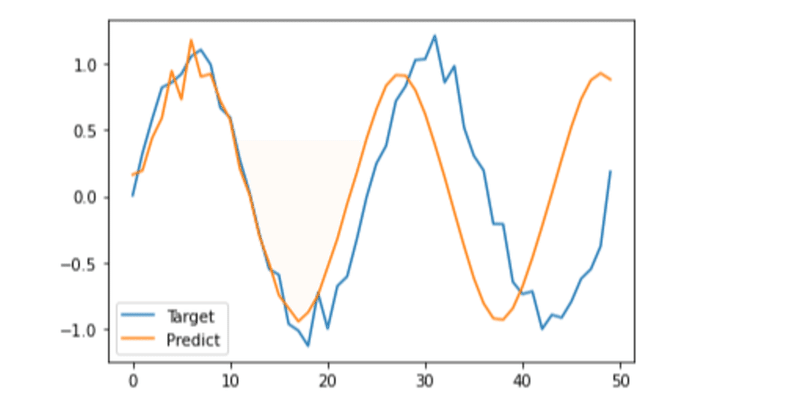
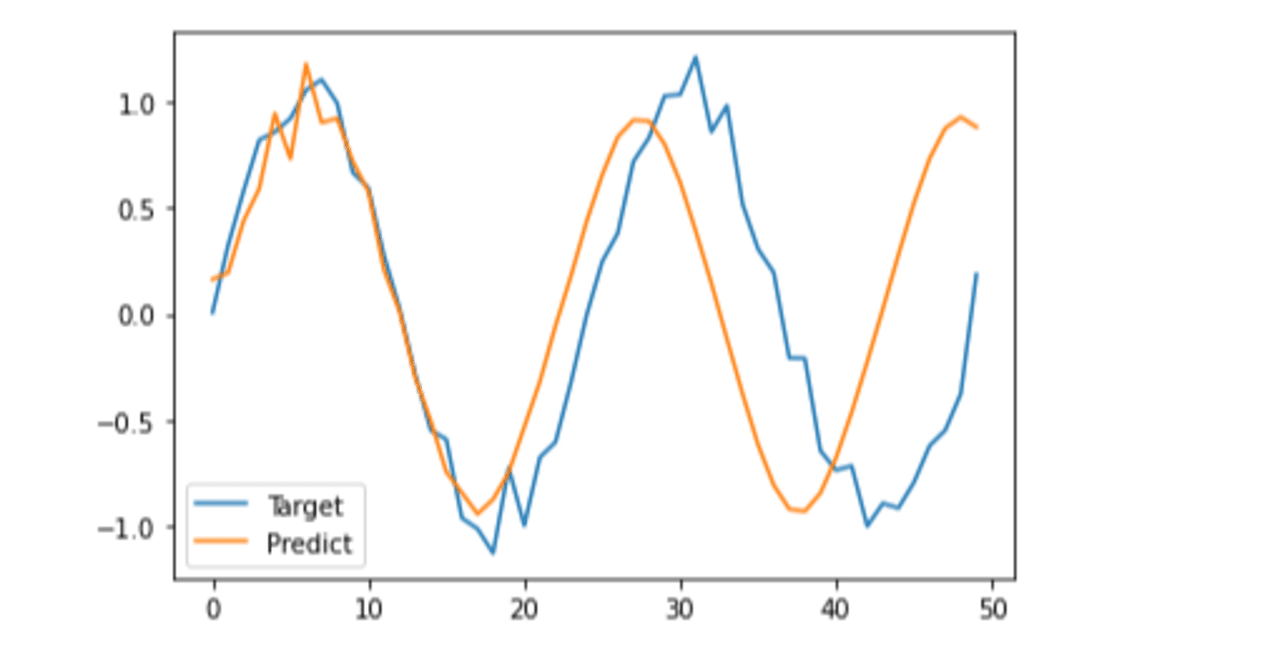
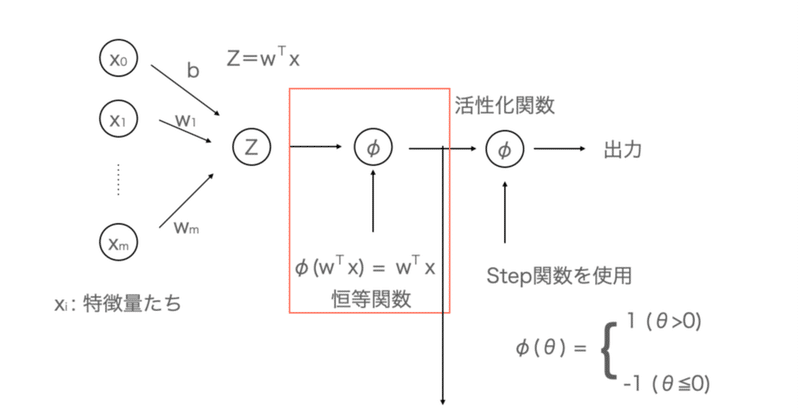
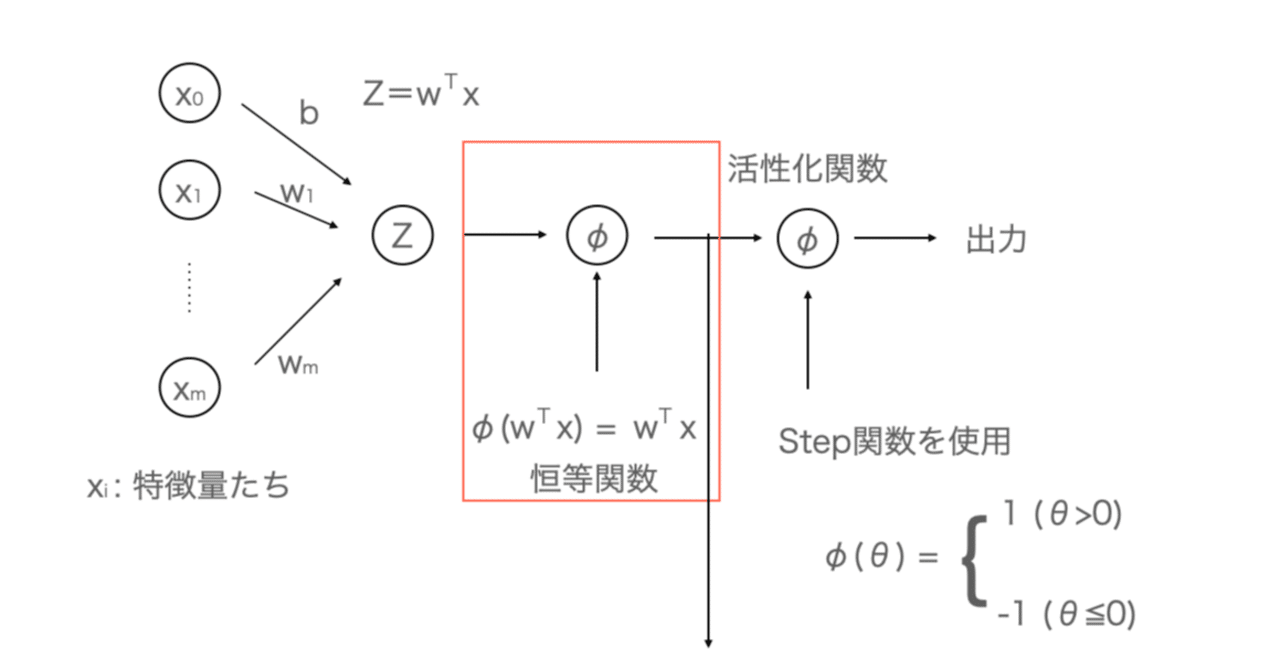
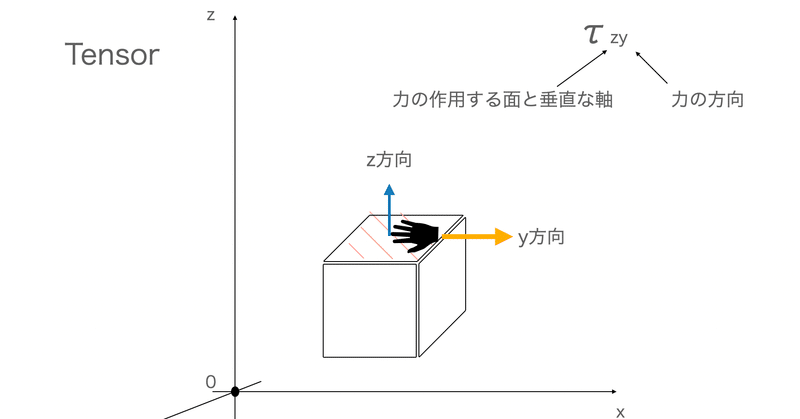
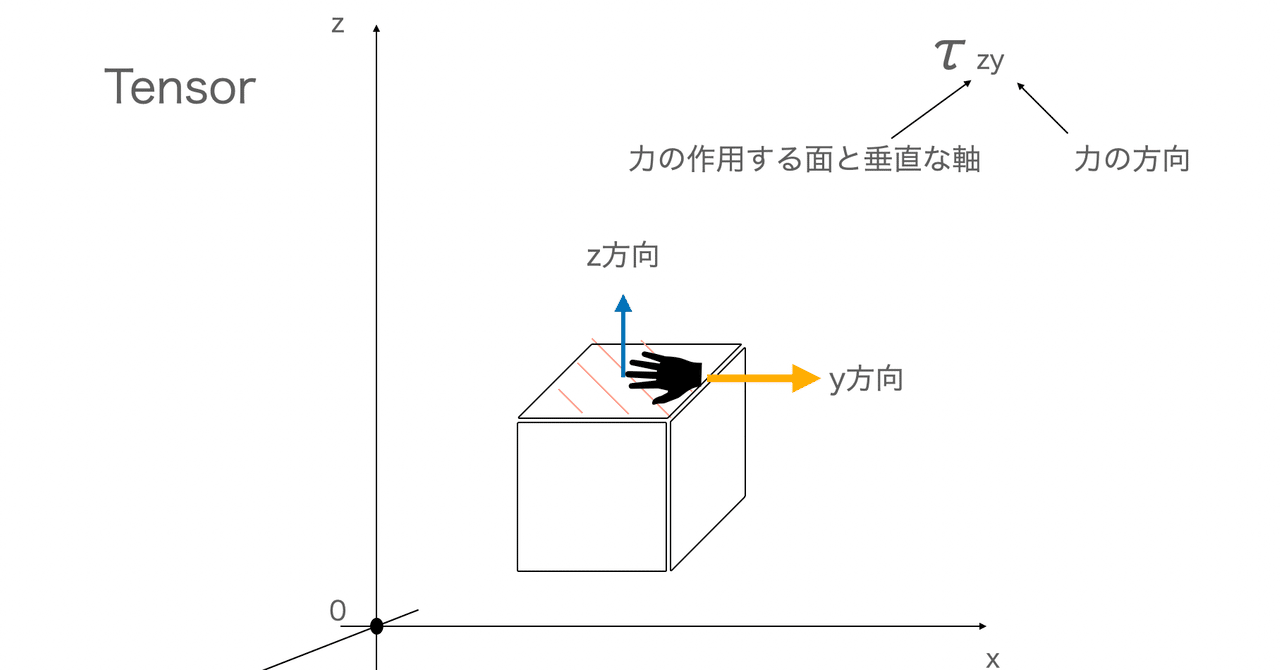
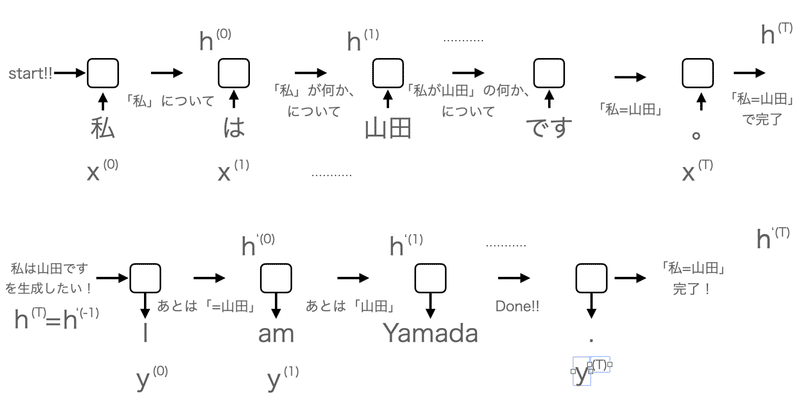
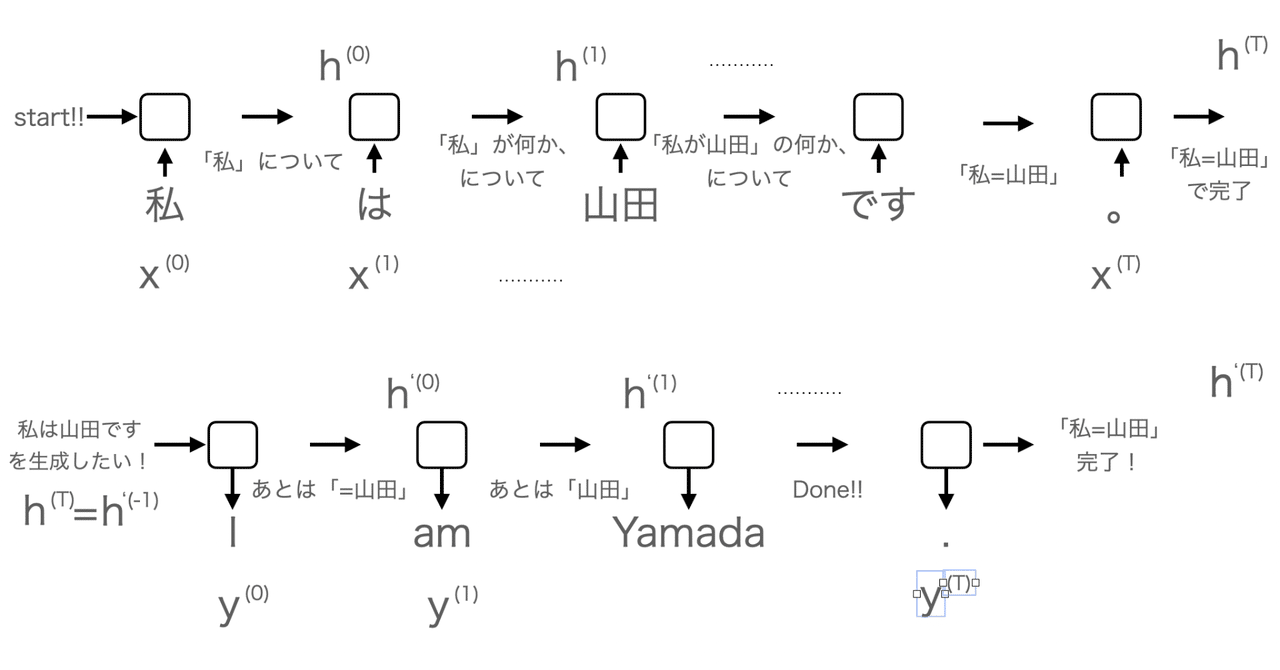
機械学習の関数たち〜sigmoid, tanh, softmaxとか〜
tensorflowもなかなかに本格的になってきました。
次回以降seq2seqを扱い、次にtransformer, attention, BERTに行けたらと思います(ここから自分の理解も正しくしておかないとなので、時間かかりそぅ。。)
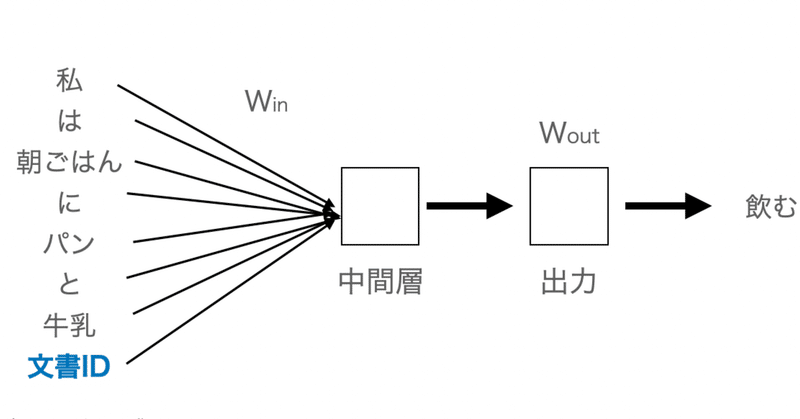
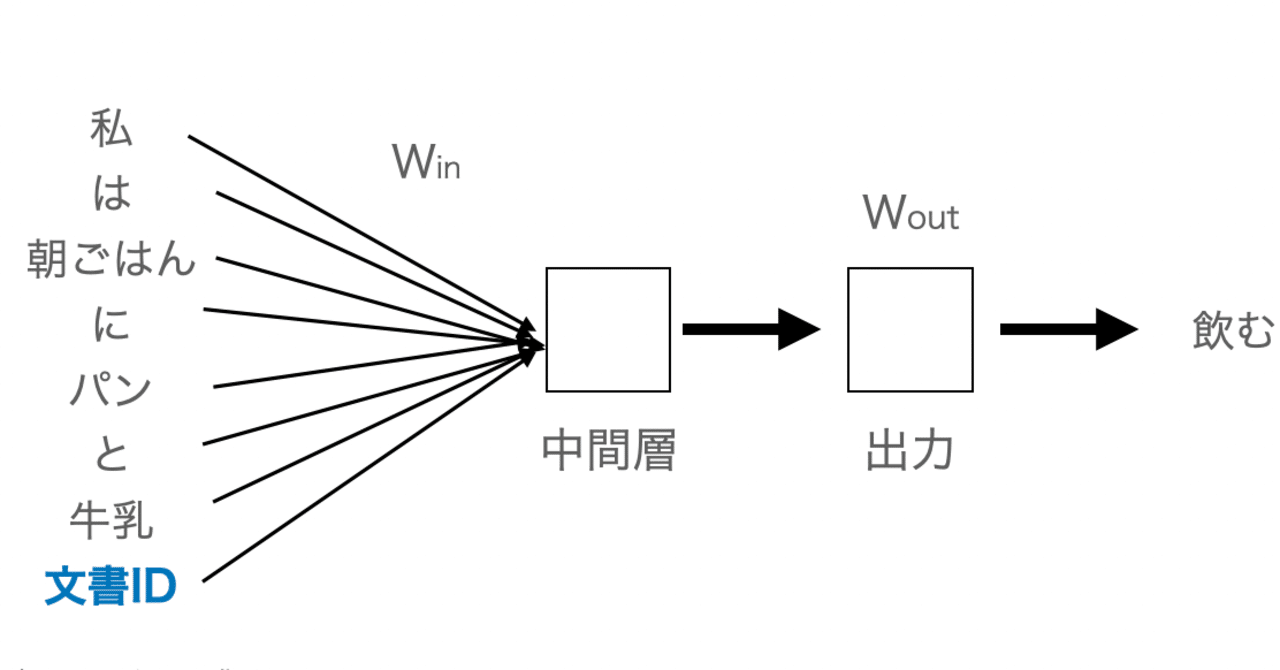
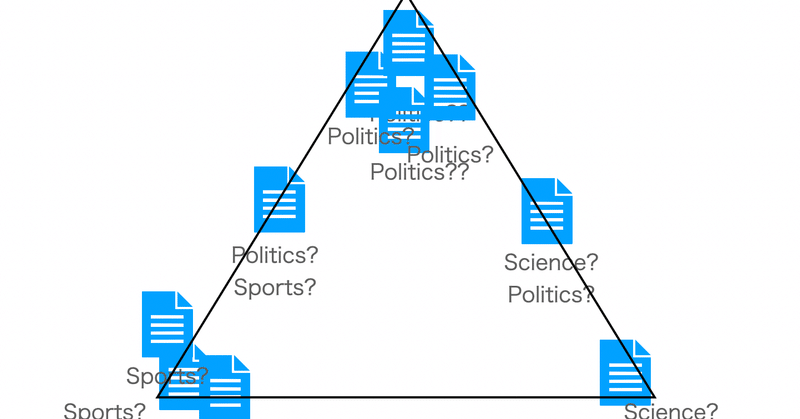
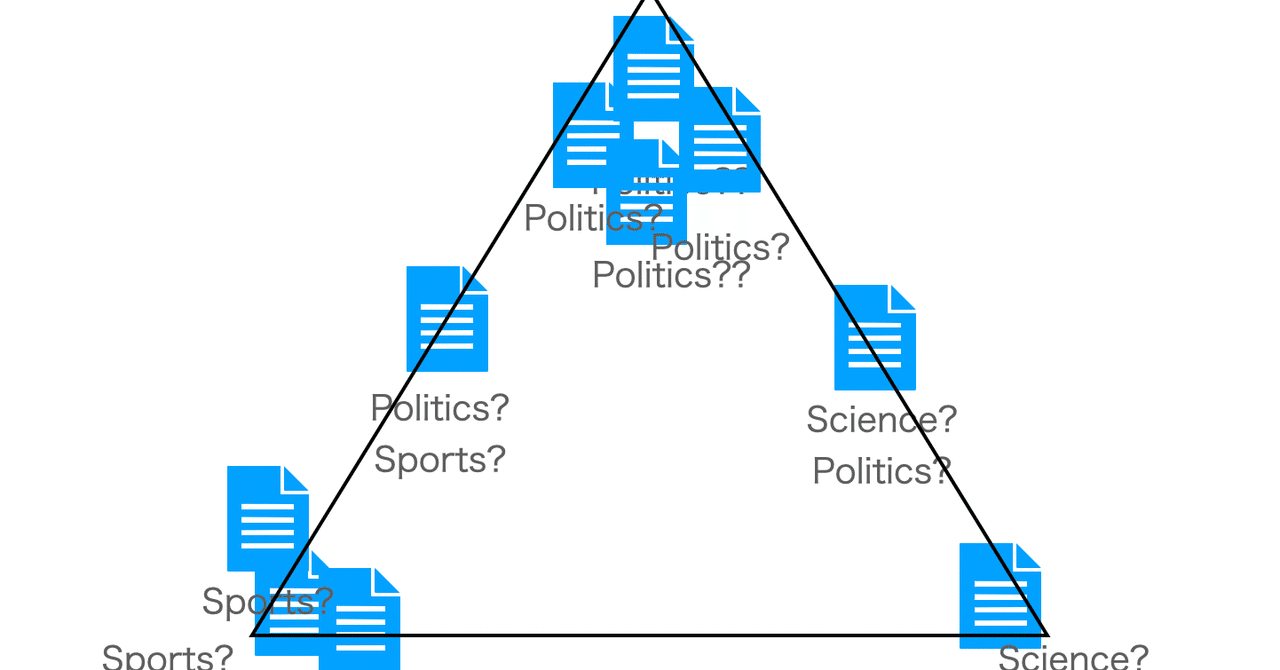
本格的始める前に、いままで扱わなかった機械学習の関数たちをちょっとだけみておくことにします。
noteで関数の表記をすることが非常に面倒で、
かえってわかりにくくなる可能性もあるな〜と思っているので、そのへんはご了承ください。
(あ