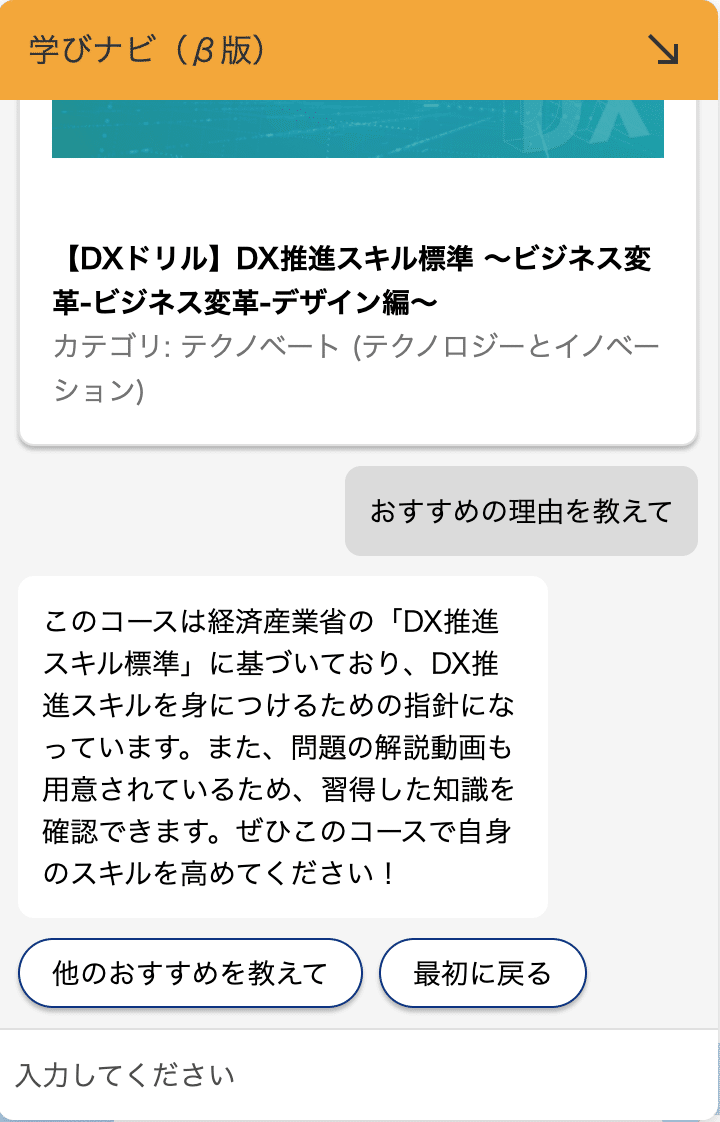
プロトタイプからの改善2: 各コースのおすすめ理由を提示する機能の追加
インタビューのフィードバックにもあった、「なぜこのコースが推薦されたかといった、理由もわかると良い」を実現するため、コースが提示された後に、その理由を聞けるような機能も追加しました。
ユーザーからの入力に基づくChatGPTの返答内容や、コースの内容を表すテキストの情報をプロンプトに含ませて、ChatGPTにおすすめの理由を生成させる愚直な方法で行なっています。
余談ですが、RAG(Retrieval Augmented Generation)と呼ばれる、LLMによるレスポンスを生成する際に、外部のデータソースなどを参照してコンテキスト情報としてプロンプトに含ませ、正確で適切な情報に基づいた回答を生成させるという、今となってはLLMアプリケーションにおいては欠かせない手法があります。
ご紹介した1~2の流れを見ていただくと、「実質RAGっぽいことやってる?」と感じていただけるかと思いますが、今回の対話フローの中では
ユーザーのクエリ解釈結果とコースの紐付けを行ってコースを提案
おすすめの理由をさらに聞きたい場合は1.の結果をコンテキスト情報としてプロンプトに含ませて生成
の2つの構成要素に分かれており、RAGで行っている処理を分解して実装しているような形になっています。
その他 UI/UXや分析に関わる開発
以下のようなUI/UXや分析に関わる機能は、フロントエンドエンジニアの方と連携しながら進めていきましたので、その内容もいくつか紹介します。
特定のタイミングでのチャットボットのお声がけメッセージ表示
ユーザーストーリーの中で、「どういう時にユーザーはチャットボットを使いたいと思うか」という問いに対する仮説を立てていたので、その仮説に紐づく行動をトリガーにチャットボットからの訴求を行えるようにしています。
今回はまずはページ滞在時間、スクロール距離といった簡易的な条件を設定しています。

ユーザーIDやチャットボット起動アイコンのクリックイベント、起動ページの情報など、分析用のログの仕込み
対話の内容のログはDialogflow上でロギングの設定を行うことで収集できますが、サービスの中での利用状況もモニタリングするために、クリックイベントのログなどを別途追加します。
今回はグロービス学び放題のWeb版の中のトップページと検索ページの2箇所にチャットボットを配置することにしましたが、それぞれのページごとの利用状況も見ておきたかったので、どのページで起動されたかといったログなども実装しています。
その他、Dialogflow Messengerの仕様に沿ったスタイリング、UIレスポンシブ対応、入力UX改善の対応など
このチャットボット機能はまだ検証目的の側面が大きかったため、インターフェース開発には最低限のリソースを投入する形が望ましいということもあり、Dialogflow上で構築した対話フローと容易に連携が可能かつ、カスタマイズも幾分可能なものとして提供されているDialogflow Messengerを採用しています。
Dialogflow Messengerは、現在は生成AI連携という観点で多様なコンポーネントが提供されており、カスタマイズ性もかなり高くなっていると思われますが、このチャットボット機能を開発している段階では色々とアップデートがなされている状況だったため、アップデート内容をキャッチアップしながら、具合の悪くなった箇所についてはフロントエンドエンジニアの方に調査してもらいながらワークアラウンドを模索していくということをやっていました。
リリース後どうなったか
リリース後の利用状況について把握するために、ログに基づいたファネル分析や、やり取りの中に含まれるテキストデータの分析を行いました。
リリース後、約3ヶ月経った時点でのおおよその分析結果としては以下のような内容となっています。
ユーザーの利用率は低い
機能の利用率は、設置されているページ訪問ユーザーの1%前後といった低い数字となっており、サービスを利用するほとんどのユーザーに対して価値を提供できていない状況といえます。
利用ユーザーのコンバージョン率は悪くない
対話開始→レコメンドされたコースを視聴するまでの割合は2割強といったところで、利用してくれたユーザーにとってはある程度価値に繋がっているのではないかと考えられます。
設置箇所によって使われ方の傾向に差があった
今回はトップページと検索ページの2箇所にチャットボットを設置しましたが、ページによって使われ方に若干違いが見られました。
トップページでは検索が目的であろうやり取りと、雑談気味なやり取りが半々くらいであったのに対し、検索ページでは検索を目的としたような使われ方が大半を占めているような状況でした。
その他、社内の営業チームの方が顧客折衝の場面において、グロービス学び放題を紹介する中で有効活用してくださっているという、良い意味で想定していなかった嬉しいフィードバックもありました。
総じて、コースの提案などの質についてはそこまで悪くはなさそうで、うまく活用されているケースも0ではないものの、ユーザーの利用シーンやニーズにはうまく入り込めていない状況であると言えるのではないかと思います。
今後の課題
現在は上記の利用状況を踏まえて、クリアすべき課題を整理しながら、今後どうしていくか検討を進めています。
大きな課題はやはり利用率の低さで、利用してくれたユーザーにはある程度価値あるものとして認識されている可能性はあるものの、大多数のユーザーにとっての価値には繋げられていない状況です。
様々な理由が考えられますが、一つ推測されるのは、チャットボットのインターフェースに対する一定の利用ハードルの高さがあるのではないかというところです。
Microsoft Bing(Copilot)やGoogle Gemini、Perplexity.aiのように、普段ユーザーが利用している検索機能とインターフェースを統合させて、ユーザーの検索行動の中に自然と生成AIによる提案を組み込むといった形にすることで、より多くのユーザーに価値を届けられるようになるのではないかというところも、今後の方向性の一つとして検討しています。
また、LLM固有の技術的な課題も残っています。
例えば、サービス内には存在しないコンテンツも存在すると言ってしまう、いわゆるハルシネーションの対策は十分できていない状況です。
RAGをより本格的に活用するなど技術的な工夫以外にも、ユーザーの入力内容に適合したコンテンツがない場合でも、そこからさらに掘り下げていくような対話を行えるような対話フローの設計を考えたり、LLMの回答内容をその場で評価するような仕組みを作り、回答の信頼度を可視化したりするなど、UX視点での対策を行う余地もあると考えています。
さらに、LLMを継続的に改善しながら運用するためのLLMOpsという側面に対するチャレンジも残っています。
LLMが期待するレベルの性能を発揮できているかを常にモニタリングし、性能劣化が見られたら対応していけるように運用するのが理想ですが、
LLMの生成結果が、期待に即したレベルになっているかどうかを定量的に測定するにはどのような方法を取れば良いのか?
どのような評価指標を導入するのが良いか?
といった話は、まだまだ正解のない領域で、試行錯誤を重ねながら最適解を見つけていかなければなりません。
生成AI自体がまだ新しい技術ということもあり、十分な価値に繋げていくためにはまだまだ道のりは長そうですが、今後は少しでも価値に繋がっていそうなユースケースにフォーカスした形で課題に対処していきながら機能を進化させていきたいと考えています。
最後に
LLMや生成AIを活用したソリューションの開発は、まだ世の中的にもスタートを切ったばかりのところがほとんどだと思います。
今回ご紹介したチャットボットのソリューションも、背景にある課題とLLMの相性の良さは一定あると感じられるものの、十分ユーザーの利用シーンに入り込めていない要素が多くあり、理想的な形もまだ見えていない状況でもあります。
そのような中、グロービスでは事業における生成AI活用を積極的に探求していきたいと考えており、今後も事例や得られた知見を発信していきたいと考えています。
本記事をきっかけに、少しでもグロービスの事業や取り組みに興味を持たれた方がいらっしゃったらお気軽にご連絡ください。
最後までお読みいただきありがとうございました。
https://recruiting-tech-globis.wraptas.site
この記事が気に入ったらサポートをしてみませんか?