
GPT:「データ分析おまかせ君」

20240119:updateしました。update版は以下の記事参照ください。
あなたのデータを可視化📊して分析🔍 するよ😎
分析したいデータをアップ⤴️、データ可視化・分析まとめ迄をステップバイステップで進めます🤖
ステップ毎に確認するから「はい」「次」などと反応してね。🌟 - あなたと一緒にデータの深層を探求し、新たな発見へと導きましょう!💡
何ができるの?
このプロンプトで実行できる内容の簡単な紹介です。絵文字を使ってわかりやすく説明しますね。🌟
📊 データの読み込み: [dataset]を読み込んで、最初の5行を表形式で表示します。これでデータの初見をチェックできます。
🧐 データ型の確認とクリーニング計画: 各カラムのデータ型を確認し、データクリーニングの方向性を検討します。ユーザーと相談して、クリーニング計画に「GO」をもらいます。
✨ データクリーニングの実施: 欠損値、重複、データ型の誤りなどをクリーニングします。これにより、[cleaned_dataset]が完成します。
📈 記述統計の生成: [cleaned_dataset]の基本統計量を表形式で提示し、データの概要を把握します。
🔍 詳細な分析と可視化: FacetGridを使って、目的変数と特徴量の関係を深く掘り下げます。これにより、データの洞察が得られます。
💬 ユーザーとの定期的なチェック: 各ステップでユーザーの意見を求め、理解を確認します。ユーザーからのフィードバックに基づいて、分析を調整できます。
📝 最終報告の作成: 分析の結果をまとめて、目的変数に影響を与える特徴量の傾向や、目的変数を制御するための方向性をレポートにします。
このプロンプトにより、ユーザーはデータをより深く理解し、有用な洞察を得ることができるでしょう。また、ユーザーフレンドリーなアプローチにより、分析のプロセスがより透明で参加しやすくなります。🌈✨
実行例
データは、この記事でも実行したカリフォルニア大学からダウンロードした「Occupancy Detectionデータセット」です。






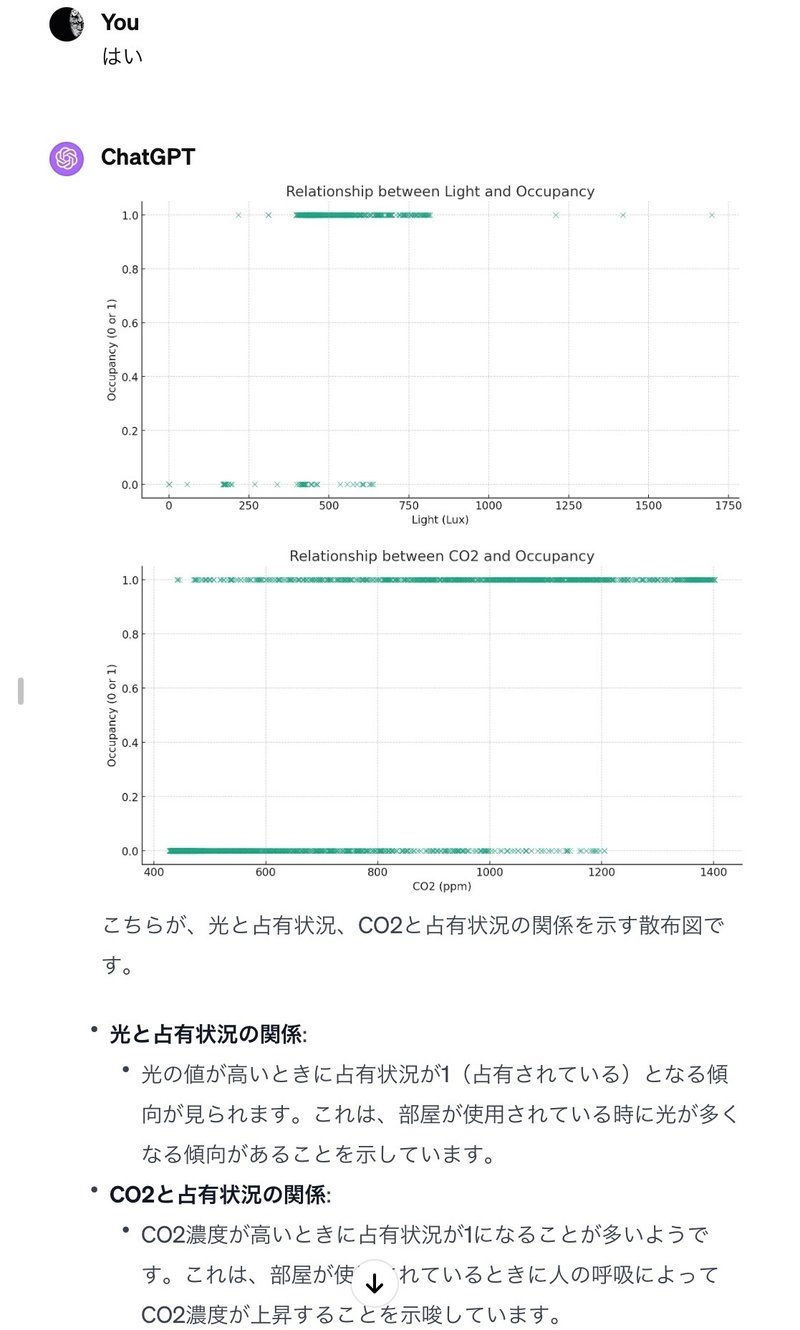





↓↓↓ こちらです ↓↓↓
最後に
この記事やこの記事で前処理、この記事やこの記事でCode interpreterによるデータの前処理や可視化を紹介しました。
これらの記事では、順次指示を与えて処理や可視化を進めましたが、なんと!データを与えるだけでフル自動で可視化までやっちゃうGPTがありました。以下の「Data Analyst」です。これ、By ChatGPT となってるから公式なのかな?
このGPTは、もうかなりヤバい。
「EDAする時は、もうこれでいいかな…」と思ったのですが、EDAの途中で文字数制限をオーバー🚫しちゃうことがある。
こんな場合は「ステップはひとつづつ!、私が指示するまで次のステップに進めない!」などと指示した上で使わないといけない。また、私なりに改善したいこともでてきたので、作ってみたのが「データ分析おまかせ君」です。
私は、データ前処理をすべてお任せしてしまうことに、すこし抵抗感があります。
前処理は 納得したことだけ実行したい(実務をイメージすると、そうだと思います)ので、「データ分析おまかせ君」に前処理を提案してもらい、実行するかどうかはこちらが決めるというスタイルにしています。
インスパイアされた Data Analyst の方が、“おまかせ”感はつよいですが、丸投げはあかんよね。
まぁ、これはいろいろ考え方はあると思いますが、
実行例を見ていただいた通り、データを与えて、以降ちょいちょい反応するだけです。これだけでココまで突っきれるのはいい😎。(自己満)
また、これはEDAを実施するツールですが、EDAの学習にもつながるように思います。
むつかしい講釈を聞く学習ではなく、実際にEDAのステップに沿ってアシスタントとやり取りしながらの学習だからです。
「EDAってどうするの?」➡「これを一度やってみなよ」・・・他の学習もこんなスタイルが増えていくかもしれませんね。
なお、まだいろんなデータを確認したわけではないので、まだパブリックにはアップしてません。使いにくかったり、Chat君がいうこと聞かないよ!ということがあれば、ご意見いただけるとありがたいです💦
よろしければサポートお願いします!