RedAmber - Rubyの新しいデータフレームライブラリ

(2023-05-18追記)
最新の情報に更新しました。
RedAmberとは?
RedAmberは、プログラミング言語Rubyで書かれたデータフレームライブラリです。
データフレームとは、SQLのテーブル、Excelのワークシートのようなひとまとまりの2次元データで、Pythonのpandasが扱うものというと分かる人が多いかもしれません。
残念なことに、Rubyはデータ処理の世界で使えるツールが充実しているとは言えません。それでも、データの可視化、機械学習、各種データの集積でRed Data Toolsプロジェクトが頑張っています。また、効率的に大量のデータをメモリー上で処理するためのフレームワークであるApache ArrowにはRuby実装であるRed Arrowがあり、大規模データ処理でRubyを使う環境は少しずつ整ってきています。
RedAmberはRed Arrowの機能を利用して、PythonのpandasやRのdplyr/tidyrでやるようなことをRubyらしい書き方でできるようにするためのライブラリです。
2022年度Rubyアソシエーション開発助成に採択されたプロジェクトとして開発を進めました。
インストール
必要なもの
Ruby 3.0以上
Arrow 11.0.0以上
Apache Arrowは今は頻繁に機能追加と改善を重ねていて約3ヶ月毎にメジャーバージョンアップしています。
最低限、Apache Arrow本体とApache Arrow GLib(Cバインディング)を入れる必要があります。Ruby実装はC++実装のバインディングであるC GLib実装から自動変換で作られているからです(Apache Arrowの最新情報(2022年5月版))。
Red Arrow 11.0.0以上
RedAmber 0.4.2(2023年4月2日時点の最新版)以上
Red ArrowとRedAmberはRubyGemsから入れられます。
インストールの詳細は最新のGithubのREADMEを参照してください。私はmacOSまたはWindowsのWSL2上のUbuntuで使っています。
Dockerイメージ、またはBinderで
RubyData Docker Stacks に@mrknさんがRedAmberを入れてくださっていて、Dockerイメージから試してみる事ができます。また、Binder ではブラウザからRedAmberが動くJupyter Notebookを試す事ができます(起動に時間がかかるのと、アクセス回数に制限があるので運が良ければ)。
試してみる
ここではirb、またはirubyを有効にしたJupyter notebookで動かしたソース例と実行結果で紹介していきます。
今回はRed Data Toolsの`red-dataset-arrow`も必要ですので入れておいてください。Gemfileに最低限必要な行は次のようになります。
gem 'red-arrow', '~> 11.0.0'
gem 'red_amber'
gem 'red-datasets-arrow' # Optional, recommended if you use Red Datasetsライブラリの読み込み
require 'red_amber' # require 'red-amber' でもOK
include RedAmber # 名前が長いので include して使うのがお勧め
VERSION
=> 0.4.2Penguinsデータの例
有名なPenguinsのデータをRのデータセットからお借りして処理してみましょう。
require 'datasets-arrow'
dataset = Datasets::Penguins.new
penguins = DataFrame.new(dataset)
penguins
=>
#<RedAmber::DataFrame : 344 x 8 Vectors, 0x00000000000175e8>
species island bill_length_mm bill_depth_mm flipper_length_mm ... year
<string> <string> <double> <double> <uint8> ... <uint16>
0 Adelie Torgersen 39.1 18.7 181 ... 2007
1 Adelie Torgersen 39.5 17.4 186 ... 2007
2 Adelie Torgersen 40.3 18.0 195 ... 2007
3 Adelie Torgersen (nil) (nil) (nil) ... 2007
4 Adelie Torgersen 36.7 19.3 193 ... 2007
: : : : : : ... :
341 Gentoo Biscoe 50.4 15.7 222 ... 2009
342 Gentoo Biscoe 45.2 14.8 212 ... 2009
343 Gentoo Biscoe 49.9 16.1 213 ... 2009Jupyter labでの出力結果はこんな感じです。

penguins は RedAmber::DataFrame クラスのインスタンスで、344行のレコードがあり、8列のベクトルがあることがわかります。RedAmber では行方向のデータをレコード、列のデータをベクトル(または変数)と呼びます。
次のようにするとデータフレームの形状を調べられます。
penguins.shape
=> [344, 8]これは、次のArrayと同じで、[行, 列]の順番になっています。
[penguins.size, penguins.n_keys]
=> [344, 8]先ほどのデータフレームの表示の一番上の行に並んでいる species とか island は、列につけたラベルでキーと呼んでいます。 キーの一覧は下記のようにして取れます。キーは重複していないシンボルである必要があります。
penguins.keys
=>
[:species,
:island,
:bill_length_mm,
:bill_depth_mm,
:flipper_length_mm,
:body_mass_g,
:sex,
:year]データフレーム表示の2行目にある<>で囲まれた文字は、ベクトルのタイプです。 データフレームでは列方向のデータは同じ長さ、かつすべて同じ型である必要があります。タイプの一覧は次のようにして取れます。
penguins.types
=> [:string, :string, :double, :double, :uint8, :uint16, :string, :uint16]次のようにすると、Rのstr()のような詳細情報が得られます。
penguins.tdr
RedAmber::DataFrame : 344 x 8 Vectors
Vectors : 5 numeric, 3 strings
# key type level data_preview
0 :species string 3 {"Adelie"=>152, "Chinstrap"=>68, "Gentoo"=>124}
1 :island string 3 {"Torgersen"=>52, "Biscoe"=>168, "Dream"=>124}
2 :bill_length_mm double 165 [39.1, 39.5, 40.3, nil, 36.7, ... ], 2 nils
3 :bill_depth_mm double 81 [18.7, 17.4, 18.0, nil, 19.3, ... ], 2 nils
4 :flipper_length_mm uint8 56 [181, 186, 195, nil, 193, ... ], 2 nils
5 :body_mass_g uint16 95 [3750, 3800, 3250, nil, 3450, ... ], 2 nils
6 :sex string 3 {"male"=>168, "female"=>165, nil=>11}
7 :year uint16 3 {2007=>110, 2008=>114, 2009=>120}転置した見え方になっていますが、列のインデックス、キーの名前、列の型、レベル、 データのプレビューがコンパクトに表示できます。
レベルとはユニークなデータの数です。複数の NaN は1個と数えます。
レベルが5以下の場合、データは tally した形で表示します。これはRのfactor 型のような変数に対して便利な表示です。
RedAmber には factor 型はなく、普通は String で扱います。
数値変数に対してはつぎのようにして統計的要約を得ることができます。 この表自身も DataFrame となっています。
penguins.summary
=>
#<RedAmber::DataFrame : 5 x 9 Vectors, 0x000000000002bfac>
variables count mean std min 25% median ... max
<dictionary> <uint16> <double> <double> <double> <double> <double> ... <double>
0 bill_length_mm 342 43.92 5.46 32.1 39.23 44.38 ... 59.6
1 bill_depth_mm 342 17.15 1.97 13.1 15.6 17.32 ... 21.5
2 flipper_length_mm 342 200.92 14.06 172.0 190.0 197.0 ... 231.0
3 body_mass_g 342 4201.75 801.95 2700.0 3550.0 4031.5 ... 6300.0
4 year 344 2008.03 0.82 2007.0 2007.0 2008.0 ... 2009.0RedAmber のデータフレームは、Arrow のテーブルを使って実装されていますので、次のようにすると中身の table オブジェクトを取り出すことができます。
penguins.table
=>
(省略)Diamondsデータの例
それでは次に別のデータセットDiamondsを読み込んで、データフレームの操作をやってみましょう。
dataset = Datasets::Diamonds.new
diamonds = DataFrame.new(dataset)
=>
#<RedAmber::DataFrame : 53940 x 10 Vectors, 0x000000000002e414>
carat cut color clarity depth table price x ... z
<double> <string> <string> <string> <double> <double> <uint16> <double> ... <double>
0 0.23 Ideal E SI2 61.5 55.0 326 3.95 ... 2.43
1 0.21 Premium E SI1 59.8 61.0 326 3.89 ... 2.31
2 0.23 Good E VS1 56.9 65.0 327 4.05 ... 2.31
3 0.29 Premium I VS2 62.4 58.0 334 4.2 ... 2.63
4 0.31 Good J SI2 63.3 58.0 335 4.34 ... 2.75
: : : : : : : : : ... :
53937 0.7 Very Good D SI1 62.8 60.0 2757 5.66 ... 3.56
53938 0.86 Premium H SI2 61.0 58.0 2757 6.15 ... 3.74
53939 0.75 Ideal D SI2 62.2 55.0 2757 5.83 ... 3.64ここから、1カラット以上のレコードに対してカットの種類毎に価格の平均値を求める、というタスクをやってみましょう。 ちなみに詳細と統計値の要約も見ておきます。
diamonds.tdr
RedAmber::DataFrame : 53940 x 10 Vectors
Vectors : 7 numeric, 3 strings
# key type level data_preview
0 :carat double 273 [0.23, 0.21, 0.23, 0.29, 0.31, ... ]
1 :cut string 5 {"Ideal"=>21551, "Premium"=>13791, "Good"=>4906, "Very Good"=>12082, "Fair"=>1610}
2 :color string 7 ["E", "E", "E", "I", "J", ... ]
3 :clarity string 8 ["SI2", "SI1", "VS1", "VS2", "SI2", ... ]
4 :depth double 184 [61.5, 59.8, 56.9, 62.4, 63.3, ... ]
5 :table double 127 [55.0, 61.0, 65.0, 58.0, 58.0, ... ]
6 :price uint16 11602 [326, 326, 327, 334, 335, ... ]
7 :x double 554 [3.95, 3.89, 4.05, 4.2, 4.34, ... ]
8 :y double 552 [3.98, 3.84, 4.07, 4.23, 4.35, ... ]
9 :z double 375 [2.43, 2.31, 2.31, 2.63, 2.75, ... ]diamonds.summary
=>
#<RedAmber::DataFrame : 7 x 9 Vectors, 0x000000000003122c>
variables count mean std min 25% median 75% max
<dictionary> <uint16> <double> <double> <double> <double> <double> <double> <double>
0 carat 53940 0.8 0.47 0.2 0.4 0.7 1.04 5.01
1 depth 53940 61.75 1.43 43.0 61.0 61.81 62.5 79.0
2 table 53940 57.46 2.23 43.0 56.0 57.0 59.0 95.0
3 price 53940 3932.8 3989.44 326.0 950.0 2299.22 5324.25 18823.0
4 x 53940 5.73 1.12 0.0 4.71 5.68 6.54 10.74
5 y 53940 5.73 1.14 0.0 4.72 5.68 6.54 58.9
6 z 53940 3.54 0.71 0.0 2.91 3.51 4.04 31.81カラットより大きいレコードを選び出すには次のようにします。
diamonds.slice { carat > 1 }
=>
#<RedAmber::DataFrame : 17502 x 10 Vectors, 0x0000000000032c1c>
carat cut color clarity depth table price x ... z
<double> <string> <string> <string> <double> <double> <uint16> <double> ... <double>
0 1.17 Very Good J I1 60.2 61.0 2774 6.83 ... 4.13
1 1.01 Premium F I1 61.8 60.0 2781 6.39 ... 3.94
2 1.01 Fair E I1 64.5 58.0 2788 6.29 ... 4.03
3 1.01 Premium H SI2 62.7 59.0 2788 6.31 ... 3.93
4 1.05 Very Good J SI2 63.2 56.0 2789 6.49 ... 4.09
: : : : : : : : : ... :
17499 1.04 Very Good I I1 61.6 61.0 2745 6.45 ... 3.98
17500 1.04 Fair G SI2 65.2 57.0 2745 6.25 ... 4.07
17501 1.02 Good H I1 64.3 63.0 2751 6.28 ... 4.0217502行10列のデータフレームが得られました。
汎用的な書き方で書くと、
diamonds.slice(diamonds[:carat] > 1)となりますが、ブロックを使うと上のような書き方ができます。DRY的にこの方が良いですよね。
続けて cut と price の列だけを選び取ります。
diamonds
.slice { carat > 1 }
.pick(:cut, :price)
=>
#<RedAmber::DataFrame : 17502 x 2 Vectors, 0x0000000000035ad4>
cut price
<string> <uint16>
0 Very Good 2774
1 Premium 2781
2 Fair 2788
3 Premium 2788
4 Very Good 2789
: : :
17499 Very Good 2745
17500 Fair 2745
17501 Good 2751Ruby ではメソッドチェインでは右に続けて書けますが、インデントして1行ずつにした方が分かりやすいのでこのようにしています。
続けて cut の種類毎にグループ化します。
diamonds
.slice { carat > 1 }
.pick(:cut, :price)
.group(:cut)
=>
#<RedAmber::Group : 0x00000000000396ac>
cut group_count
<string> <uint16>
0 Very Good 3881
1 Premium 5729
2 Fair 651
3 Ideal 5662
4 Good 1579#group メソッドは指定したキーの列のデータでグループ化したオブジェクト(RedAmber::Group) を返します。グループに対する操作は続けて集約のメソッドを与えることで実現できます。ここでは平均を求める #mean を適用します。
diamonds
.slice { carat > 1 }
.pick(:cut, :price)
.group(:cut)
.mean
=>
#<RedAmber::DataFrame : 5 x 2 Vectors, 0x000000000003db44>
cut mean(price)
<string> <double>
0 Very Good 8340.55
1 Premium 8487.25
2 Fair 7177.86
3 Ideal 8674.23
4 Good 7753.6今度は DataFrame が返ってきて、cut の値ごとの price の平均値が求められています。
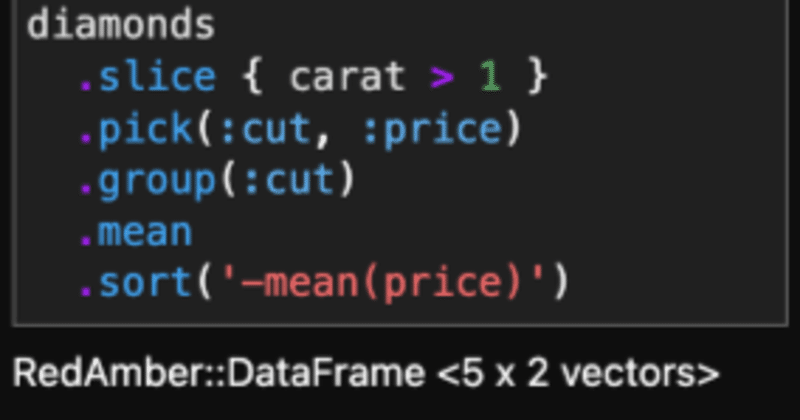
最後にソートして完成させましょう。ついでに結果を変数 df に入れておきます。
df = diamonds
.slice { carat > 1 }
.pick(:cut, :price)
.group(:cut)
.mean
.sort('-mean(price)')
=>
#<RedAmber::DataFrame : 5 x 2 Vectors, 0x00000000000435bc>
cut mean(price)
<string> <double>
0 Ideal 8674.23
1 Premium 8487.25
2 Very Good 8340.55
3 Good 7753.6
4 Fair 7177.86#sort の引数はキーの文字列表現を与えますが、頭に - を付けると降順にできます。
次に、得られたデータフレームのキー名を変更しましょう。キーの変更は#rename(元の名前, 新しい名前)でできます。 名前はシンボルで指定します。
df.rename(:'mean(price)', :mean_price_usd)
=>
#<RedAmber::DataFrame : 5 x 2 Vectors, 0x0000000000051c20>
cut mean_price_usd
<string> <double>
0 Ideal 8674.23
1 Premium 8487.25
2 Very Good 8340.55
3 Good 7753.6
4 Fair 7177.86 次に、今ある列の隣に新しい列を作りましょう。新しい列を作るには、#assign(キーの名前) { ベクトルの値 }と書きます。ここではドル円のレートを指定して円での価格を計算します。
usdjpy = 110.0
df.rename(:'mean(price)', :mean_price_usd)
.assign(:mean_price_jpy) { mean_price_usd * usdjpy }
=>
#<RedAmber::DataFrame : 5 x 3 Vectors, 0x000000000005765c>
cut mean_price_usd mean_price_jpy
<string> <double> <double>
0 Ideal 8674.23 954164.93
1 Premium 8487.25 933597.34
2 Very Good 8340.55 917460.37
3 Good 7753.6 852896.11
4 Fair 7177.86 789564.12今より円高ですが、このデータセットができた当時のドル円レートを調べて使いました。
starwarsデータの例
次にRed Datasetからstarwarsデータセットを読み込んで操作してみましょう。
今度は、csvファイルを直接ダウンロードして読み込んでみます。
uri = URI('https://vincentarelbundock.github.io/Rdatasets/csv/dplyr/starwars.csv')
starwars = DataFrame.load(uri)
=>
#<RedAmber::DataFrame : 87 x 12 Vectors, 0x000000000005a26c>
unnamed1 name height mass hair_color skin_color eye_color ... species
<int64> <string> <int64> <double> <string> <string> <string> ... <string>
0 1 Luke Skywalker 172 77.0 blond fair blue ... Human
1 2 C-3PO 167 75.0 NA gold yellow ... Droid
2 3 R2-D2 96 32.0 NA white, blue red ... Droid
3 4 Darth Vader 202 136.0 none white yellow ... Human
4 5 Leia Organa 150 49.0 brown light brown ... Human
: : : : : : : : ... :
84 85 BB8 (nil) (nil) none none black ... Droid
85 86 Captain Phasma (nil) (nil) unknown unknown unknown ... NA
86 87 Padmé Amidala 165 45.0 brown light brown ... Humanこのようにして URI オブジェクトから直接ダウンロードする事ができます。データの要約を調べると、
starwars.tdr(:all) # :allを指定すると全ての変数を表示する(既定値は10)
RedAmber::DataFrame : 87 x 12 Vectors
Vectors : 4 numeric, 8 strings
# key type level data_preview
0 :unnamed1 int64 87 [1, 2, 3, 4, 5, ... ]
1 :name string 87 ["Luke Skywalker", "C-3PO", "R2-D2", "Darth Vader", "Leia Organa", ... ]
2 :height int64 46 [172, 167, 96, 202, 150, ... ], 6 nils
3 :mass double 39 [77.0, 75.0, 32.0, 136.0, 49.0, ... ], 28 nils
4 :hair_color string 13 ["blond", "NA", "NA", "none", "brown", ... ]
5 :skin_color string 31 ["fair", "gold", "white, blue", "white", "light", ... ]
6 :eye_color string 15 ["blue", "yellow", "red", "yellow", "brown", ... ]
7 :birth_year double 37 [19.0, 112.0, 33.0, 41.9, 19.0, ... ], 44 nils
8 :sex string 5 {"male"=>60, "none"=>6, "female"=>16, "hermaphroditic"=>1, "NA"=>4}
9 :gender string 3 {"masculine"=>66, "feminine"=>17, "NA"=>4}
10 :homeworld string 49 ["Tatooine", "Tatooine", "Naboo", "Tatooine", "Alderaan", ... ]
11 :species string 38 ["Human", "Droid", "Droid", "Human", "Human", ... ]1列目は元のデータで列ラベルが空白文字となっているので、自動的に:unnamed1 という名前になっています。これを除去します。
starwars.drop(0) # drop(:unnamed1)でもOK
=>
#<RedAmber::DataFrame : 87 x 11 Vectors, 0x000000000005f3ac>
name height mass hair_color skin_color eye_color birth_year ... species
<string> <int64> <double> <string> <string> <string> <double> ... <string>
0 Luke Skywalker 172 77.0 blond fair blue 19.0 ... Human
1 C-3PO 167 75.0 NA gold yellow 112.0 ... Droid
2 R2-D2 96 32.0 NA white, blue red 33.0 ... Droid
3 Darth Vader 202 136.0 none white yellow 41.9 ... Human
4 Leia Organa 150 49.0 brown light brown 19.0 ... Human
: : : : : : : : ... :
84 BB8 (nil) (nil) none none black (nil) ... Droid
85 Captain Phasma (nil) (nil) unknown unknown unknown (nil) ... NA
86 Padmé Amidala 165 45.0 brown light brown 46.0 ... Human:species列にはいくつか"NA"が含まれています。これを含む列を取り除きます。
starwars
.drop(0)
.remove { species == 'NA' } # slice { species == 'NA' }の逆です
=>
#<RedAmber::DataFrame : 83 x 11 Vectors, 0x0000000000075c10>
name height mass hair_color skin_color eye_color birth_year ... species
<string> <int64> <double> <string> <string> <string> <double> ... <string>
0 Luke Skywalker 172 77.0 blond fair blue 19.0 ... Human
1 C-3PO 167 75.0 NA gold yellow 112.0 ... Droid
2 R2-D2 96 32.0 NA white, blue red 33.0 ... Droid
3 Darth Vader 202 136.0 none white yellow 41.9 ... Human
4 Leia Organa 150 49.0 brown light brown 19.0 ... Human
: : : : : : : : ... :
80 Poe Dameron (nil) (nil) brown light brown (nil) ... Human
81 BB8 (nil) (nil) none none black (nil) ... Droid
82 Padmé Amidala 165 45.0 brown light brown 46.0 ... Human:species でグループ化して、データ数, :height, :massの平均値を求めます。
starwars
.drop(0)
.remove { species == 'NA' }
.group(:species) { [count(:species), mean(:height, :mass)] }
=>
#<RedAmber::DataFrame : 37 x 4 Vectors, 0x000000000007efcc>
species count mean(height) mean(mass)
<string> <int64> <double> <double>
0 Human 35 176.65 82.78
1 Droid 6 131.2 69.75
2 Wookiee 2 231.0 124.0
3 Rodian 1 173.0 74.0
4 Hutt 1 175.0 1358.0
: : : : :
34 Kaleesh 1 216.0 159.0
35 Pau'an 1 206.0 80.0
36 Kel Dor 1 188.0 80.0countが1より大きいレコードを選んでみました。
starwars
.drop(0)
.remove { species == 'NA' }
.group(:species) { [count(:species), mean(:height, :mass)] }
.slice { count > 1 }
=>
#<RedAmber::DataFrame : 8 x 4 Vectors, 0x000000000008b808>
species count mean(height) mean(mass)
<string> <int64> <double> <double>
0 Human 35 176.65 82.78
1 Droid 6 131.2 69.75
2 Wookiee 2 231.0 124.0
3 Gungan 3 208.67 74.0
4 Zabrak 2 173.0 80.0
5 Twi'lek 2 179.0 55.0
6 Mirialan 2 168.0 53.1
7 Kaminoan 2 221.0 88.0この例はRの例を参考にしました。
ぜひ使ってみてください
Rubyらしい書き方でデータフレームの操作ができる事がわかっていただけたでしょうか?RedAmberはまだ開発途上ですが、主要な操作はできるようになっていると思いますので使ってみていただけると嬉しいです。
APIのドキュメントは未完成ですが、
DataFrame.md : DataFrameクラスの説明
Vector.md : Vectorクラスの説明
83 Examples of Red Amber (raw file) : Jupyter notebook形式のコード例
があるので参考にしてください。
私はずっとRubyを使う側でしたが、初めてRubyで作る側に回ってみて新しい発見がたくさんありました。Apache Arrowを中心としたデータ解析用ツールの世界はアイデア次第でいろいろな事ができる宝の山だと感じます。興味がある方はぜひRed Data Toolsにいらしてください!(コードを書くだけが開発ではないですし、現時点での能力の不足は問題ではないそうです。今年の春頃まで私もOSS初心者でした!)
質問、コメント等ございましたら、RedAmberのディスカッション(日本語でもOKです)または Red Data Toolsのgitter を使っていただければと思います。
この記事が気に入ったらサポートをしてみませんか?