
ChatGPT4:ノーコードでPythonデータ可視化 Pt.2

はじめに
Code interpreter が組み込まれたChatGPT4なら、データ可視化がノーコードで簡単にできます。
このnote📒で『ボストン住宅価格データセット』を題材にしたデータ可視化を行いましたが、すべてが数値で欠損値がないデータでしたので、前処理の必要はありませんでしたが、現実はなかなかそうはいきませんね。
この記事では、ChatGPT4でカテゴリーデータや欠損データが混在した(お馴染みの)『タイタニックデータセット』で、前処理とデータ可視化をしてみました。
タイタニックデータセットを可視化
『タイタニックデータセット』は、機械学習の分野で有名なデータセットです。
以下は、ChatGPTによるこのデータセットの解説です。
タイタニックデータセットは、1912年4月に起こったタイタニック号沈没事故の際の乗客と乗組員の情報を含む歴史的なデータセットです。このデータセットは、データ科学と機械学習の分野で非常に有名であり、しばしばデータ解析の入門や分類問題(特に二項分類)の例として使用されます。
タイタニックデータセットの主な特徴は以下の通りです:
1. 乗客情報 :
- PassengerId : 乗客のID番号。
- Survived : 乗客が生存したかどうかを示すフラグ(0 = 死亡、1 = 生存)。
- Pclass : 乗客の客室クラス(1 = 1等船室、2 = 2等船室、3 = 3等船室)。
- Name : 乗客の名前。
- Sex : 乗客の性別(男性、女性)。
- Age : 乗客の年齢。
- SibSp : タイタニック号に同乗している兄弟姉妹や配偶者の数。
- Parch : タイタニック号に同乗している親または子供の数。
- Ticket : チケット番号。
- Fare : 乗船運賃。
- Cabin : 客室番号。
- Embarked : 乗船した港(C = Cherbourg、Q = Queenstown、S = Southampton)。
2. データの特性 :
- このデータセットは、実際の歴史的事象に基づいており、欠損値や不完全な記録を含む可能性があります。
- 分析の際には、データの前処理、欠損値の処理、特徴量エンジニアリングが重要となります。
- 生存予測は、二項分類問題として扱われます。
3. 分析の応用 :
- タイタニックデータセットを用いた分析では、どのような特徴が生存率に影響を与えたかを探求します。
- 機械学習モデルを使用して、特定の乗客が事故で生き残る可能性を予測することが一般的な応用です。
タイタニックデータセットは、データ分析と機械学習の基礎を学ぶための非常に良い例であり、実際のデータに基づいた意思決定と予測モデリングの問題を理解するのに役立ちます。
タイタニックデータセットのダウンロード
データセットは、このサイトからダウンロードしました。
データ概要確認
まず、ChatGPTにデータセットをインプットして、データ概要を確認しました。指示は以下、生成結果は動画をみてください。
指示:このデータセットのデータ概要(先頭5行を表形式で示す)、全てのデータの型、全てのデータの基本統計量の値、欠損値の有無を示してください。
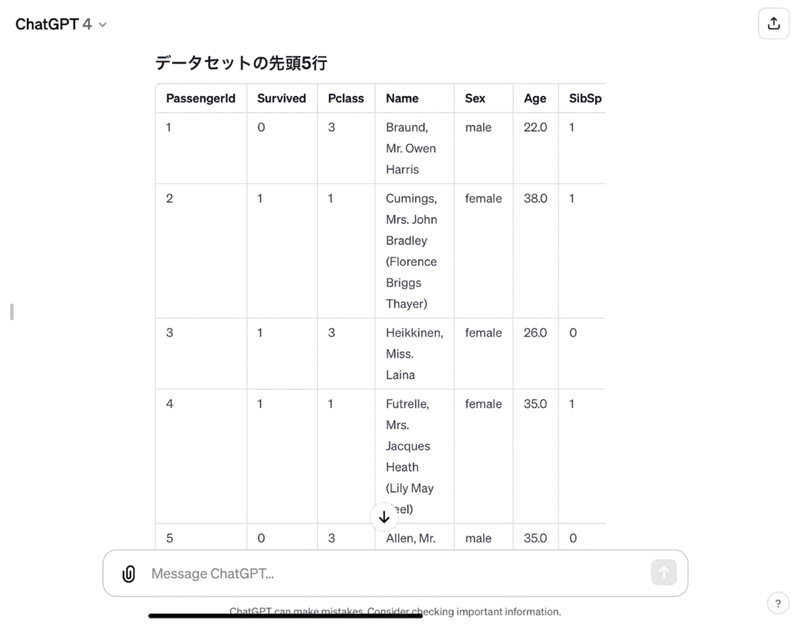
データセット「titanic.csv」の概要は以下の通りです:
### データセットの先頭5行
(上記参照)
### 全てのデータの型
- PassengerId: int64
- Survived: int64
- Pclass: int64
- Name: object
- Sex: object
- Age: float64
- SibSp: int64
- Parch: int64
- Ticket: object
- Fare: float64
- Cabin: object
- Embarked: object
### 全てのデータの基本統計量
- データ数: 891
- 生存者 (Survived): 平均約 38.4% (0 = 死亡, 1 = 生存)
- 客室等級 (Pclass): 平均約 2.3 (1 = 1等, 2 = 2等, 3 = 3等)
- 年齢 (Age): 平均約 29.7歳 (最小 0.42歳, 最大 80歳)
- 兄弟配偶者数 (SibSp): 平均約 0.52人
- 親子数 (Parch): 平均約 0.38人
- 運賃 (Fare): 平均約 32.2ポンド (最小 0ポンド, 最大 512.33ポンド)
- 最も多い乗船港 (Embarked): S (サウサンプトン)
### 欠損値の有無
- Age: 177件の欠損
- Cabin: 687件の欠損
- Embarked: 2件の欠損
データには特に年齢と客室番号に多くの欠損があります。これらの欠損値は分析やモデル構築において重要な考慮事項となります。
基本統計量は、全データの値を示してくれなかったので、以下の指示を追加しました。
指示:全てのデータの基本統計量を表形式で示してください。

この表には、各列に対する基本的な統計情報(合計、平均、標準偏差、最小値、最大値など)が含まれています。また、カテゴリー型のデータに対しては、一意の値の数、最も頻繁な値、その出現回数も示されています。
データ可視化1
カテゴリーデータがあり、欠損値も多いですが、まずはこのデータのまま可視化してみます。
指示:ペアプロットを描いてください。
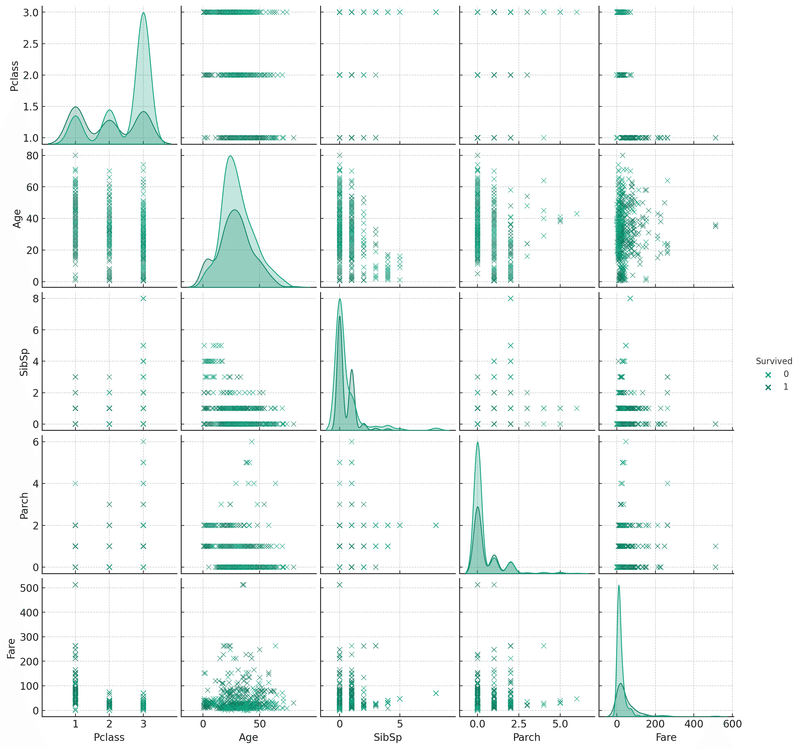
ペアプロットを描画しました。このプロットでは、タイタニックデータセットの数値型変数間の関係を可視化しています。各プロットは、特定の2つの変数の関係を示しており、生存状態(Survived)に基づいて色分けされています。これにより、生存者と非生存者の間でこれらの変数がどのように異なるかを理解するのに役立ちます。
ラベルエンコーディング(文字データを数値に変換)
あたり前ですが、数値データしか可視化されませんので、カテゴリーデータを0,1…に変換してみます。
まずはSex列。もう一度、欠損値の有無を確認してから進めます。
指示:Sex列に欠損値があるかを確認してください。
`Sex` 列に欠損値はありません。すべてのレコードに性別のデータが含まれています。
指示:Sex列をラベルエンコードしてください
`Sex` 列のラベルエンコーディングが完了しました。エンコーディングされた値は新しい列 `Sex_encoded` に追加されています。ここで、`male` は 1 に、`female` は 0 に変換されています。データセットの最初の5行は以下の通りです:

元の列を残したまま、エンコーディングされた列が追加されました。
わかりやすい❗️いいですね。
次はEmbarked列。もう一度、欠損値の有無を確認してから進めます。
指示:Embarkedに欠損値はありますか?
`Embarked` 列には2件の欠損値があります。
エンコーディングにより欠損値も数値化するとややこしいので、以下を指示しました。
指示:Embarkedをラベルエンコードしてください。欠損値は無視してください。
`Embarked` 列のラベルエンコーディングが完了しました。エンコーディングされた値は新しい列 `Embarked_encoded` に追加されています。欠損値は無視され、残りの値がエンコードされています。データセットの最初の5行は以下の通りです:(以下省略)
データ可視化2
エンコーディングできましたので、もう一度ペアプロットを描いてみます。
指示:ペアプロットを描いてください。
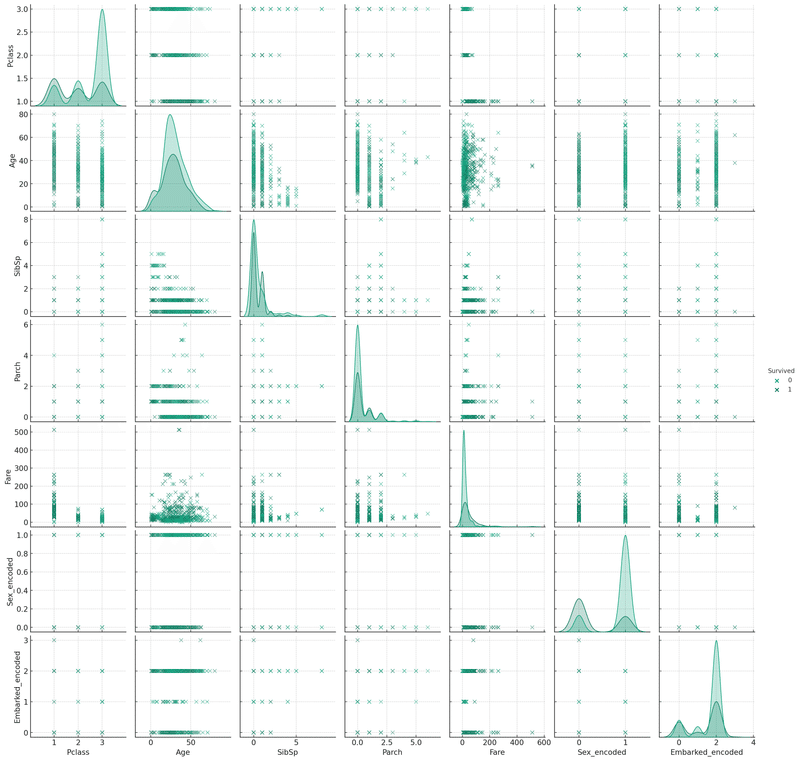
ペアプロットを描画しました。このプロットでは、更新されたタイタニックデータセットの数値型変数(ラベルエンコードされた `Sex` と `Embarked` を含む)間の関係が可視化されています。各プロットは特定の2つの変数の関係を示しており、生存状態(Survived)に基づいて色分けされています。これにより、生存者と非生存者の間でこれらの変数がどのように異なるかを理解するのに役立ちます。
指示:Survivedの色の違いがわかりにくいなぁ。色を変えてください。

ペアプロットの色を変更しました。このプロットでは、`Set1` のカラーパレットを使用して、生存者と非生存者をよりはっきりと区別できるようにしています。この変更により、生存状態(Survived)に基づいて色分けされた各変数の関係がより明確に見えるはずです。
指示:相関係数行列を描いてください。

相関係数行列を描画しました。このヒートマップは、データセット内の各数値変数間の相関関係を示しています。相関係数は -1 から +1 の範囲で、+1 は完全な正の相関、-1 は完全な負の相関を表します。0 は相関がないことを意味します。このマトリックスは、特定の変数間の関連性を理解するのに役立ちます。
次に、
まずひとつのグラフを描いてから、追加指示を繰り返してグラフを拡張してみます。
指示:AgeとSexの散布図をfacetを駆使して描いてください。

指示:Survivedも表現してください。

指示:Pcclassもfacetに追加できますか?

指示:y軸はfareにしてください。

`Age`, `Fare`, `Sex`, `Pclass` および `Survived` の散布図を描画しました。このグラフでは、`Sex`(男性と女性)と `Pclass`(1, 2, 3等船室)ごとに異なるグラフが作成され、各点は `Survived` の状態によって色分けされています(`Set1` カラーパレット使用)。y軸は `Fare` で、x軸は `Age` です。このグラフを通して、年齢、運賃、性別、船室クラス、生存状態の関係を視覚的に確認することができます。
データ考察
指示:この可視化は、タイタニックの惨事を物語っていると思います。 どのような方が生き延びる、どのような方が亡くなったか、このような傾向に至ったのは何が重視されたのかを想定して回答してください。
この可視化から、タイタニックの惨事に関するいくつかの傾向が読み取れます。生存者と非生存者の違いに影響を与えた主な要因を以下に挙げます:
1. 性別 :女性の生存率が男性よりも高いことが観察されます。当時の「女性と子供を先に」という救命ボートの方針がこれに影響を与えた可能性があります。
2. 客室クラス(Pclass) :より高いクラス(特に1等船室)の乗客の生存率が高いことが見られます。これは、高いクラスの乗客がより良い設備へのアクセスや救命ボートへの近さなど、より良い生存機会を持っていたことを示しています。
3. 年齢 :若い乗客、特に子供たちの生存率が高い傾向にあります。これも「女性と子供を先に」の方針によるものと考えられます。
4. 運賃(Fare) :運賃が高い乗客(おそらくより高い客室クラス)の生存率が高いことが観察されます。これは、客室クラスと生存率の関連性をさらに裏付けるものです。
これらの観察結果から、タイタニックの惨事において生存率に影響を与えた要因は、性別、年齢、客室クラス、および経済的地位(運賃を通して反映)であったと考えられます。これらの要因は、当時の社会的・文化的規範や、救命ボートへのアクセスの違いなどにより、生存の可能性に大きな違いを生じさせたと推測されます。
指示:経済的地位の低い男性であるほど、紳士的であったとも考えられませんか?
経済的地位の低い男性の低い生存率を、「紳士的な行動」と解釈することは一つの見方です。タイタニック号の悲劇では、多くの乗客が「女性と子供を先に」という当時の社会規範や紳士道に従って行動しました。この規範は、特に救命ボートの席が限られている状況下で、女性や子供を優先することを意味していました。
経済的地位が低い男性、特に3等船室の乗客は、救命ボートへのアクセスが限られていたため、生存率が低かったとされています。彼らがこの状況で「紳士的」に行動したとすれば、それは彼らが他の乗客、特に女性や子供を先に救命ボートに乗せるために自分たちの生存の機会を犠牲にしたことを意味するかもしれません。
このような行動は、当時の文化的な価値観や倫理観に根ざしており、社会的な期待や役割に大きく影響されていました。しかし、これらの行動が完全に自発的であったか、あるいは状況や制約によって強いられたものであったかは、個々の乗客の状況や選択によって異なります。したがって、一概にすべての低い経済状態の男性が紳士的であったと断言することは難しいですが、多くの場合、そうであった可能性は高いと考えられます。
最後に
裏でPythonが走っていますので、「前処理できる」のは、当たり前といえば当たり前ですが、Pythonでやるのは結構な手間なので、これは助かりますね❗️
データを見ながら、口頭(テキスト)指示で、前処理や探索的な可視化を進めることができるのはいい‼️(メッチャ楽😊)
コードは知らなくてもできますが、Pythonで何ができるか?、どんな可視化ができるか?を知っているほど、ChatGPTとのやり取りはスムーズになるなと思いますので、よく利用するライブラリは(たまには)チェックしておこうかな。
補足1:欠損値の補完
指示:欠損値を補完する方法を示して
タイタニックデータセットにおける欠損値の補完には、いくつかの方法があります。主に扱うべき欠損値は「Age」、「Cabin」、「Embarked」の列に存在します。各列に適した補完方法は次のとおりです:
1. Age(年齢) :
- 平均値または中央値での補完 :年齢の欠損値をデータセットの年齢の平均値または中央値で置き換える。
- 他の変数からの推測 :例えば、乗客の称号(Mr、Mrs、Missなど)や他の変数から年齢を推測し、その平均値や中央値で補完する。
2. Cabin(客室番号) :
- 特定の値での補完 :多くの場合、客室番号のデータが不足しているため、これを 'Unknown' などの特定の値で置き換える。
- 乗客のクラスに基づく補完 :1等船室、2等船室、3等船室の乗客ごとに異なる値を割り当てる。
3. Embarked(乗船した港) :
- 最も一般的な値での補完 :この列の欠損値は非常に少ないため、最も一般的な値(最頻値)で補完する。
- 他の変数からの推測 :乗客の運賃やクラスから、乗船した可能性の高い港を推測し、それに基づいて補完する。
これらの方法は、分析の目的やデータの特性に応じて選択します。欠損値を補完する際には、データの分布や関連性を考慮し、分析結果に偏りが生じないように注意することが重要です。また、補完後は、補完が分析結果にどのような影響を与えるかを評価することも重要です。
指示:乗客の称号(Mr、Mrs、Missなど)や他の変数から年齢を推測し、中央値で補完する。
乗客の称号や他の変数を使用して年齢の欠損値を推測し、中央値で補完する方法は以下の手順で行います:
1. 乗客の称号を抽出 :まず、乗客の名前から称号(Mr、Mrs、Miss、Masterなど)を抽出します。これは通常、名前の中の最初のカンマの後と次のドットの間にあります。
2. 称号ごとの年齢の中央値を計算 :各称号について、そのグループの年齢の中央値を計算します。
3. 欠損値の補完 :欠損している年齢データに対して、該当する乗客の称号に基づいた年齢の中央値を使用して補完します。
4. データの確認 :補完後のデータを確認して、適切に補完されていることを確認します。
この手法を実装して、タイタニックデータセットの年齢の欠損値を補完してみましょう。
年齢の欠損値を、乗客の称号に基づいた年齢の中央値で補完しました。この処理により、`Age` 列のすべての欠損値が埋められ、データセットに年齢の欠損値は存在しなくなりました。データセットの最初の5行を確認すると、`Age` 列に補完された値が反映されていることがわかります。
(省略)
この方法により、称号を考慮して年齢の欠損値をより現実的に補完することができました。
補足2:前処理を提案してもらう
指示:このデータセットに前処理を施したい。前処理内容を提案してください。
データセットの前処理について提案をする前に、まずはデータセットの内容を確認しましょう。アップロードされた「titanic.csv」ファイルを読み込んで、その概要を把握します。その後、データの特徴に基づいた前処理の提案を行います。ファイルを読み込んで内容を確認しますね。
「titanic.csv」データセットには、タイタニック号の乗客に関するさまざまな情報が含まれています。データのカラムは以下の通りです:
1. `PassengerId`: 乗客のID
2. `Survived`: 生存状態(0 = 死亡、1 = 生存)
3. `Pclass`: チケットクラス(1, 2, 3)
4. `Name`: 乗客の名前
5. `Sex`: 性別
6. `Age`: 年齢
7. `SibSp`: タイタニック号に同乗している兄弟姉妹/配偶者の数
8. `Parch`: タイタニック号に同乗している親/子供の数
9. `Ticket`: チケット番号
10. `Fare`: 乗船運賃
11. `Cabin`: 客室番号
12. `Embarked`: 乗船した港(C = Cherbourg, Q = Queenstown, S = Southampton)
このデータセットに対する前処理の提案は以下の通りです:
1. 欠損値の処理 :
- `Age`, `Cabin`, `Embarked` などの欠損値を持つカラムを特定し、適切に処理する(例:平均値または中央値で埋める、または欠損データ行を削除する)。
2. カテゴリカルデータのエンコーディング :
- `Sex`, `Embarked` などのカテゴリカル変数を数値に変換する(例:ワンホットエンコーディングやラベルエンコーディングを使用)。
3. 不要なカラムの削除 :
- モデル構築に不要な情報を含むカラム(例:`Name`, `Ticket`)を削除する。
4. 特徴量のスケーリング :
- `Age`, `Fare` などの数値データに対して標準化または正規化を行う。
5. 新たな特徴量の作成 :
- 既存のデータから新しい意味のある特徴量を作成する(例:`SibSp` と `Parch` を合わせて家族の総数を示す特徴量を作成)。
これらの提案は、データの特性と分析の目的に応じて調整することが可能です。特定の分析目的やモデルに基づいて、より具体的な前処理のアプローチを検討することも重要です。
ChatGPTはタイタニックデータのことも学習しているから、知ってることを答えてる可能性もありますが、「〇〇して」だけで実行できるのは。。。ありがたい😭。
Rのggplot2にせよ、Pyhtonのseabornにせよ、どのような図を描けるのか知っておくの大事🍀
— さくら🌸医療統計・データサイエンス (@Sakura_Med_DSci) August 26, 2021
知らない事は思いつきもしないので😉
correlogram知らない人はそれが有効な場面でも思いつけないのです!
Graph Galleryを眺めよう🌈
Python: https://t.co/oNE3iz0HqY
R: https://t.co/OrpcuMGje8#忘備録
よろしければサポートお願いします!