機械学習勉強会を開催しました!PART2

前回の勉強会に引き続き、機械学習勉強会を開催しました〜。
Kaggle(カグル)というデータサイエンスのコンペティションサイトがありまして、このサイトで出題される問題を実際に解いていきました。
Kaggleでは常にデータサイエンスのコンペティションが開かれており、優れた予測モデルを開発出来たら、賞金もあります。このコンペティション界隈に生息している人はKaggler(カグラー)と呼ばれ、データサイエンスの仕事未経験でもコンペティションで優秀な成績を納めた経験があると就職できることもあるようです!DeNAはKagglerを集めているようですね。
記事:第1回:なぜDeNAは「Kaggler」を集めているのか?
Kaggleで最初のお試しとして挑戦出来るのが「タイタニック生存者予測問題」です。映画でもお馴染み豪華客船タイタニックの乗船客の生存者を予測する予測モデルを作成する問題です。
乗船客の性別、年代、名前、チケット番号、どこから乗船したか、などの情報があり、これらの情報を元に生存者を予測していきます。
Pythonを実行する環境としてJupyter Notebookというツールを使用するので、以下の手順で説明していきました〜。
①Jupyter Notebookをインストール
②Jupyter Notebook使い方
③Kaggleからデータをダウンロード
④基本統計量について
⑤データの可視化について
そして、タイタニック号から生存出来たかどうか、に影響を与えている要素について解析してもらいました。例えば、性別は生存に大きな影響を与えていそうだ、と分かりました。下記の画像は集計結果です。
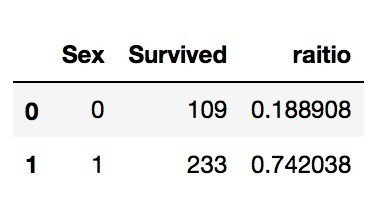
Sexの0が男性、1が女性です。男性の生存率が18%なのに対して、女性の生存率は74%でした。女性は優先して助けられたのですね〜。
こうやって生存に影響を与えている要素(説明変数と言います)を解析していき、予測アルゴリズムに適用することで予測モデルを作成出来ます。
今回は説明変数の洗い出しを行ったので、次回、選択した説明変数を予測モデルにかけるところまでやっていきます!
この記事が気に入ったらサポートをしてみませんか?