
アンサンブル学習で学習精度を上げる

前回はパラメータチューニングや性能指標の評価などを行いました。
今回は、一つの学習モデルを複合して使うことで精度を上げるアンサンブル学習から、バギング・ブースティングなどを解説していきます。
では、いきましょう。
1. イントロ〜アンサンブル学習とは?〜
アンサンブル(ensemble)というのはオーケストラなどでよく聞く言葉かと思いますが、実際に2人以上が同時に合奏することを指します。
これに基づき、機械学習におけるアンサンブル学習とは
複数の分類器をまとめて一つの大きな分類器とし、それぞれの出した結果の多数決に従って最終的な判断を下す学習モデル
を指します。
専門家1人に頼るのではなく、何人もの専門家で議論した方がよりよい解決策が出るイメージがわかりやすいかと思います。
厳密に言えば、今回は二値分類(0 or 1の判定)のみを扱うため、多数決の原理を用いますが、分類器でないとき(回帰など)は平均値をとるときもあります。
・アンサンブル学習の外観や背景理論
では、実際のアンサンブル学習の外観や背景理論をみていきますが、今回多少の数式が出てきます。
数式の部分は章を区切りますため、基本的にコードだけでいいという方は読み飛ばしても問題ないようにします(つもり。)
では、外観から。
今回は分類器(まとまったサンプル同士でグループを作るようなイメージ。決定木、SVMが代表的)を扱っていきます。
まず、各分類器C1, C2, C3, ..., Cm(合計m個)まであるとします。
これらを訓練データを用いて、それぞれの出す結果を多数決で最終的な予測を決めるのがアンサンブル学習です
(ちなみに、同じ分類器でも、違う訓練データを学習させて別物として扱うようなパターンもあります。ランダムフォレストが代表的)
実際にイメージは以下。
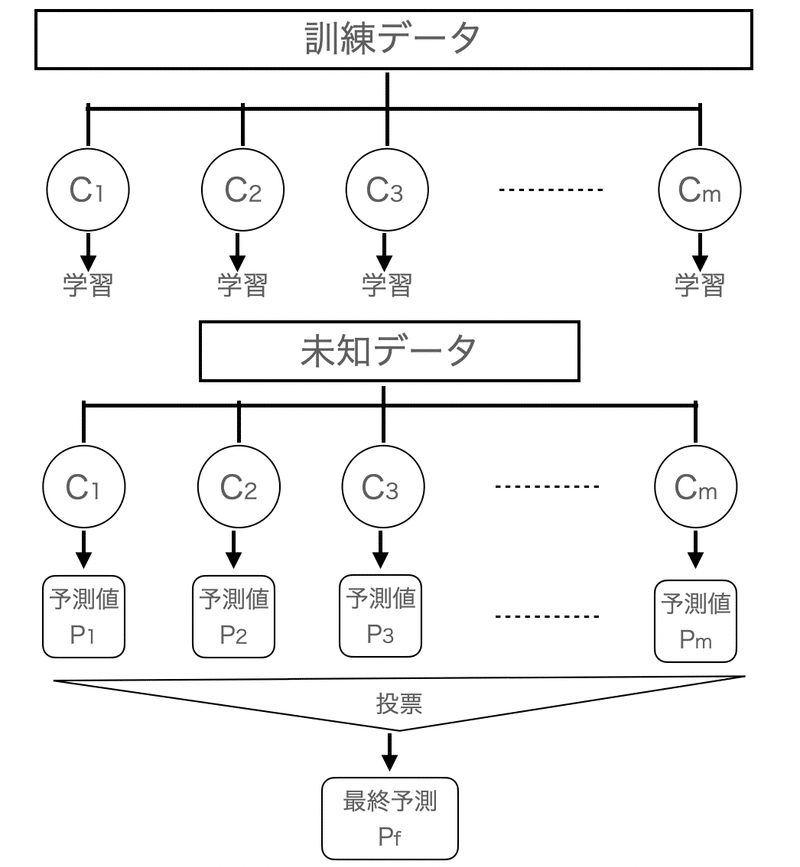
・簡単な背景理論
上記の図でたいてい外観は掴めたと思いますので、ここから少しばかり数学になりますため、数学が嫌いな方はこちらは飛ばしても大丈夫です
先程の多数決や相対多数決を用いてクラスラベルを予測する式は
y^(yの予測値) = mode(C1(X), C2(X), C3(X), ..., Cm(X))
(mode(a, b, c, ...)は最頻値を表し、引数の中で最も多く出現した要素が返ってきます。例えば、mode(1, 1, 1, 2, 3, 4, 4) = 1)
また、二値分類なら、クラス1 = -1, クラス2 = +1として扱えば、
C(X) = 1 (ΣCi >= 0 ) or -1 (ΣCi < 0)
として扱うこともできます。
つまり、単体でみるよりも多数決をとる方が基本的には精度が高くなると言えます。
ここで、少し数式ベースでもう一つ簡素な例を見てみましょう。
今、それぞれの分類器が独立であり、その全ての誤分類率がεであることを仮定します。(誤分類率の相関もないものとします)
そうすると、メタ分類器(C1, C2, ..., Cmを一括りにした分類器)の(k個以上の)誤分類率は以下。([n k]はCombnation(二項係数)を意味します。)
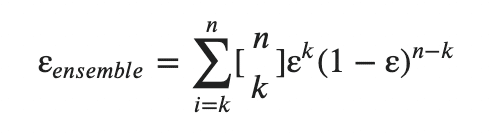
二項係数の説明は割愛しますが、少し具体的な数値を見てみましょう。
たとえば、ε=0.25のもとで、n=11にて、半数以上(k=6)が誤分類してしまう確率を求めるとそれぞれに代入すれば0.034となります。
つまり、一つの分類器では0.25も誤分類するものが合体させることで0.034しか誤分類する確率は低くなったことがわかります。
ここにアンサンブル学習の強みがあります!!
・Pythonで実際に誤分類を実装・可視化
理論で見ると、誤分類率はεが小さい時にはその威力を発揮することがわかりました。
(読み飛ばされた方に向けて補足すると、複数合わせた分類器の誤分類する確率は、一つの分類器の誤分類する確率よりも低いよねということを説明していました。)
では、実際にpythonで実装してみましょう。
まずはコードから。
import math
from scipy.special import comb
def ensemble_error(n_classifier, error):
# math.ceil(): 小数点の切り下げ
k_start = int(math.ceil(n_classifier / 2.))
# 確率
probs = [comb(n_classifier, k) * error**k * (1-error)**(n_classifier - k)
for k in range(k_start, n_classifier + 1)]
return sum(probs)
ensemble_error(n_classifier=11, error=0.25)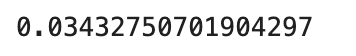
では、コードの解説に入ります。
今回は、combination(二項係数)を使うため、scipy.specialからcombをインポートしています。
scipy.special.comb(N, k, exact=False, repetition=False)
N: int or ndarrayで指定。
k: int or ndarrayで指定。
exact: Falseの場合、浮動小数点まで表示、Trueの場合、整数部分のみ。
repetition: Trueの場合、N = N + k - 1としてcombを計算。
・少し脱線(combの挙動を確認)
print(f'comb(10, 3, exact=False): {comb(10, 3, exact=False)}')
print(f'comb(10, 3, exact=True): {comb(10, 3, exact=True)}')
print(f'comb(10, 3, exact=False, repetition=True): {comb(10, 3, exact=False, repetition=True)}')
print(f'comb(12, 3, exact=True, repetition=False): {comb(12, 3, exact=True, repetition=False)}')
詳細な説明は割愛しますが、大体の挙動は理解できたかなと。。
# math.ceil(): 小数点の切り下げ
k_start = int(math.ceil(n_classifier / 2.))math.ceilで引数のn_classifiler / 2を切り下げてkの始点を定義。
# 確率
probs = [comb(n_classifier, k) * error**k * (1-error)**(n_classifier - k)
for k in range(k_start, n_classifier + 1)]
return sum(probs)リスト内包表記で数値k~数値n_classifierまでの以下をリストで格納し、最後にsumで先程のΣをとった数値を返します。
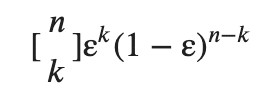
- 可視化
実際に、ε: 0.1 ~ 1.0まで動かしてみてどのくらいε_ensembleが変わるのかをプロットで見てみましょう。
import numpy as np
import matplotlib.pyplot as plt
# 確率の範囲 0 ~ 1の範囲で誤分類率を動かす
error_range = np.arange(0, 1.01, 0.01)
ens_errors = [ensemble_error(n_classifier=11, error=err) for err in error_range]
# ベース分類機と誤分類率の関係を図示
plt.plot(error_range, ens_errors, label='Ensemble error', linewidth=2)
plt.plot(error_range, error_range, label='Base error', linestyle='--', linewidth=2)
plt.xlabel('Base error')
plt.ylabel('Base/Ensemble error')
plt.legend(loc='upper left')
plt.grid(alpha=0.5)
plt.show()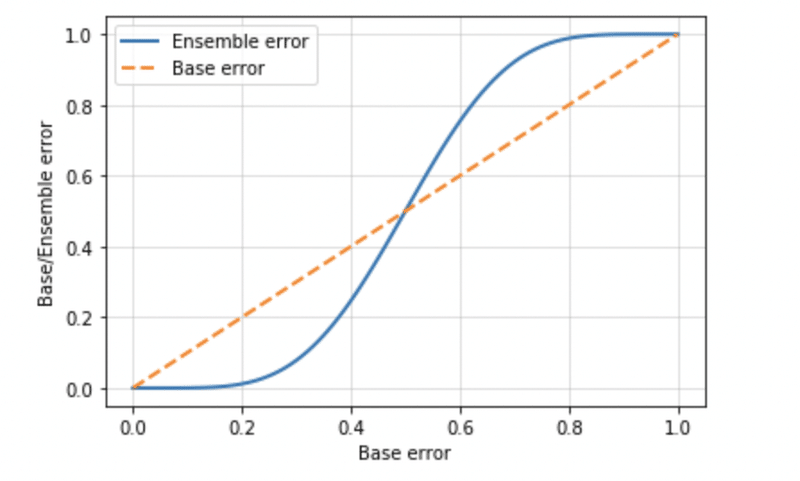
(plotに関しての説明は今回の主題ではないため、割愛します)
ε が0.5を超えるとアンサンブル学習をすると一つの分類器以上に誤分類してしまうことがわかりました。
つまり、非常に高い精度を誇る分類器がある場合はアンサンブル学習すると返ってミスしてしまうことになりかねないことに留意しつつも、ベース分類器が当て推量よりも高い(ここでいうε < 0.5のこと)限りは、アンサンブル学習の誤分類率が優っていることになります。
2 多数決の実装や理論背景
さて、多数決とはいえ、実際にはいくつかの原理により多数決を決めるということがあります。
ここではやや数式が多くなりますが、後々数式を再掲することはないと思いますので、コードだけみたいという方は流し見でおけです。
・単純な多数決分類器の実装
大前提の目的としては、アンサンブル学習によりここの分類器よりも高い精度を出すことです。
そこで多数決の中でも一般的には確信度に対する「重み」により調整がされることが多いです(純粋な多数決よりも、例えば今まで成果を上げてきた人の声の方が大きいなどを想像するとわかりやすいかと)
数学的にこれを表すとすると
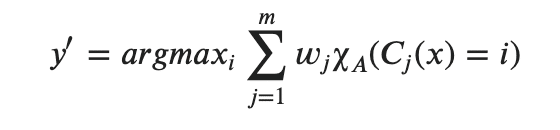
(私も含めて)なんだよこれ、ってなる人もいるもいるので、一つずつ説明します。
まずχ_A(Cj(x) = i)から。
Aを一意なクラスラベルの集合として設定します。
そして、iはAの要素です。
このχ_Aとは特性関数と言われるもので、j番目に予測されたクラスが i と一致するときに1を返す関数です。
つまり、χ_A(Cj(x) = i)とは、それぞれの分類器Cjがiと予測したのであれば1を、それ以外は0を返します
そこにCjに対するw_jという重みを加えることで調整しています。
その和を取るのですが、ここでargmax(i)という見慣れない関数があります。
ざっくりと言えば、arg max f(x)とは関数f(x)を最大にするようなxの集合を返します。
まだ、「??」って感じなので、少し具体例をみておきましょう
x ∈ {0, 1} にて argmax 3x はx=1で3xは最大値3を取るため、この解は(x=) 1となります。
すこし簡略して他にも書くと、(表記の制限があるため、少し砕けた書き方になっています)
𝑎𝑟𝑔𝑚𝑎𝑥(0=<𝑥<=4𝜋)𝑠𝑖𝑛(𝑥)= {𝜋/2,5𝜋/2}
となります。
では、今回の場合、
とは、
「w_jにより調整されたχ_Aの合計を最大にするような i が出力される」
という式になります。(伝わりますでしょうか。。??)
つまり、y'には常にもっとも票数を集めるようなクラスラベルiが格納されます。
ちなみに、重みw_jがすべて等しいときは最初の方で出てきた
y^(yの予測値) = mode(C1(X), C2(X), C3(X), ..., Cm(X))
と同義となります。
・ここでいう重みとは何か?
もう少し数学にお付き合いください。
さて、なんの前置きもなくw_jという重みを使ってきましたが、この重み付けをもう少し具体的にみていこうと思います。
今、3つの分類器C1, C2, C3があり、
あるデータ点xにて、Ci(x) = 1 or 0という予測をするとします
ここで、C1, C2 = 0と分類し、C3だけは1と分類したとします。
ここで、重みが全て等しい(つまり考慮する必要がない)のであれば、
多数決により、最終結果は0 と判断されます。
(数式で書くと、y' = mode(0, 0, 1) = 0)
しかし、ここで重みをC1, C2には 0.2 をかけて、C3には0.6がかけられたとすると、
にて、
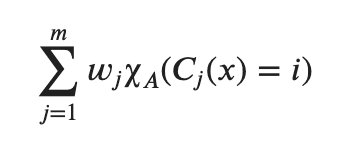
を計算すると、0.2 × i_0 + 0.2 × i_0 + 0.6 × i_1 となります。
(i_0:0と予測した時に1が返ってくる。i_1 :1と予測した時に1が返ってくる。今回であれば、0 or 1となる)
i = 0の時、0.2 × i_0 + 0.2 × i_0 + 0.6 × i_1 = 0.2 × 1+ 0.2 × 1 + 0.6 × 0 = 0.4
i = 1の時、0.2 × i_0 + 0.2 × i_0 + 0.6 × i_1 = 0.2 × 0+ 0.2 × 0 + 0.6 × 1 = 0.6
つまり、argmaxにより、最大にするiは1となり、最終予測は1となります。
少し、数式をつかわない表現をすれば、C3という専門家の声はC1やC2の専門家3人分の権威を持つという感じです。
つまり、今回、C3の人が「1」といえば、C1, C2が団結しても所詮2人ですので、1人分足りないので、結局ゴリ押しでC3の判断が採用されるという感じです。
・pythonで確認
では、ここまでの数学をpythonでも確認してみましょう。
import numpy as np
print(np.bincount([0, 0, 1]))
print(np.bincount([0, 0, 1], weights=(0.2, 0.2, 0.6)))
print(np.bincount([0, 0, 1], weights=(0.2, 0.3, 0.6)))
np.argmax(np.bincount([0, 0, 1], weights=(0.2, 0.2, 0.6)))
numpyのbincountを使うと、引数のリストの中の各要素の個数が返り、weightsで重みを指定すると、対応する要素に重みが加えられ加算されいく。
さて、前回も出てきた気がしますが、分類器には単に予測したラベルを返す以外にもそれぞれのクラスラベルがでてくる確率を返すpredict_probaというメソッドがありました。
ここで、アンサンブル学習に使う分類器自体がうまく調整されているのであれば、クラスラベルそのものを使わずにそれぞれの確率を用いても効果がある時があります。
少し、数式に戻ると(苦手な方は流し見でおけです ^^;)
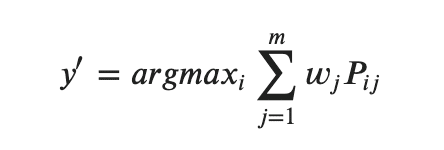
PijをCjがi と予測する確率を意味します。
具体的に数値を用いると、
今、C1 ⇨ [0.9, 0.1], C2 ⇨ [0.8, 0.2], C3 ⇨ [0.4, 0.6]という確率を持っているとします(それぞれ0, 1と返す確率)
ここに、重みがそれぞれ(0.2, 0.2, 0.6) を加えると、
i = 0: 0.2 × 0.9+ 0.2 × 0.8 + 0.6 × 0.4 = 0.58
i = 1: 0.2 × 0.1+ 0.2 × 0.2 + 0.6 × 0.6 = 0.42
つまり、今回はargmaxを取れば0が返ってきます。
これをpythonで見てみましょう。
ex = np.array([[0.9, 0.1], [0.8, 0.2], [0.4, 0.6]])
print(np.average(ex, axis=0, weights=(0.2, 0.2, 0.6)))
np.argmax(np.average(ex, axis=0, weights=(0.2, 0.2, 0.6)))
numpyのaverageは指定したaxisに従って、重み付けされた要素を計算します。
・実際に多数決の原理を使ってpython で予測を行ってみよう!
ここからは少し数学から離れて、pythonでコーディングして挙動などを確かめてみます。
・データの準備
今回sklearn.datasetsの有名なアヤメデータセットを用います。
すこし、分類を難しくするため、用いる特徴量を2つにしぼり、なおかつROC曲線を使う都合上、予測するクラスも2種類のみとします。
この辺はあくまで想定なので、特に気にせず進めておけです。
では、コードから。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
iris = datasets.load_iris()
X, y = iris.data[50:, [1, 2]], iris.target[50:]
le = LabelEncoder()
y = le.fit_transform(y)次に、訓練用、テスト用に分けます。(関数の詳細は前回を参照)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, stratify=y, random_state=1)・用いる分類器の準備
今回分類器は
・ロジスティック
・決定木
・k最近傍法(K近傍法と書いたりします)
です
(かく分類器の詳細は割愛しますが、関数のパラメータなどは後述)
これらをk分割交差検証(今回はk=10)でそれぞれの性能を最初に評価してみましょう。
では、コードから
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
from sklearn.model_selection import cross_val_score
# ロジスティック
clf1 = LogisticRegression(penalty='l2', C=0.001, random_state=1)
# 決定木
clf2 = DecisionTreeClassifier(max_depth=1, criterion='entropy', random_state=0)
# k最近傍法
clf3 = KNeighborsClassifier(n_neighbors=1, p=2, metric='minkowski')
# Pipelineにより、標準化→分類器の流れを一括で処理。
# 決定木に関しては、標準化の処理は不要
pipe1 = Pipeline([['sc', StandardScaler()], ['clf', clf1]])
pipe3 = Pipeline([['sc', StandardScaler()], ['clf', clf3]])
# それぞれの分類器にラベルをつけるため、準備
clf_labels = ['Logistic regression', 'Decision tree', 'KNN']
print('10-fold corss validation: \n')
clfs = [pipe1, clf2, pipe3]
for clf, label in zip(clfs, clf_labels):
scores = cross_val_score(estimator=clf,
X=X_train, y=y_train,
cv=10,
scoring='roc_auc') # 今回の精度評価はauc
print(f'ROC AUC: {np.mean(scores):.3f} +/- {np.std(scores):.3f} [{label}]')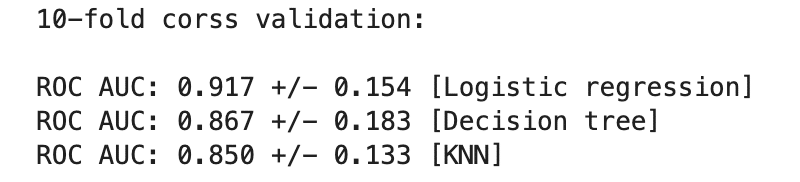
(それぞれの関数に関しての説明は一つの章をすぐ下に設けます)
結果を見ると、Logisicが一番良いですが、どの分類器も似たり寄ったりな精度であることがわかります。
・(補足)DecisionTree、KNN、Pipelineの関数について
(私も含めて)おいおい、DecisionTree、KNN、Pipelineなんてかってに使われても!という方に、これらの関数について公式ドキュメントに準じながらみていきましょう。
- DecisionTreeClassifier
class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, ccp_alpha=0.0)
パラメータがたっくさんあるので、割愛できる部分は割愛します。。。
基本的に必要な時に見返すとかでいいので、飛ばしてもらっても構いません!
criterion(日本語訳は「基準」): {'gini', 'entropy'}のいずれかを指定
------------
giniとはジニ不純度(ジニ係数)を意味します。
がっつり説明するとなると膨大な量になります。。
むちゃ簡単に言えば、最初の状態からどのくらいはっきりと分割できるようになったのかを見て判断するもの(非常に曖昧な説明であることをご了承ください)
entropyとは物理などで出てくる、煩雑さなどを意味し、エントロピーが大きいとは、不純度が高いことを指し、つまりは分類はしたけど結構雑に分類しちゃっているってイメージです。
何がどう違うのか、となりますが、エントロピーは分類のみ、ジニ係数は分類と回帰に使えます。
また、エントロピーはN分木、ジニ係数は2分木が生成されます(厳密に言えば、エントロピーやジニ係数を用いた決定木のアルゴリズムが生む木)
ちなみに、大抵はginiを扱う。。
------------
splitter: {'best', 'random'}から指定。探索方法をbest(全項目で全閾値を施行)か、random(分岐項目randomに選択するイメージ。)かで選ぶ。
max_depth: 決定木の深さ。
min_samples_split: 分岐した中に含まれるサンプル数の最小値。例えば、分類したあと、1つしかサンプルがない場合は過剰学習している可能性があるため、それを防ぐ
min_samples_leaf: 分岐を作成する分岐先のデータ数が指定数以上でないと作成されない
min_weight_fraction_leaf: sample_weightの重みに従って、min_samples_leafの総和を計算して、指定以上の木の生成しか行わないようにする
max_features: int, float, {“auto”, “sqrt”, “log2”}で指定。best splitを行う際に考慮する特徴量の個数を選択します。
random_state: 割愛
max_leaf_nodes: 決定木の葉の数を制限
min_impurity_decrease: 指定した数値以下の不純度が、分岐したnodeに得られない場合は分岐を抑制
min_impurity_split: (将来的にはmin_impurity_decreaseとなるそう。。)
class_weight: 各クラスラベルの重み
ccp_alpha: Minimal Cost-Complexity Pruningという手法のパラメータ設定(割愛)
DecisionTreeClassifierのもつ属性たち
classes_: クラスラベルのリストが出力されます。
feature_importances_: 特徴量の重要性がarray形式で出力
max_features_: 条件分岐に利用した最大説明変数(パラメータのmax_featuresに対応)を推測している
n_classes_: それぞれに含まれるクラスの数
n_features_: 学習する特徴量の数
n_outputs_: 出力結果の数
tree_: sklearn.tree._tree.Treeに準じたobjectが出力。これにより、sklearn.tree._tree.Treeと同じ属性を使うことができる。
各属性の出力一覧。
clf_ = DecisionTreeClassifier(max_depth=1, criterion='entropy', random_state=0)
print(clf_.fit(X_train, y_train).classes_)
print(clf_.fit(X_train, y_train).feature_importances_)
print(clf_.fit(X_train, y_train).max_features_)
print(clf_.fit(X_train, y_train).n_classes_)
print(clf_.fit(X_train, y_train).n_features_)
print(clf_.fit(X_train, y_train).n_outputs_)
print(clf_.fit(X_train, y_train).tree_)
print(clf_.fit(X_train, y_train).tree_.impurity)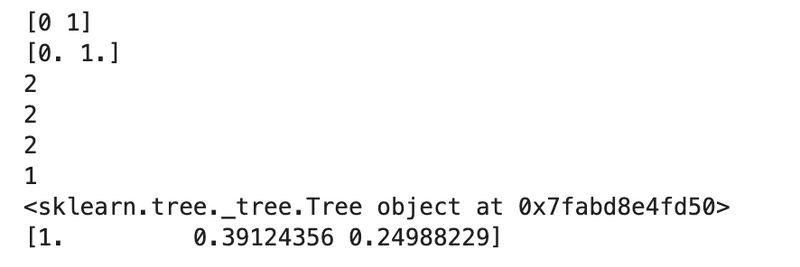
- KNN
・そもそもKNN(K-nearest neighbors)って??
KNNの説明などは世の中にたくさん解説されているため、ここで深掘りする必要もない気がしますが、自分があまり触れたことない部分だったので、ある意味自分のために解説しようと思います。
まず、ざっくりと説明すると、
ある入力されたデータから、(ユークリッド距離で)一番近い順にk個データを取り出して、その中で一番多かったクラスラベルを採用する
という方法です。
かなりシンプルな方法であり、学習を事前に必要としないことが特徴的です。
少し図を交えて解説していきます。
まず、以下のようなデータが存在している領域を考えます。

そこに⭐︎のデータが入力された時、これをどちらのクラスに分類すれば良いのかを考えます。
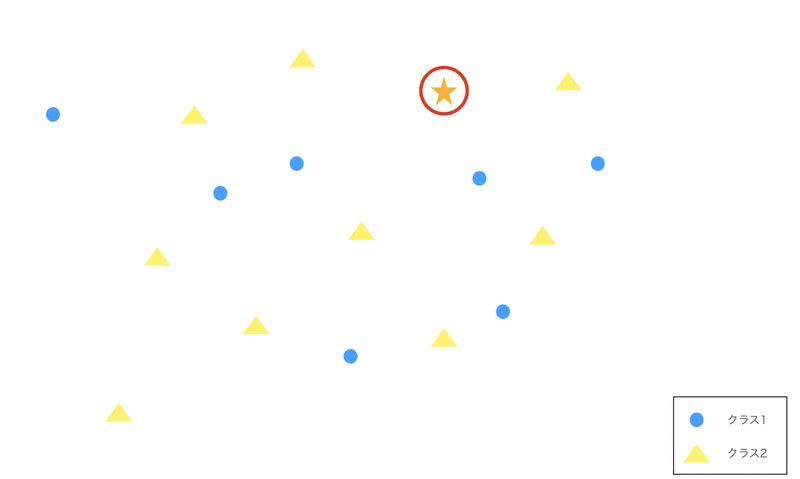
KNNとして、今回上から3つ単純なユークリッド距離(いわゆる距離と思って大丈夫です)で近いものをとってくるとします。
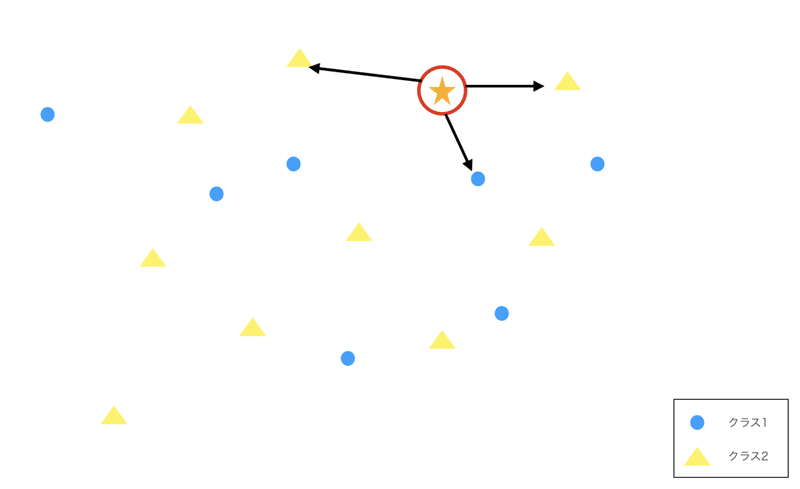
今回のデータで言えば、⭐︎に関しては▲が2つ、●が一つなので、予測は▲として判定します。
これがざっくりとしたKNNの外観です。
・KNNの関数について
では、pythonで扱うにあたり、公式ドキュメントを参照していきましょう。
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, *, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None, **kwargs)
n_neighbors: 先程のkの数値。上から何個のデータを参照するか。
weights: {'uniform', 'distance'} or 関数で指定。近接したそれぞれのデータ点に重みをどのようにつけるか?
algorithm: {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}で指定。先程はユークリッド距離で指定しましたが、指定したアルゴリズムでどのデータが最も近接しているのかを測ります。
leaf_size: ‘ball_tree’, ‘kd_tree’を指定した時の葉のサイズ
p: Minkowski metricに使われるpowerパラメータの指定。p=1の時、マンハッタン距離(L1norm)を利用、p=2なら、ユークリッド距離(L2norm)を適用
metric: str or 関数で指定(default=’minkowski’)距離の計測方法。
ちなみに、ミンコフスキー距離とは、マンハッタン距離やユークリッド距離のp=nで一般化したもの。
ちゃんと書けばベクトルxの要素をそれぞれn乗した総和をn乗根したもの。
metric_params: 計測する関数にargumentを追加したい時に辞書で指定
n_jobs: 計算時に使いたいCPUの数
KNNのもつ属性は以下。
classes_: DecisionTreeと同じなので割愛
effective_metric_: 計測した方法を出力。今回p=2であれば、‘euclidean’(ユークリッド)が返り値
effective_metric_params_: metric_paramsで指定したものがあればそれを出力。
n_samples_fit_: 学習したデータの数
outputs_2d_: 学習時に目的変数のshapeが(n_samples, ) or (n_samples, 1)である時はFalseを返す
pythonで属性をそれぞれ確認していく。
clf_ = KNeighborsClassifier(n_neighbors=3, p=2)
clf2_ = KNeighborsClassifier(n_neighbors=3, p=1)
print(clf_.fit(X_train, y_train).classes_)
print(clf_.fit(X_train, y_train).effective_metric_)
print(clf2_.fit(X_train, y_train).effective_metric_)
print(clf_.fit(X_train, y_train).effective_metric_params_)
print(clf_.fit(X_train, y_train).n_samples_fit_)
print(clf_.fit(X_train, y_train).outputs_2d_)
メソッドに関しては、fit, predict, predict_proba, score, get(set)_paramsの他に、kneighbors, kneighbors_graphというメソッドを保持しています。
kneighbors()により、説明変数のK-neiborsたちの距離とそれに対応するデータのインデックスが返ってきます。
clf_ = KNeighborsClassifier(n_neighbors=3, p=2)
x = clf_.fit(X_train, y_train)
print(type(x.kneighbors()))
for i in range(10):
print(x.kneighbors()[0][i], x.kneighbors()[1][i])
print('--'*10)(全部出さずに上から10個だけ見ます。)

・Pipelineについて
前回まではmake_pipelineを使ってきましたが、make_pipelineはPipelineの簡素なバージョンという位置付けらしいので、基本的にはPipelineに慣れておく方がいいということを聞いたりします。(自分調べ。)
基本的にはmake_pipelineと同じなので、割愛できる部分は割愛していきます。
class sklearn.pipeline.Pipeline(steps, *, memory=None, verbose=False)
steps: make_pipelineと違い、リスト形式での格納が必要。また、それぞれの学習器などはtupleもしくはlistで['name', 'transform'] or ('name', 'transform')で繋げていきます。
また、こちらもmake_pipeline同様、最後に格納するのは必ず推定器である必要があります。
memory, verboseは割愛
メソッドなどは省略します。
- (補足終わり)
- 実際に多数決での予測を実装
長い補足も終わり、話を戻します。
先ほどまでは単体の分類器がどの程度の精度を持っているのか事前に確認してきました。
さて、ここから本題である多数決モデルを構築し、どの程度精度が変化するのかを見ていくことにします。
sklearn.ensemble.VotingClassifierを使っていきます。
from sklearn.ensemble import VotingClassifier
estimators = [('lr', pipe1), ('decision_tree', clf2), ('KNN', pipe3)]
# majority voting classifier
mv_clf = VotingClassifier(estimators=estimators,
voting='soft') # argmaxを使う場合、'soft'に指定。
clf_labels += ['Majority voting']
all_clf = [pipe1, clf2, pipe3, mv_clf]
for clf, label in zip(all_clf, clf_labels):
scores = cross_val_score(estimator=clf,
X=X_train, y=y_train,
cv=10,
scoring='roc_auc') # 今回の精度評価はauc
print(f'ROC AUC: {np.mean(scores):.3f} +/- {np.std(scores):.3f} [{label}]')
先に結果を見ると、明らかに精度が上がったことがわかります。
ここにアンサンブル学習の強みを感じることができます。
class sklearn.ensemble.VotingClassifier(estimators, *, voting='hard', weights=None, n_jobs=None, flatten_transform=True, verbose=False)
estimators: タプル(name, estimator)をリスト形式で繋げて指定。
voting: {'hard', 'soft'}で指定。hardの場合は多数決によるクラスラベルの予測を行う。softを指定すると、先ほど紹介したargmaxの形式でクラスラベルの予測を行う
weights: いわゆる重み
n_jobs: 割愛
flatten_transform: voting='soft'指定したとき、
Trueにしておくと、.transformメソッドを使用した場合、shape=(n_samples, 分類器の数*クラスラベルの数)で出力される。
False指定時はshape= (分類器の数, n_samples, クラスラベルの数)となる
verbose: 省略。
flattern_transformの挙動のみ確認しておく
mv_clf_ = VotingClassifier(estimators=estimators, voting='soft', flatten_transform=True)
mv_clf2_ = VotingClassifier(estimators=estimators, voting='soft', flatten_transform=False)
mv_clf_.fit(X_train, y_train)
mv_clf2_.fit(X_train, y_train)
print(mv_clf_.transform(X_train).shape)
print(mv_clf2_.transform(X_train).shape)
メソッドに関しても一旦割愛する。
・アンサンブル分類器をROC曲線で可視化
前回にて、ROC曲線でFPRとTPRの関係性をみるROC曲線を学んできました。
今回はこのROC曲線を用いて、それぞれのROC 並びにAUCの値も見ていきます。
from sklearn.metrics import roc_curve
from sklearn.metrics import auc
plt.figure(figsize=(10, 10))
colors = ['black', 'orange', 'blue', 'green']
linestyles = [':', '--', '-.', '-']
for clf, label, color, linestyle in zip(all_clf, clf_labels, colors, linestyles):
# 通常の陽性ラベルは1であるため、1列目を取得する
y_pred = clf.fit(X_train, y_train).predict_proba(X_test)[:, 1]
fpr, tpr, thresholds = roc_curve(y_true=y_test, y_score=y_pred)
roc_auc = auc(fpr, tpr)
plt.plot(fpr, tpr, color=color, linestyle=linestyle, label=f'{label} (auc={roc_auc})')
plt.legend(loc='lower right')
plt.plot([0,1], [0, 1], linestyle='--', color='gray', linewidth=2)
plt.xlim([-0.1, 1.1])
plt.ylim([-0.1, 1.1])
plt.grid(alpha=0.5)
plt.xlabel('False Positive rate (FPR)')
plt.ylabel('True Positive rate (TPR)')
plt.show()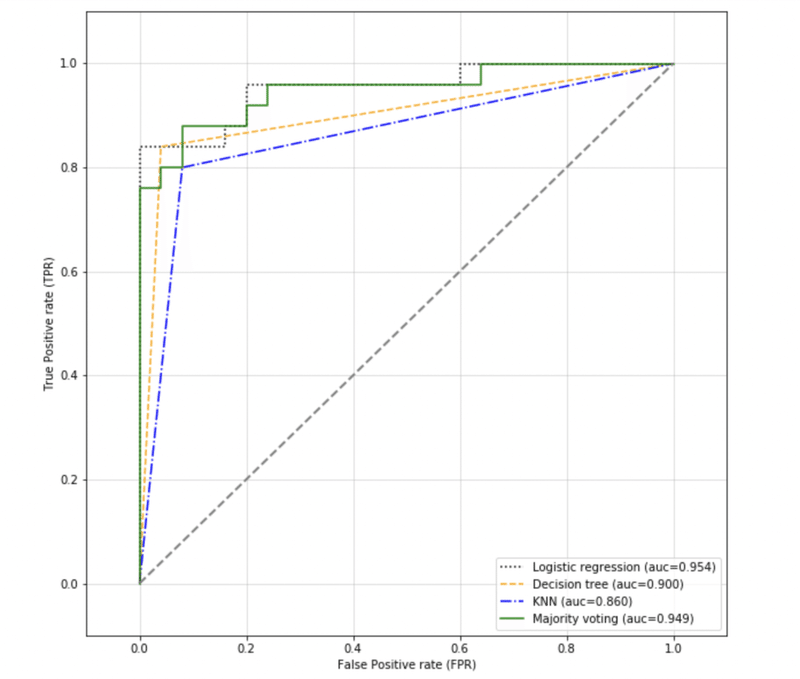
コードに関しては前回までのものなので割愛します。
実際に見てみると今回aucの値は実はLogisticRegressionが一番高いという結果になりました。
これは純粋にtest のサンプルサイズが小さいことがあります。
さて、少し脇道にそれて、どのように決定領域が引かれているのかを図示して確認してみましょう。
その前に、決定木以外は標準化を行っていたものの、決定領域の際に尺度を揃えた方が見やすいため、決定木に入れる時も標準化して図示していくことにします。
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
from itertools import product
# 決定領域を描画する最小限・最大値を生成
X_min = X_train_std[:, 0].min() - 1
X_max = X_train_std[:, 0].max() + 1
y_min = X_train_std[:, 1].min() - 1
y_max = X_train_std[:, 1].max() + 1
# グリッドポイントを生成
xx, yy = np.meshgrid(np.arange(X_min, X_max, 0.1), np.arange(y_min, y_max, 0.1))
# 描画領域の定義
fig, axarray = plt.subplots(2, 2, sharex='col', sharey='row', figsize=(7, 5))
# 決定領域のプロット
# 変数idxは各分類器を描画する行と列の位置を表すタプル
idexes = product([0, 1], [0, 1])
for idx, clf, label in zip(idexes, all_clf, clf_labels):
clf.fit(X_train_std, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
axarray[idx[0], idx[1]].contourf(xx, yy, Z, alpha=0.3)
axarray[idx[0], idx[1]].scatter(X_train_std[y_train==0, 0],
X_train_std[y_train==0, 1],
c='blue', marker='^', s=50)
axarray[idx[0], idx[1]].scatter(X_train_std[y_train==1, 0],
X_train_std[y_train==1, 1],
c='green', marker='o', s=50)
axarray[idx[0], idx[1]].set_title(label)
plt.text(-3.5, -5, s='Sepal width [standardize]', ha='center', va='center', fontsize=12)
plt.text(-12.5, 4.5, s='Petal length [standardize]', ha='center', va='center', fontsize=12, rotation=90)
plt.show()描画するコードなので、基本は割愛します。
ちょこちょこと、細切れで補足を足します。
itertools.productはデカルト積(すごい簡単に言えば、全部の組み合わせ)を返します。
あ、ここはデカルト積使えばいいじゃん!って思えるようになる自分が想像できないのですが、一応。。
idexes = product([0, 1], [0, 1])
for idx in idexes:
print(idx)
idexes = product([0, 1], [0, 1], [1, 2])
for idx in idexes:
print(idx)
numpy.meshgridに関しての説明は割愛しますが、したのURLが参考になります。
https://deepage.net/features/numpy-meshgrid.html
時たま3Dグラフなどを描画するコードで出てきたりします。。
ちなみに、その後に出てくるxx.ravel()というのは多次元配列を一次元のリスト形式で返すものです。
numpy.c_というのはいわゆるnumpy.vstackと同じような使い方です。
途中経過の形がどう変わるのかを逐次printしたコードを補足的に確認してみましょう。(図は上記と同じため、カット)
sc = StandardScaler()
X_train_std = sc.fit_transform(X_train)
from itertools import product
# 決定領域を描画する最小限・最大値を生成
X_min = X_train_std[:, 0].min() - 1
X_max = X_train_std[:, 0].max() + 1
y_min = X_train_std[:, 1].min() - 1
y_max = X_train_std[:, 1].max() + 1
# グリッドポイントを生成
xx, yy = np.meshgrid(np.arange(X_min, X_max, 0.1), np.arange(y_min, y_max, 0.1))
print(f'length np.arange(X_min, X_max, 0.1): {len(np.arange(X_min, X_max, 0.1))}')
print(f'length np.arange(y_min, y_max, 0.1): {len(np.arange(y_min, y_max, 0.1))}')
print(f'xx: {xx.shape}')
print(f'yy: {yy.shape}')
# 描画領域の定義
fig, axarray = plt.subplots(2, 2, sharex='col', sharey='row', figsize=(7, 5))
# 決定領域のプロット
# 変数idxは各分類器を描画する行と列の位置を表すタプル
idexes = product([0, 1], [0, 1])
for idx, clf, label in zip(idexes, all_clf, clf_labels):
clf.fit(X_train_std, y_train)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
print(f'xx.ravel(): {xx.ravel()[:3]}')
print(f'np.c_[xx.ravel(), yy.ravel()]: {np.c_[xx.ravel(), yy.ravel()].shape}')
print(f'np.c_[xx.ravel(), yy.ravel()]: \n{np.c_[xx.ravel(), yy.ravel()][:3]}')
Z = Z.reshape(xx.shape)
axarray[idx[0], idx[1]].contourf(xx, yy, Z, alpha=0.3)
axarray[idx[0], idx[1]].scatter(X_train_std[y_train==0, 0],
X_train_std[y_train==0, 1],
c='blue', marker='^', s=50)
axarray[idx[0], idx[1]].scatter(X_train_std[y_train==1, 0],
X_train_std[y_train==1, 1],
c='green', marker='o', s=50)
axarray[idx[0], idx[1]].set_title(label)
plt.text(-3.5, -5, s='Sepal width [standardize]', ha='center', va='center', fontsize=12)
plt.text(-12.5, 4.5, s='Petal length [standardize]', ha='center', va='center', fontsize=12, rotation=90)
plt.show()
少しそれぞれの形や中身の理解が深まりましたでしょうか。。。
・アンサンブル学習の個々の分類器をGridSearchでチューニング
さて、ハイパーパラメータをチューニングするにはGridSearchが有効であることを前回紹介したので、せっかくなので使ってみましょう。
その前に、VotingClassifierにはget_paramsメソッドがあり、どういうパラメータを持っているのかを一括で確認できる方法があります。
mv_clf.get_params()


なっがいですが、特に注意深くみる必要はないですが、それぞれ命名した名前と調整できるハイパーパラメータの一覧が格納されています。
便利なのは、この中の名前をそのまま使うだけで調整が可能であるということです。
実際に見ていきましょう。
from sklearn.model_selection import GridSearchCV
params = {'decision_tree__max_depth': [1, 2, 3],
'lr__clf__C': [0.001, 0.1, 10, 100],
'KNN__clf__n_neighbors': [1, 3, 5]}
gs = GridSearchCV(estimator=mv_clf,
param_grid=params,
cv=10, scoring='roc_auc')
gs.fit(X_train, y_train)
for r, _ in enumerate(gs.cv_results_['mean_test_score']):
print(f"{gs.cv_results_['mean_test_score'][r]:.3f} +/- {gs.cv_results_['std_test_score'][r]:.3f}\n \
{gs.cv_results_['params'][r]}")
print('-'*10)
print(f'Best params: {gs.best_params_}')
print(f'Accuracy: {gs.best_score_}')
出力結果の上部分は割愛しています。
結果を見ると、max_depthやKNNの数は精度に影響を与えず、結果的にC(逆正則のパラメータ・罰則)を一番弱くした場合において最大精度を出していることがわかりました。
・一旦終わり
一区切りつきましたので、次回に持ち越します。
次回はバギング・アダブーストというアンサンブル学習の手法について見ていく。
この記事が気に入ったらサポートをしてみませんか?