
AUTOMATIC1111Ver1.5のお勧め導入方法と、SDXL1.0の導入方法

※こちらの記事の内容はVer1.6の公開に伴い、内容が古くなりましたので、以下の記事で解説しなおしていますので、移動をお願いします。
記事内で紹介している個人的なWebUI設定に関しては引き続き使えそうなので、記事そのものは残してあります。
以前、こちらの改造型である【SD.Next】の導入方法を説明したものの、肝心のオリジナルAUTOMATIC1111の導入方法をnoteで書いていなかったので、友人に説明するためにも今回はこちらに書き記してみることにします。
また、SDXL1.0もついに公式リリースされましたので、今回はその導入まで含めた記事にしようと思います。
では、やっていきましょう。
AUTOMATIC1111とは
「AUTOMATIC1111」は、「Stable Diffusion」を扱うためのアプリケーションの1つで、最も豊富な機能が提供されている、いわゆる定番の物です。
AIイラスト作成サービスもかなりの数になってきましたが、ローカル環境でそれを構築したいとなったら、まず間違いなくAUTOMATIC1111だと思います。
最近は私もその改造型であるSD.Nextでの作成をするようになっていたものの、ここ最近AUTOMATIC1111が 1.5.0にメジャーアップデート されたということで、今回は環境の再構築を行おうと思います。
最近Ver1.5になったよ
執筆時点の最新Verは既に1.5.1ではありますが、1.5.0で追加された大きな特徴を先に見ておきましょう。

注目したい点は主に3つ
SDXLの公式サポート
SDXLに関しては詳しくは後程触れますが、ゲームなんかで言うところの次世代機に対応したようなものだと思ってください。
今後の主力になっていくであろうStable Diffusion XL 1.0 (SDXL 1.0) にしっかりと対応してくれたことで、今後も AUTOMATIC1111 が定番とされていくのは変わらないかと思います。
これまで AUTOMATIC1111 で制作なさってきた方もベースとモデルが大きく変化しますので、今回の記事を使って新規に環境構築されてはいかがでしょうか。
うまくいかなくても、前回までの環境を残しておけばいつでも戻れるので安心ですからね。
学習機能にユーザーデータの編集機能
学習機能にユーザーデータの編集機能というのは、既に実際に使用しているユーザー向けの話になりますが、追加学習ファイルを使っていく際の利便性が大きく向上しました。
LyCORISに正式対応
LyCORIS というのは追加学習ファイルの形式になりますね。
詳しく話すと中身はいろいろあったりして面倒なんですが、LoRAの発展形だと思えば良いかと思います。
追加学習としての精度は確かに高いのですが、学習データの作成や扱いが若干面倒くさく、また一般的にはLoRAでそれほど困らないこともあって、それほどあまり広まっているようには感じませんね。
LoRAの方がモデルにマージしたりといった柔軟な動きができるため、LyCORISの融通の利きづらさのようなものを感じる場面もあります。
とはいえ、正式対応されたことで今後はもっとこちらも発展していくかもしれません。
期待したいところですね。
前提プログラムをインストールする
Python
Git
をインストールしましょう。
A1111-Web-UI-Installerでインストールする
前置きが長くなりましたが、ここからが本編です。
AUTOMATIC1111は先ほどURLを貼った場所が本家でして、そちらに細かなインストール手順も載っているのですが、今回はもっと手軽に環境構築を行ってくれる非公式インストーラーの A1111-Web-UI-Installer を使った方法をご紹介します。
ただ、こちらの方法は Windows 10 and 11 x64 であることと、NVIDIAのグラフィックカードを使用していることが前提になっていますので、その点はご注意ください。
こちらのページにて、最新版をダウンロードできます。
Latest Realease (.exe)

今回は最新Verである A1111.Web.UI.Autoinstaller.v1.7.0.exe をクリックしてダウンロードし、実行していきます。
ユーザーカウント制御で「この不明な発行元からのアプリがデバイスに変更を加えることを許可しますか?」と聞いてくるので「はい」をクリック。
A1111の新たなインストール先を聞いてきますので、今回はDドライブ直下に A1111_SDXL1.0_20230720 フォルダを新規で作成し、選択しました。
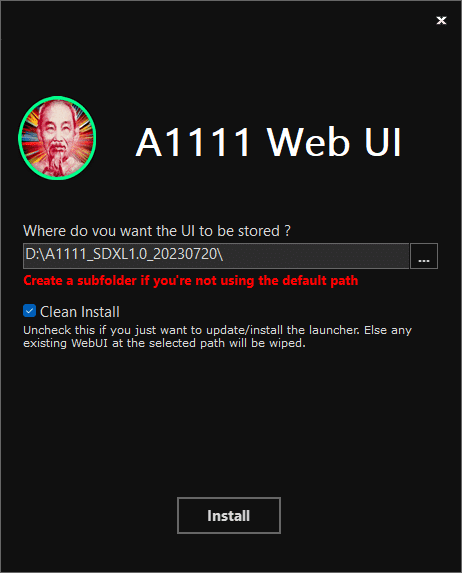
インストールが完了すると、A1111_SDXL1.0_20230720フォルダの中はこのようになりました。
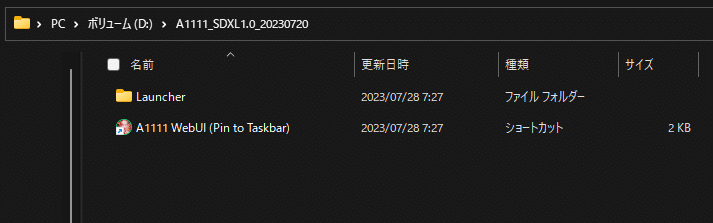
今度はこの A1111 WebUI (Pin to Taskbar) をダブルクリックして実行します。
ユーザーカウント制御で「このアプリがデバイスに変更を加えることを許可しますか?」と聞いてくるので「はい」をクリック。
すると、黒いウィンドウが開いて、なにやらプログラムが動き始めます。
次に「Install SD 1.5 Model?」と聞いてきます。
初めて Stable Diffusion をローカル構築する方の場合は「はい」をクリックしてダウンロードしてください。
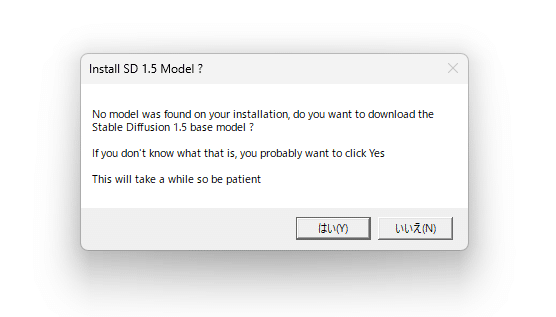
既に画像生成用のモデルを持っている方は「いいえ」で構いません。
その場合は後程、モデルの場所を指定するか、所定の場所にモデルを移動すれば良いだけです。

モデルのダウンロードが終わりましたら、このような長細いウィンドウが出てきます。

各項目の解説は画像に書き入れておきました。
Additional Launch Options には以下の引数を書き足してSAVEしています。
--no-half-vae 真っ黒い生成画像を出さなくて済むようにする呪文です。
設定画できましたら、LAUNCH WEBUI を押して WebUI を起動してみましょう。
コマンドプロンプトの画面の方が動き出し、初回なので何やらいろいろダウンロードしたりしていますので、ここでは数分かかります。
コマンドプロンプトの画面がしばらく動き、少し止まり、みたいなのを挟んで、ブラウザでWebUIの画面が開きました。

この画面がでれば、とりあえずWebUIの起動に成功したということです。
pip のアップグレード
途中、このような記述が出ていました。下の方の青字の部分です。
ここで結構な時間固まるので不安になりがちなんですが、ちゃんと待ってればインストールは進みます。
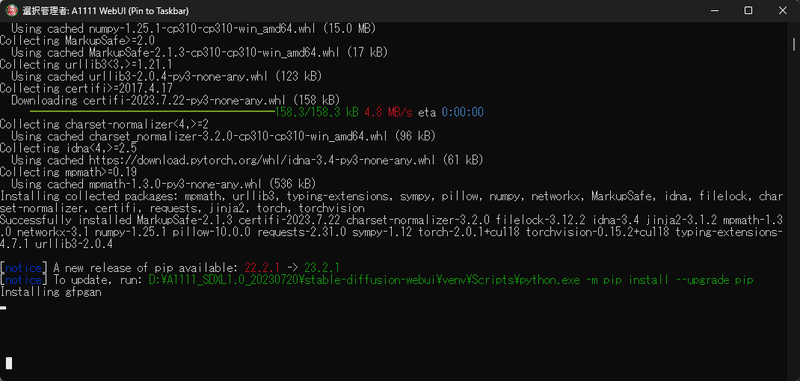
[notice] A new release of pip available: 22.2.1 -> 23.2.1
さて、これはpipというPythonパッケージ管理ツールの新しいバージョンが利用可能であることを通知しています。
現在のバージョンは 22.2.1 であり、新しいバージョン 23.2.1 がリリースされているそうです。
[notice] To update, run: D:\A1111_SDXL1.0_20230720\stable-diffusion-webui\venv\Scripts\python.exe -m pip install --upgrade pip
これは、新しいpipのバージョンにアップデートする方法を指示しています。
ということで、一旦ウィンドウを閉じ、プログラムを終了します。
エクスプローラーで D:\A1111_SDXL1.0_20230720\stable-diffusion-webui\venv\Scripts\python.exe を探してみます。

ありましたね。
では、このフォルダのURL部分をクリックし、「cmd」と打ち込んでエンターします。
すると、このフォルダでコマンドプロンプトを直接開くことができます。

先ほど指定されたコマンドをコピペしてエンターします。
python -m pip install --upgrade pip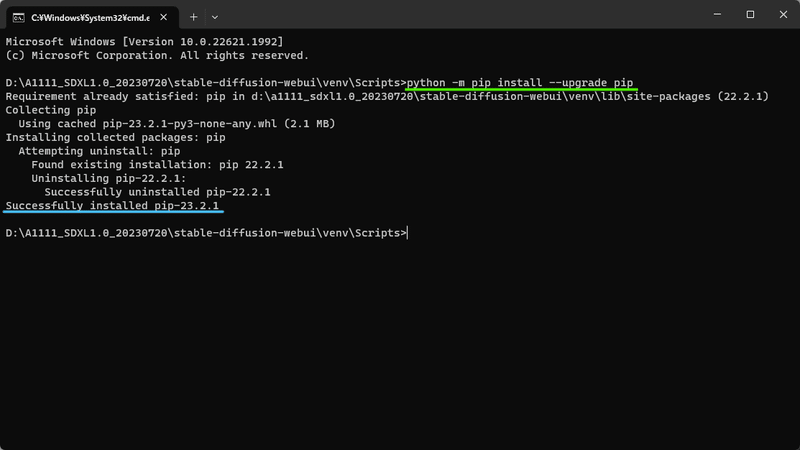
数秒後、無事 pip が23.2.1 にアップデートが成功した旨が表示されました。
参考例:はかな鳥のいつもの設定
ここでは、A1111 WebUI を再構築する度に はかな鳥が行っている設定を例として上げておきます。
参考になれば良いのですが。
1⃣ モデルを配置する
\stable-diffusion-webui\models\Stable-diffusion フォルダ内にモデルを配置します。
今回はインストール時の「Install SD 1.5 Model?」の設問に「Yes」と答えたため、SD1.5のモデルが自動でインストールされていますね。
CIVITAI なんかでお気に入りのモデルをダウンロードした場合、今後はここに入れていくことになります。
2⃣ VAEファイルを配置する
\stable-diffusion-webui\models\VAE フォルダ内にVAEファイルを配置する。
VAEファイルって何やねん、という方はこちらの記事で詳しく説明しています。
要は、画像生成する際の色味や彩度なんかに携わっているファイルです。
3⃣ アップスケーラーのファイルを配置する。
\stable-diffusion-webui\models\ESRGAN フォルダにお気に入りのアップスケーラーを追加します。
なにかと画像を拡大しがちなAIイラスト生成の過程で、その役割を担う機能をアップスケーラーといいます。
私はお気に入りのアップスケーラーがあるので追加していますが、元々様々な高品質なアップスケーラーがインストールされていますので、特にこだわりが無ければいじる必要はありません。
4⃣ WebUIを起動し、setteingから以下の項目を変更する。
・ Saving images/grids の Images filename pattern に
[date][model_name][sampler]_[seed]とコピペする。

これで画像生成した際に画像の名前が
【日付】【モデル名】【サンプラー】【seed値】になります。

画像の詳しい内容はWebUI内の PNG Info タブに放り込むことで詳しく見ることができるのですが、このあたりの情報はファイル名で見れるようにしておくと、あとあと便利だったりします。
・ Saving images/grids の Save copy of large images as JPG のチェックを外す。

普段はPNGで画像を生成していますが、これにチェックが入っていると、大きな画像を生成した際にコピーを JPG としても保存されてしまいます。
よほどメモリが苦しい場合は有用なのかもしれませんが、ぱっと見どっちがPNGなのかわからなくて面倒なので、私は切っています。
ちなみに、PNGは画像劣化の少ないファイル形式で少し重いですが、jpegは独特の画像劣化のある軽いファイル形式です。
・ Upscaling の Upscaler for img2img でお気に入りのアップスケーラーを選択する。

3⃣の項でアップスケーラーを追加していた場合の設定です。
img2imgで拡大する際、毎回ここで設定したアップスケーラーを使ってくれるようになります。
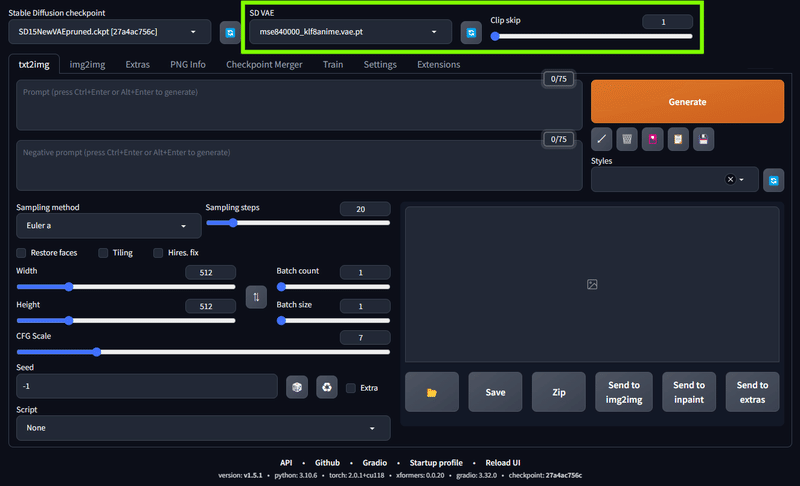
・ Stable Diffusion の SD VAE で お気に入りのVAEファイルを選択する。
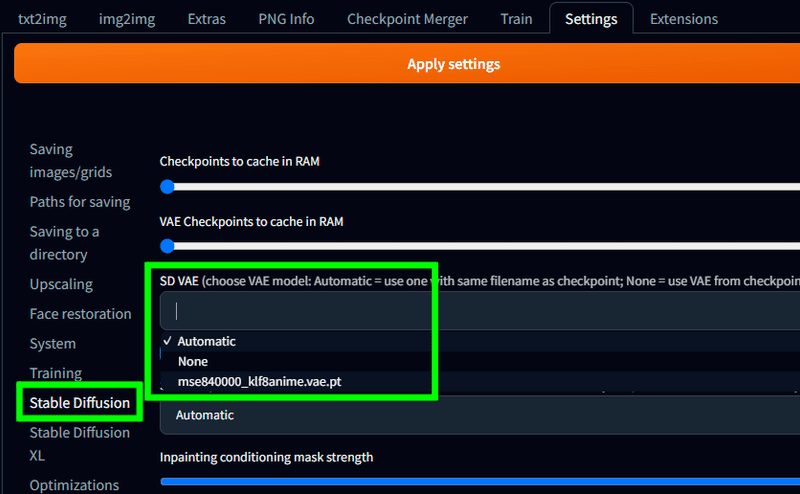
こちらは2⃣の項で好みのVAEを配置した場合、ここで選択したVAEをデフォルトで使ってくれるようになります。
・ Stable Diffusion の Apply color correction to img2img results to match original colors. のチェックを入れる。

画像にノイズを加え直して、もう一度書き直す機能を Img2Img といいます。
想像しやすいように言うと、画面全体を一度ボカシてからもう一度絵に直す感じで、その際に少しずつ周りと色が混ざってしまうため、使用するたびに絵の彩度が落ちていく場合があります。
ここのチェックを入れることで、生成し直した最後に、元の絵の彩度に近づける処理を入れてくれるため、画像の彩度がどんどん落ちてしまうのを抑制してくれます。
私はTxt2Imgでベースを作成したあと、Img2Imgを何度も繰り返したり合成したりして絵の完成度を上げていく方式を取っていますので、彩度が毎回落ちてしまうのは致命的でした。
この設定を覚えたことで、かなり楽になったのでお勧めしたい設定です。
・ User Interface の [info] Quicksettings list で sd_model_checkpoint,sd_vae,CLIP_stop_at_last_layers に設定する。
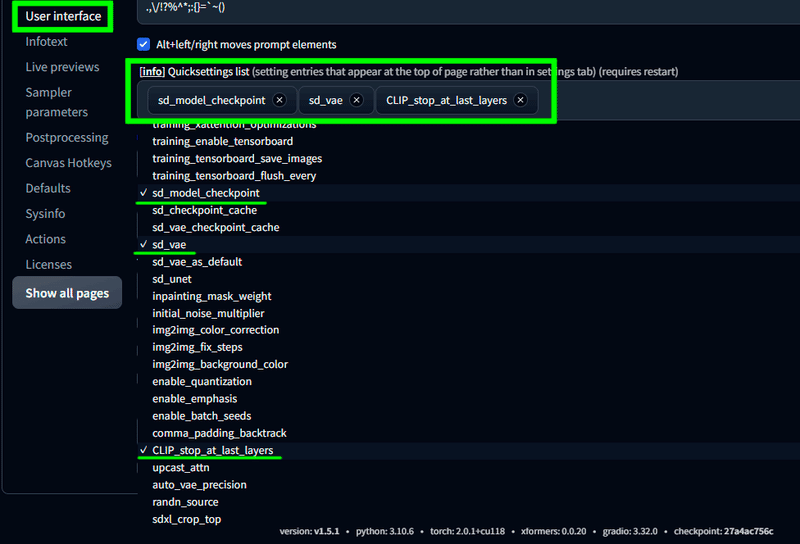
この設定をすると、WebUIのメインページの上部で VAE と Clip skip の設定をいつでも変更できるようになります。
VAEは先ほどから何度も説明したものですね。
イラスト界隈だとClip skipは 2 というのが多いですが、私は結構頻繁に変えて遊んでいます。
数字が大きいほど変化が大きく、promptの命令から逸脱した画像ができたりします。
・ Sampler parameters で DPM++ 2M Karras と DPM++ 2M SDE Karras 以外のサンプラーに全てチェックする。

Stable Diffusion ではサンプラーというものがありまして、それごとに絵の描き方が違ってきます。
結構な数があるのですが、ここでチェックを入れたサンプラーは非表示にできますのでやっておきましょう。
サンプラーに関しての詳しくは hoshikat さんのblogをご覧いただければと思います。
SD1.5モデルで生成するだけなら DPM++ 2M Karras がお勧めなんですが、後述する SDXL1.0 では SDE系がお勧めとの話がありましたので、DPM++ 2M SDE Karras も残しておきます。
ここまでのsettingが終わりましたら、画面上部の Apply settings をクリックしてから Reload UI で再起動してください。

以降、設定が反映されるようになります。
また、これまでの設定の途中段階でも内容を反映したい場合は、その都度やっておいて問題ありません。
個人的に使っている拡張機能
easy-prompt-selector&wildcards
Extensions の Install from URL で
https://github.com/blue-pen5805/sdweb-easy-prompt-selectorを入れてインストール。
Extensions の Install from URL で
https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards.gitを入れてインストール。
こちらで紹介している拡張機能2つをインストールしています。
詳しくはリンクページをご覧ください。
Tiled Diffusion & VAE
Extensions の Install from URL で
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111.gitを入れてインストール
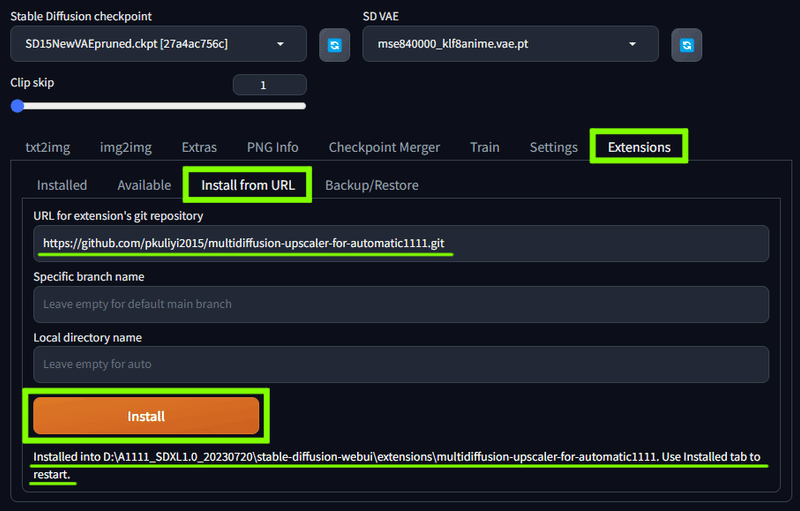
大きいサイズの画像に生成し直す際、画像をタイル状に区切って小さな画像を複数生成するという手順を使うことで、低スペックPCでも大きなサイズの画像を生成することができる拡張機能です。
詳しくは後日また説明記事を書くつもりです。
リッチなイラストに仕上げたい場合には是非使いたい拡張機能です。
ここからは Extensions の Available タブから Load from: を押して、リストの中から拡張機能をインストールしていきます。

https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui-extensions/master/index.jsonというURLがあらかじめ入っていると思うので、そのまま Load from: すれば画面下側にリストが読み込まれます。

ここからはサーチ機能を使って拡張機能を探していきます。
After Detailer
「After Detailer」 で検索して !After Detailer manipulations をインストール。

これは画像を生成したあと、自動で顔や手、身体といった特定の部分のみ、もう一度詳細に描き直して合成してくれる拡張機能です。
部分的に拡大した上で生成し、自動で合成してくれるため、その個所のディテールが上がります。
また、それぞれにプロンプト&ネガティブプロンプトも設定できるので、細かい表情や服の模様などは、こちらの欄で指定するなどの方法もとれます。
こちらも細かい説明などは別記事で今後書くことになると思いますので、お待ちいただければ幸いです。
ControlNet
「sd-webui-controlnet」 と検索して sd-webui-controlnet manipulations をインストール。
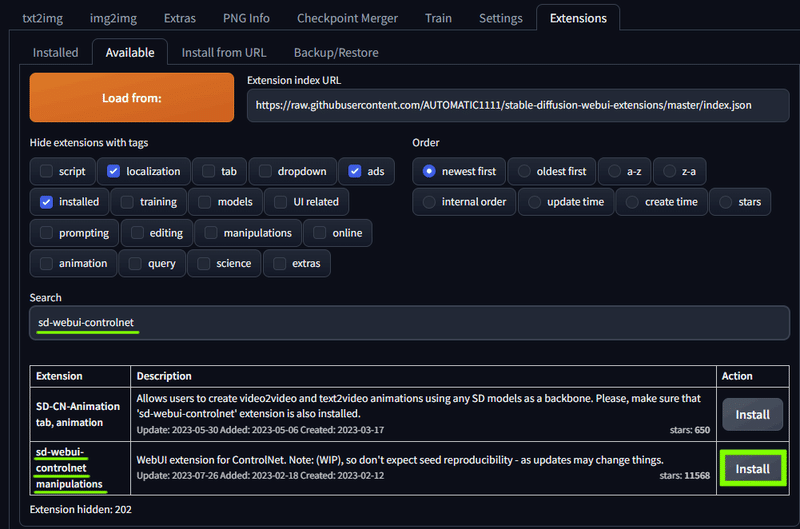
言わずと知れた ControlNet です。
詳しい記事はFANBOXの方でかなり細かく説明していたのですが、現在はあちらが使えなくなってしまったので記事の引っ越しを予定しています。
簡単に言ってしまえば、画像を生成する際にポーズや構図、表情や要素といったものを指定することができる拡張機能です。
ガチャ要素を減らして目的のイラストを作成したい際に大いに役立ちます。
詳しくは後日引っ越ししてくる記事をお待ちください。
3D Openpose Editor
「3D Openpose Editor」で検索して 3D Openpose Editor tab をインストール。

先程の ControlNet でポーズを指定する際に使う機能に Openpose というものがあるのですが、その下地になるポーズを3D人形を使って作成することができる拡張機能です。
Aspect Ratio selector plus & Aspect Ratio Helper
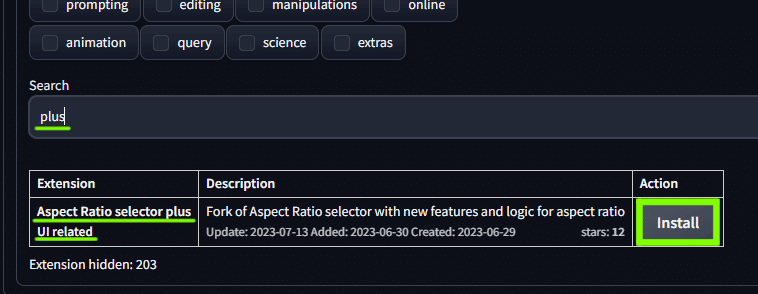
「plus」 と検索して Aspect Ratio selector plus UI related をインストール。
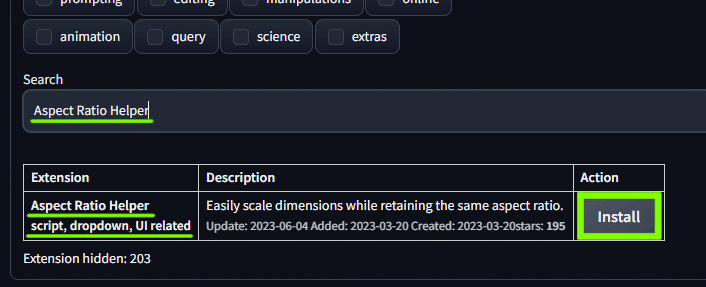
「Aspect Ratio Helper」 と検索して Aspect Ratio Helper script, dropdown, UI related をインストール。
すべての拡張機能のインストールが終わったら、Extentions の Installd から Apply and restart UI を押してインストールを確定させ、再起動させれば拡張機能が反映されるようになります。
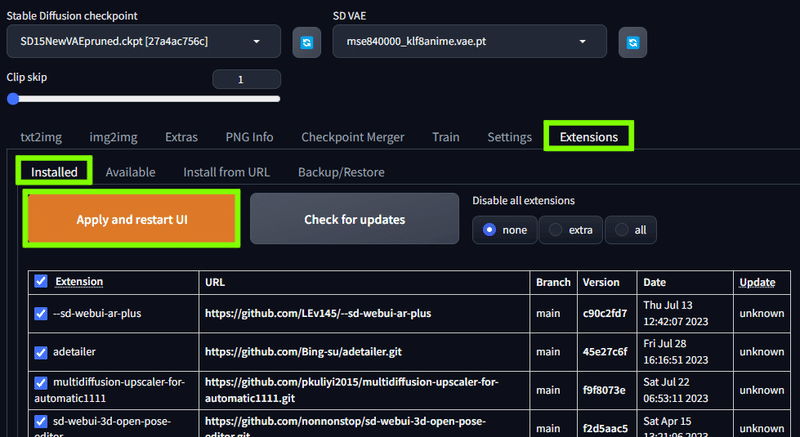
もしそれでも反映しなかった場合は、一度WebUIを終了し、もう一度起動しなおしてみてください。
SDXL1.0 を導入する
SDXL1.0 は Stable Diffusion の最新のAIモデルです。
現在、SNSなどでよく見かけるAIイラストのほどんどは、この2世代ほど前にあたるSD 1.5モデルで作成されたものです。
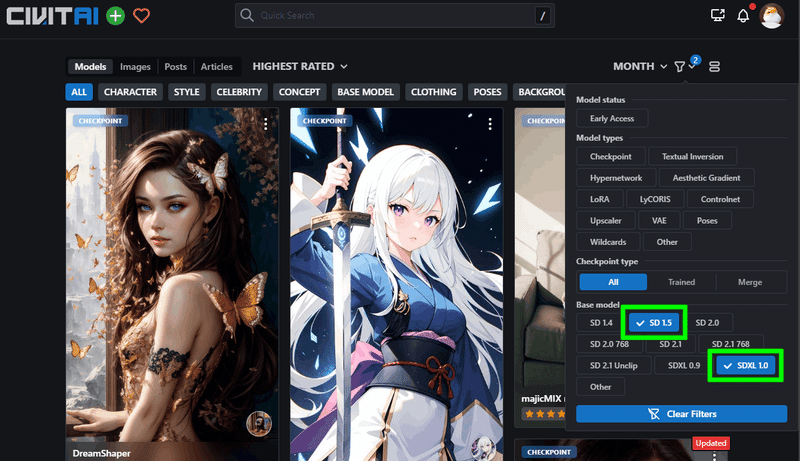
その後もマイナーVerは出てましたし、基本解像度が 768×768 に上がったSD2.0もありましたが、爆発的にユーザーの増えた1.5のモデルで大量のマージモデルが作られ、品質が向上していった結果、2.0のモデルはあまり伸びませんでした。
最初に言ってしまうと、事アニメ系絵柄のイラストにおいては、SDXL1.0 も同じような状況から始まるかと思います。
写真のような実写系のものは資料がいくらでもありますので最適化しやすいのですが、イラストになると絵柄によって品質や内容が様々なのでなかなか調整が進みません。
また、SD 1.5系のモデルでも、結果的には実写寄りの絵柄のものの勢力がどうしても強くなっています。
理由はいくつかあります。
1.5モデルで絵の破綻を抑える為に実写系を混ぜる場合がある
顔はアニメでも身体はリアル寄りの絵柄がウケやすい
海外ではもともとな写実的な絵柄が親しまれている
他にもいろいろな要素が混ざりあっているのですが、この場で言及できるのはこのあたりでしょうか。
とはいえ、私個人としては1.5モデルの限界点というものも感じるようになってきていました。
モデル自体の限界というよりは、界隈全体を含めてのものなのですが。
正直、絵の枚数はとんでもなく多いのですが、SDで作られたイラスト系の絵柄は3種類程度の枠に収まって見えてしまっています。
「この人の絵もこの顔か」「まーたこの顔か」という感じですね。
「お、この絵柄ちょっと珍しいな」、と思って見てみると #nijijourney のタグがついてたり…。
これはモデルだけの問題ではなく、EasyNegativeをはじめとした下地の部分まである程度お約束化されている結果ともいえます。
NovelAIが流行った直後は皆「masterpiece」をプロンプトの最初に書き入れて、同じような顔ばかりで「マスピ顔」なんて言われた時期もありましたね。
結局のところ、今も同じような環境ができてしまっているということです。
私も自作LoRAを挟むことで絵柄を少し変えてはいますが、絵柄LoRAを使うと絵そのものの品質が落ちやすいというジレンマがあったりして、あまり強くかけられなかったりします。
その点、SDXL1.0 ではクオリティーアップのプロンプトを使用しなくても高品質な絵を作れるようになったという画力の底上げのような話もあり、期待しています。
解像度も1024×1024が基本となったので、最初の作画段階でも細かいディテールを描けるようになるのも嬉しい所です。
手の崩壊も若干改善されているものの、崩壊そのものはまだ起こるようですね。
SDXL1.0のモデルについて
さてさて、そんな SDXL1.0 のモデルですが、こちらのページのNewsに書かれたリンクから飛べます。
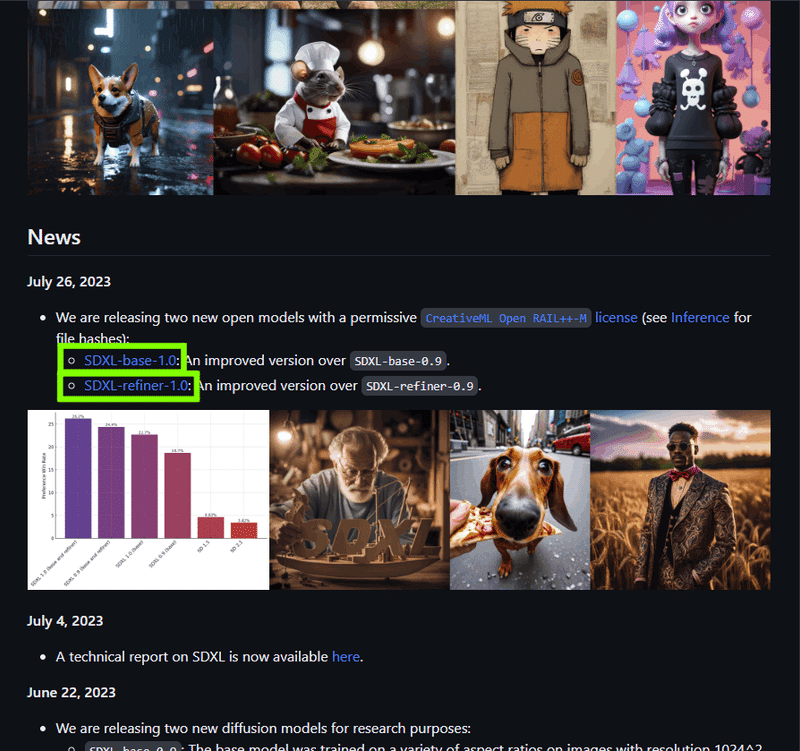
ん、モデルって2つあるの??
と思われるかもしれませんが、その通りです。
SDXL では2段階で画像を生成します。
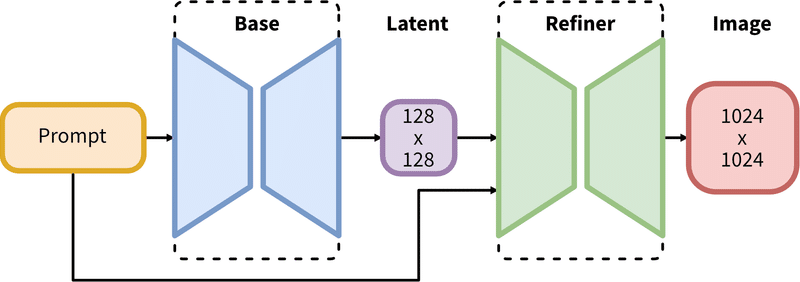
1段階目にBaseモデルで土台を作って、2段階目にRefinerモデルで仕上げを行います。
感覚としては、txt2img に Hires. fix を使って生成する感覚に近いでしょうか。

Ver1.5.1時点でのAUTOMATIC1111では、この2段階を同時に行うことができません。
なので、txt2imgでBaseモデルを選択して生成し、それをimg2imgに送ってRefinerモデルを選択し、再度生成することでその挙動を再現できます。
このあたりは前回ご紹介した SD.Next や ComfyUI でならば自動化できるようです。
とはいえ、将来的にはAUTOMATIC1111でも改善されるかと思いますので、焦って他のプログラムに移行する必要は無いと思います。
Baseモデルのダウンロード
まずはBaseモデルから落としましょう。

画像で示したあたりを左クリックすればダウンロードが始まります。
右クリックからの「名前を付けてリンク先を保存」ではうまくいかない場合があるので、必ずこのあたりを左クリックして保存してください。
Refinerモデルのダウンロード
次はRefinerモデルを落としましょう。
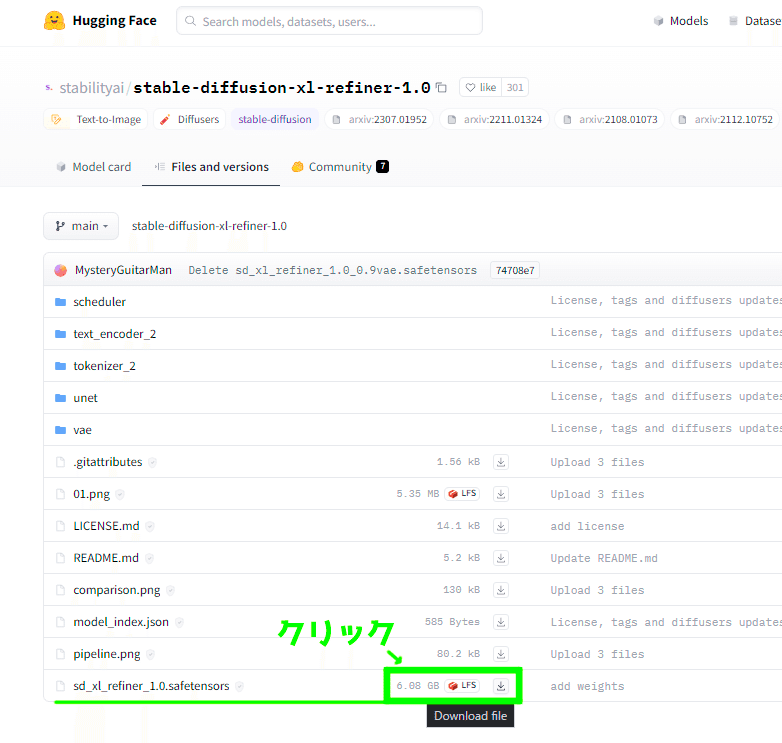
先程と同じように画像で示したあたりを左クリックすればダウンロードが始まります。
SDXL1.0モデルを配置する
\stable-diffusion-webui\models\Stable-diffusion フォルダ内にモデルを2つとも配置します。

WebUI で checkpoint(モデル)選択欄の右にある更新ボタンを押すと、フォルダに入れたモデルを選択できるようになります。

SDXL-VAE-FP16-Fixをダウンロードする
現状、fp16での実行に問題があるため、専用に訓練されたVAEがあるそうなのでダウンロードして配置しましょう。
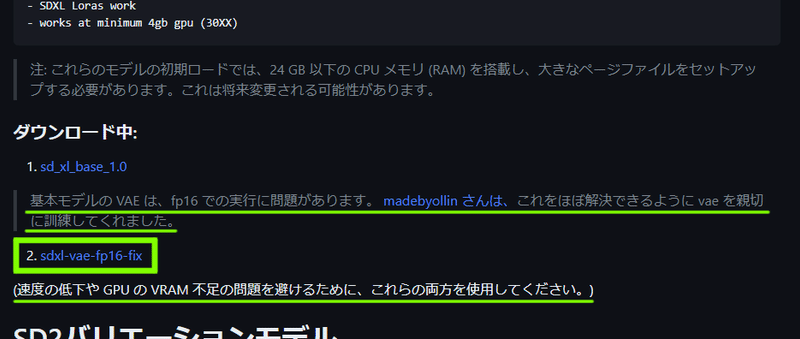

ダウンロードできたら、VAEのフォルダに移動させましょう。
先程も書いた通り、VAEのフォルダはこちらになっています。
\stable-diffusion-webui\models\VAE

これで準備が終わりました。
SDXL1.0での生成テスト
BaseモデルでのTxt2Img
初回、SDXL1.0のモデルを読み込む際、かなりメモリを使います。
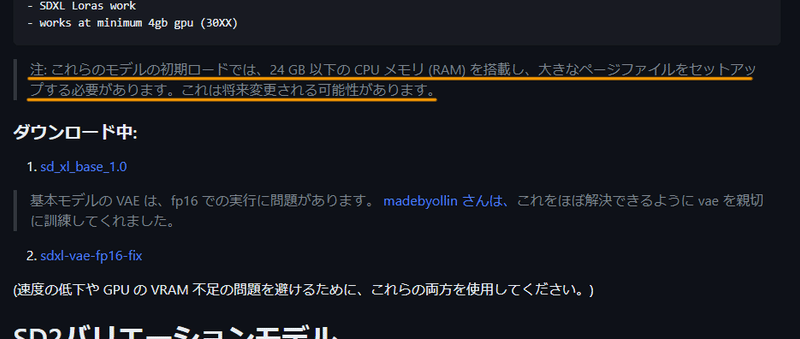
将来的には変更される可能性があるとのことですので、今後はもう少しマシになるかもしれませんね。
もし、CUDA 関係の RuntimeError でも起きたら、下記の記事からCUDA Toolkit 周りの導入をしてみてください。
私の場合、このインストールを終わらせてからAUTOMATIC1111を新構築することでエラーが出なくなりました。
今回は、いつも使っている「うちの子」用のpromptを入れてみます。
・Txt2Img にて作成。
・モデルは Baseモデルの sd_xl_base_1.0.safetensors を選択。
・VAE は sdxl_vae を選択。
・ネガティブprompt は無しでいきます。
・画像サイズは 1024x1024 です。
これ以下の場合はあまりうまく生成できないという話ですので。

prompt指定通りの女の子が出ました。
かなりリアルテイストな絵柄ですが、1024x1024で破綻は無さそうですね。
流石は SDXL1.0 です。
RefinerモデルでImg2Img
・Img2Img にて作成。
・モデルは Refinerモデルの sd_xl_refiner_1.0.safetensors を選択。
・VAE は sdxl_vae を選択。
・ネガティブprompt は今回も無しでいきます。
・画像サイズは変わらず 1024x1024 です。
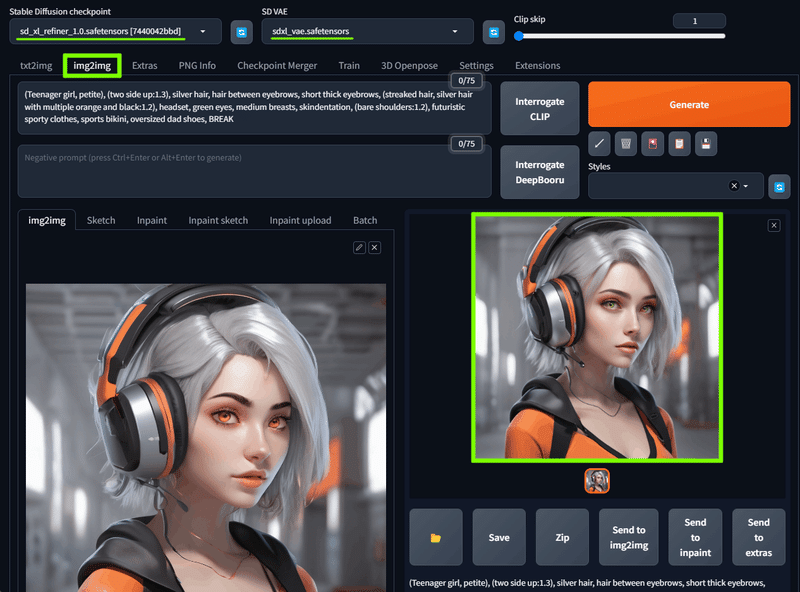
今回は変化もある程度見たいので Denoising strength を 0.4 に設定

Badeモデルの時点でリアル味が強かったのですが、Refinerモデルの方は更にリアルさが増した感があります。
まだ絵柄LoRAとかも作成できていませんし、イラスト向きのモデルでもありませんので急いで移行する必要は無いかと思いますが、既にSD1.5モデルで有名だった Counterfeit シリーズのXL版がリリースされています。
既にネガティブprompt向けの TEXTUAL INVERSION もリリースされていました。
他にも、日本のモデル配布者さんたちが続々と参入しているようです。
もしかすると、SD2.0の時よりはマージモデルの開発も進むかもしれませんね。
おわりに
さて、AUTOMATIC1111 でSDXL1.0を扱えるようにするまでの流れを見ていただきましたが、いかがでしたでしょうか?
とはいえ、現状の Ver1.5.1 ではまだ、SDXL1.0 に対応しきれていないという場面が多く見受けられます。
例えば、SDXL1.0 モデルをセットしている間は TEXTUA IINVERSION が読み込めないとか。
EasyNegative とかが見えなくなって焦ります。

ちゃんと 1.5のモデルを読み込みなおしてRefleshボタンを押せば見えるようになります。
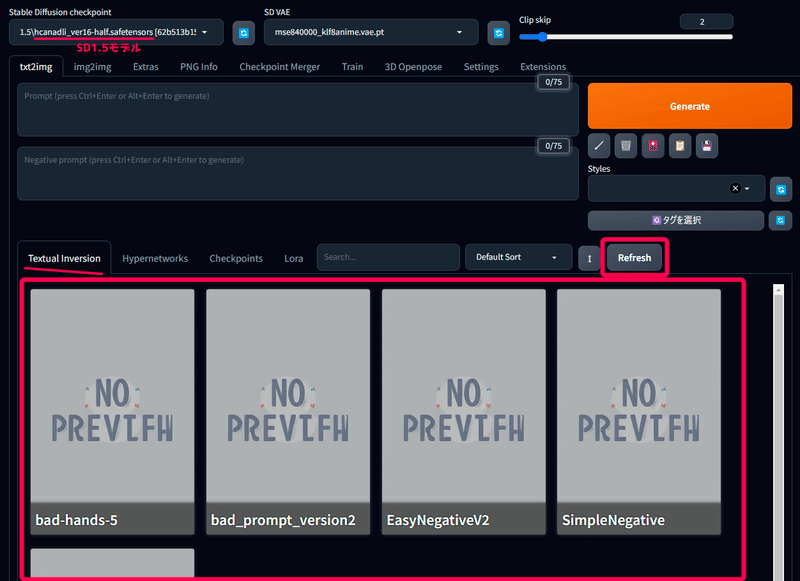
もうしばらくすれば対応されると思うのですが、いち早く安定した環境を取り入れたいという方は SD.Next や Comfy UI なんかの導入も検討してみてください。
とりあえず、今回の趣旨である AUTOMATIC1111 の導入に関してはご紹介できたと思いますので、今回はこれにて終わろうかと思います。
次回は Comfy UI に関しての導入法や、扱い方なんかをご紹介できればと思っています。
それでは、また。
はかな鳥でした。
この記事が気に入ったらサポートをしてみませんか?